
Neo4j: Finding the longest path
One on my favourite things about storing data in a graph database is executing path based queries against that data. I’ve been trying to find a way to write such queries against the Australian Open QuickGraph, and in this blog post we’re going to write what I think of as longest path queries against this graph.

Setting up Neo4j
We’re going to use the following Docker Compose configuration in this blog post:
version: '3.7'
services:
neo4j:
image: neo4j:4.0.0-enterprise
container_name: "quickgraph-aus-open"
volumes:
- ./plugins:/plugins
- ./data:/data
- ./import:/var/lib/neo4j/import
ports:
- "7474:7474"
- "7687:7687"
environment:
- "NEO4J_ACCEPT_LICENSE_AGREEMENT=yes"
- "NEO4J_AUTH=neo4j/neo"
- NEO4J_apoc_import_file_use__neo4j__config=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_export_file_enabled=true
- NEO4JLABS_PLUGINS=["apoc"]Once we’ve created that file we need to open a terminal session where that file lives and then run docker-compose up to launch Neo4j.
Importing our dataset
We’re going to learn how to write longest path queries using a dataset that contains the finalists of the Australian Open tennis tournament.
:use system;
CREATE DATABASE blog;
:use blogCALL apoc.load.json("https://github.com/mneedham/australian-open-neo4j/raw/master/blog_data/tournaments.json")
YIELD value
CALL apoc.merge.node(value.t1.labels, value.t1.properties) YIELD node AS t1
CALL apoc.merge.node(value.t2.labels, value.t2.properties) YIELD node AS t2
CALL apoc.merge.relationship(t1, value.rel.label, {}, {}, t2, {}) YIELD rel
RETURN count(*);CALL apoc.load.json("https://github.com/mneedham/australian-open-neo4j/raw/master/blog_data/finalists.json")
YIELD value
CALL apoc.merge.node(value.winner.labels, value.winner.properties) YIELD node AS winner
CALL apoc.merge.node(value.loser.labels, value.loser.properties) YIELD node AS loser
CALL apoc.merge.node(value.match.labels, value.match.properties) YIELD node AS match
CALL apoc.merge.node(value.t.labels, value.t.properties) YIELD node AS tournament
CALL apoc.merge.relationship(winner, value.winnerRel.label, {}, {}, match, {}) YIELD rel AS winnerRel
CALL apoc.merge.relationship(loser, value.loserRel.label, {}, {}, match, {}) YIELD rel AS loserRel
CALL apoc.merge.relationship(match, value.tournRel.label, {}, {}, tournament, {}) YIELD rel AS tournRel
return count(*);We can see the imported graph in the Neo4j Browser visualisation below:
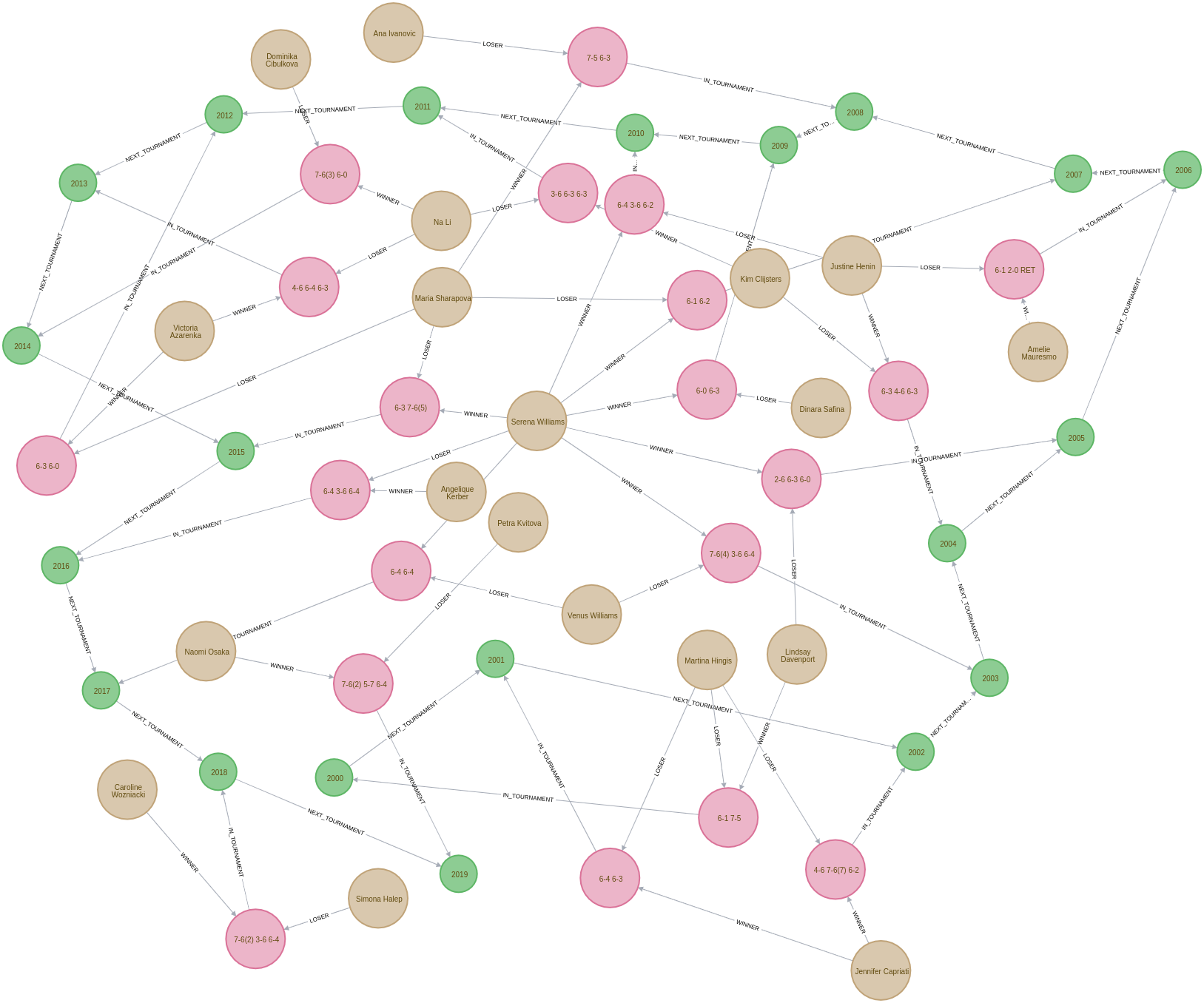
Finding longest paths
Let’s start with a variable length path query that starts with the Tournament in the year 2000 and follows the NEXT_TOURNAMENT relationship as many times as possible by using the * syntax after the relationship type:
MATCH path = (:Tournament {year: 2000})-[:NEXT_TOURNAMENT*]->(next)
RETURN [t in nodes(path) | t.year] AS allTournamentsIf we run this query, we’ll see the following output:
| allTournaments |
|---|
[2000, 2001] |
[2000, 2001, 2002] |
[2000, 2001, 2002, 2003] |
[2000, 2001, 2002, 2003, 2004] |
[2000, 2001, 2002, 2003, 2004, 2005] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018] |
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019] |
As we can see from the results, we’ve returned all the intermediate paths between the tournament in the year 2000 and the one in the year 2019.
But what if we only want to return the longest path? i.e the last one in the above results table.
We can tweak our query to do this by adding a WHERE clause that filters out any paths where the last node in that path has a NEXT_TOURNAMENT relationship.
The following query does this:
MATCH path = (:Tournament {year: 2000})-[:NEXT_TOURNAMENT*]->(next)
WHERE not((next)-[:NEXT_TOURNAMENT]->())
RETURN [t in nodes(path) | t.year] AS allTournamentsAnd if we run that query, we only get one row back, as expected:
| allTournaments |
|---|
[2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019] |
Now let’s see how we can use this technique for a more complex query.
We want to find which players have lost multiple finals in a row.
So we need to find all the Match nodes that have round "F" where the Player has a LOSER relationship to that match.
And we then want to see if that same player had a LOSER relationship to the final match in tournaments in the following years.
The following query is our first attempt to do this:
// Find losing finalists in a tournament and a path of all the tournaments
// after that tournament
MATCH path = (t:Tournament)-[:NEXT_TOURNAMENT*]->(t2:Tournament),
(t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player)
// Check that the player lost the final in every subsequent tournament
WITH nodes(path) AS tournaments, player
WHERE all(t in tournaments[1..]
WHERE (t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player)
)
RETURN player.name, [t IN tournaments | t.year] AS yearsIf we run this query, we’ll see the following results:
| player.name | years |
|---|---|
"Martina Hingis" |
[2000, 2001] |
"Martina Hingis" |
[2000, 2001, 2002] |
"Martina Hingis" |
[2001, 2002] |
Poor Martina Hingis!
But despite telling us all the finals that Martina lost, we’re still returning some rows that we want to exclude.
Ideally we only want to return the longest path, which contains [2000,2001,2002].
We need to update our query to filter out any paths where the losing finalist didn’t lose the final the year before
// Find losing finalists in a tournament and a path of all the tournaments
// after that tournament
MATCH path = (t:Tournament)-[:NEXT_TOURNAMENT*]->(t2:Tournament),
(t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player)
// Get the first and last tournaments in the list
WITH nodes(path) AS tournaments, player
WITH tournaments, tournaments[0] AS first, tournaments[-1] AS last, player
// Get the tournament that happened immediately before the first one in the list and
// the tournament that happened immediately after the last one in the list
WITH tournaments, player,
[(last)-[:NEXT_TOURNAMENT]->(next) | next][0] AS next,
[(previous)-[:NEXT_TOURNAMENT]->(first) | previous][0] AS previous
// Check that the player lost the final in every subsequent tournament and
// that the player lost the final in the tournament immediately before and
// that the player lost the final in the tournament immediately after
WHERE all(t in tournaments[1..]
WHERE (t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player)
AND not((next)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player))
AND not((previous)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[:LOSER]-(player))
)
RETURN player.name, [t IN tournaments | t.year] AS years;If we run this query, we’ll see the following results:
| player.name | years |
|---|---|
"Martina Hingis" |
[2000, 2001, 2002] |
Perfect, that’s exactly what we want the results to look like! We can now extend this query to find the players who reached consecutive finals:
// Find finalists in a tournament and a path of all the tournaments
// after that tournament
MATCH path = (t:Tournament)-[:NEXT_TOURNAMENT*]->(t2:Tournament),
(t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<--(player)
// Get the first and last tournaments in the list
WITH nodes(path) AS tournaments, player
WITH tournaments, tournaments[0] AS first, tournaments[-1] AS last, player
// Get the tournament that happened immediately before the first one in the list and
// the tournament that happened immediately after the last one in the list
WITH tournaments, player,
[(last)-[:NEXT_TOURNAMENT]->(next) | next][0] AS next,
[(previous)-[:NEXT_TOURNAMENT]->(first) | previous][0] AS previous
// Check that the player reached the final in every subsequent tournament and
// that the player reached the final in the tournament immediately before and
// that the player reached the final in the tournament immediately after
WHERE all(t in tournaments[1..]
WHERE (t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<--(player)
AND not((next)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<--(player))
AND not((previous)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<--(player))
)
RETURN player.name,
// Create a list containing the year of the final and the relationship type from the
// player to the final match in that tournament
apoc.coll.flatten(
[t IN tournaments | [(t)<-[:IN_TOURNAMENT]-(:Match {round: "F"})<-[type]-(player) |
[t.year, type(type)]][0]]
) AS years
ORDER BY years[0]If we run that query, we’ll see the following results:
| player.name | years |
|---|---|
"Martina Hingis" |
[2000, "LOSER", 2001, "LOSER", 2002, "LOSER"] |
"Jennifer Capriati" |
[2001, "WINNER", 2002, "WINNER"] |
"Maria Sharapova" |
[2007, "LOSER", 2008, "WINNER"] |
"Serena Williams" |
[2009, "WINNER", 2010, "WINNER"] |
"Victoria Azarenka" |
[2012, "WINNER", 2013, "WINNER"] |
"Na Li" |
[2013, "LOSER", 2014, "WINNER"] |
"Serena Williams" |
[2015, "WINNER", 2016, "LOSER", 2017, "WINNER"] |
There are a lot more players who reached multiple finals, but noone won more than 2 finals in a row. I was expecting to see more dominance by a single player!
It would be interesting to run a similar query that looked at the finalists of all Grand Slam tournaments and not sure just consecutive Australian Opens. Perhaps that can be the topic of another blog post.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.