
An intro to rerankers
rerankers provides a unified API for various reranking models, including any that use transformers, FlashRank, RankGPT, RankLLM, and more. In this blog, we’ll take it for a spin.
|
I’ve created a video showing how to do this on my YouTube channel, Learn Data with Mark, so if you prefer to consume content through that medium, I’ve embedded it below: |
But first, let’s remind ourselves what reranking is. A basic RAG pipeline would look like this:

In other words, we find relevant documents from a database usually using semantic/vector search, and then we include those documents in the prompt sent to an LLM. Reranking adds in an extra step, such that we retrieve more documents than we need from the database, ask a reranker to sort those documents, and then include the top <n> in the prompt sent to an LLM.
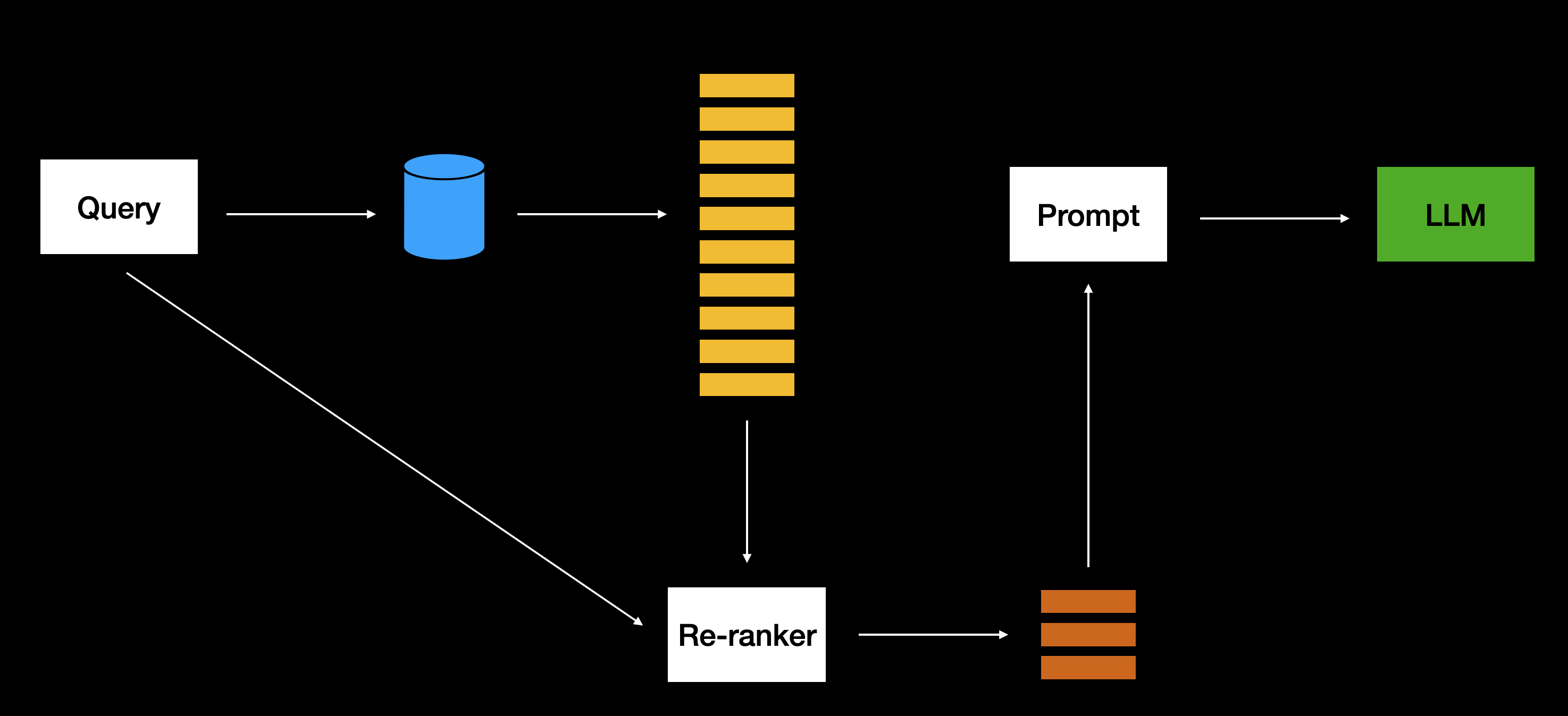
Let’s see how to do this with rerankers.
Installing rerankers
I’m going to use one of the Mixed Bread reranker models, which are available on Hugging Face and therefore via the transformers library. We can install rerankers with transformers dependencies like this:
pip install "rerankers[transformers]" torchA re-ranking Hello World
Let’s import the library:
from rerankers import RerankerAnd initialise a model:
ranker = Reranker(
model_name='mixedbread-ai/mxbai-rerank-large-v1',
model_type='cross-encoder',
device='mps'
)Loading TransformerRanker model mixedbread-ai/mxbai-rerank-large-v1
No dtype set
Using dtype torch.float16
Loaded model mixedbread-ai/mxbai-rerank-large-v1
Using device mps.
Using dtype torch.float16.Let’s now give it a try on a simple example.
Our search term is I love you and we’ll rank a series of documents that have varying similarity to that phrase:
sorted_rows = ranker.rank(
query="I love you",
docs=["I hate you", "I really like you", "You're not too bad"],
doc_ids=[0,1,2]
)RankedResults(
results=[
Result(document=Document(text='I really like you', doc_id=1, metadata={}), score=-1.5400390625, rank=1),
Result(document=Document(text="You're not too bad", doc_id=2, metadata={}), score=-2.8828125, rank=2),
Result(document=Document(text='I hate you', doc_id=0, metadata={}), score=-4.30859375, rank=3)
],
query='I love you',
has_scores=True
)That looks good - it’s the same order I would have come up with!
Re-ranking the Olympics opening ceremony
I’ve been playing around for a while now with a little dataset that I created from a BBC article about the Olympics Opening ceremony. One of the questions that I’ve so far been unable to correctly answer with vector search, full-text search, and hybrid search, is 'What went wrong?'. I want it to identify the arson attacks the night before the ceremony and Zidane’s metro train breaking down. Let’s see if we can do it!
We’ll initialise a connection to our DuckDB database
import duckdb
con = duckdb.connect("olympics.duckdb")|
You can download the database from the mneedham/LearnDataWithMark GitHub repository. |
Let’s take a quick look at some of the data:
con.query("FROM olympics SELECT index, text").limit(10)┌───────┬──────────────────────────────────────────────────────────────────────┐
│ index │ text │
│ int64 │ varchar │
├───────┼──────────────────────────────────────────────────────────────────────┤
│ 0 │ The 2024 Olympics opened in Paris in spectacular style with thousa… │
│ 1 │ Swapping a stadium for a waterway for the first time to open the "… │
│ 2 │ Blue, white and red fireworks had raised the Tricolore above Auste… │
│ 3 │ There were surprise performances through the ceremony, including a… │
│ 4 │ The day had started with major disruption when the French train ne… │
│ 5 │ The lashing rain may have forced athletes to add rain ponchos and … │
│ 6 │ The last two boats to parade - first the US as the next hosts for … │
│ 7 │ Rower Helen Glover and diver Tom Daley were Great Britain's flagbe… │
│ 8 │ In opening the 33rd summer Olympics, which are taking part against… │
│ 9 │ More than 10,500 athletes will compete across 32 sports at the Gam… │
├───────┴──────────────────────────────────────────────────────────────────────┤
│ 10 rows 2 columns │
└──────────────────────────────────────────────────────────────────────────────┘And now for the query!
I’ve created a Search[https://github.com/mneedham/LearnDataWithMark/blob/main/rerankers-playground/search.py^] class that runs a vector search query to find the most similar text to a given query.
from search import Search
s = Search(con)
question = "What things went wrong?"
rows = s.vector_search(question, limit=10).fetchall()[
(
'Given the miserable weather after what had been a sunny week in Paris until now, it seemed fitting that the storyline at the start of the ceremony was about the arrival of the Olympic flame in Paris not going according to plan.',
15,
0.5197256207466125
),
(
'A lot of the time it was brilliantly frenetic and occasionally emotional. ',
14,
0.4570101201534271
),
(
"At times it was bizarre - one moment Lady Gaga surrounded by pink and black feathers was singing in French, the next Bangladesh's athletes were being introduced on their boat. ",
13,
0.45612600445747375
),
(
"The torchbearer did not get the memo about it not being in the Stade de France, and then Zinedine Zidane's metro train broke down while he was transporting the torch.",
16,
0.44767796993255615
),
(
'The day had started with major disruption when the French train network was hit by arson attacks and heavy rain in the evening put paid to the original plan by artistic director Thomas Jolly to use the Parisian sun to "make the water sparkle". ',
4,
0.4340539574623108
),
(
'Since the last Olympics - the Beijing 2022 Winter Games - wars have started in Ukraine and Gaza.',
26,
0.4187776744365692
),
(
"One segment focused on rebuilding Notre Dame, which was damaged in a fire in 2019. A large troupe of dancers were accompanied by music composed using sounds captured from the iconic cathedral's reconstruction.",
19,
0.4176999628543854
),
(
'When organisers first revealed plans to hold the opening ceremony along the river in the heart of the city, rather than in a stadium as is usual, there were some raised eyebrows and questions over how they would manage such a huge security operation.',
10,
0.40121984481811523
),
(
'More than 100 heads of state and government were in attendance, including Prime Minister Sir Keir Starmer and French President Emmanuel Macron.',
32,
0.3883416950702667
),
(
'The impact of conflicts is being felt at these Olympics, with Russians and Belarusians banned following the Russian invasion of Ukraine. Just 15 Russian and 17 Belarusian athletes will be competing as Individual Neutral Athletes (AIN) in Paris and they were not part of the parade at the opening ceremony.',
30,
0.38072651624679565
)
]The rows that I want are down in positions 4 and 5. I usually return just the first 3 results, so those ones would be excluded.
Let’s see if the re-ranker can help us out:
sorted_rows = ranker.rank(
query=question,
docs=[r[0] for r in rows],
doc_ids=[r[1] for r in rows]
)
sorted_rows.top_k(3)[
Result(
document=Document(
text='The day had started with major disruption when the French train network was hit by arson attacks and heavy rain in the evening put paid to the original plan by artistic director Thomas Jolly to use the Parisian sun to "make the water sparkle". ',
doc_id=4,
metadata={}
),
score=0.0321044921875,
rank=1
),
Result(
document=Document(
text="The torchbearer did not get the memo about it not being in the Stade de France, and then Zinedine Zidane's metro train broke down while he was transporting the torch.",
doc_id=16,
metadata={}
),
score=-0.12066650390625,
rank=2
),
Result(
document=Document(
text='Given the miserable weather after what had been a sunny week in Paris until now, it seemed fitting that the storyline at the start of the ceremony was about the arrival of the Olympic flame in Paris not going according to plan.',
doc_id=15,
metadata={}
),
score=-0.9423828125,
rank=3
)
]It can indeed!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.