
Clustering YouTube comments using Ollama Embeddings
One of my favourite tools in the LLM space is Ollama and if you want to learn how to use it, there’s no better place than Matt Williams' YouTube channel. His videos get a lot of comments and they tend to contain a treasure trove of the things that people are thinking about and the questions that they have. Matt recently did a video about embeddings in Ollama and I thought it’d be fun to try to get a high-level overview of what’s happening in the comments section.
In this blog post, we’re going to do just that, following these steps:
-
Get the comments for a YouTube video
-
Generate an embedding for each comment
-
Cluster the embeddings using hierarchical/agglomerative clustering
-
Visualise the embeddings using tSNE
Getting YouTube comments
In a previous blog post, I wrote a function that gets all the top-level comments for a given video, so we’re going to reuse that function in this post. To use this function, you’ll need to first go to console.developers.google.com, create a project and enable YouTube Data API v3.
Once you’ve done that, create an API key.
And then create an environment variable that contains the API key:
export YOUTUBE_API_KEY="your-api-key-goes-here"And then install the python-youtube library
pip install python-youtubeNext, we’ll initialise the API class:
from pyyoutube import Api
import os
API_KEY = os.environ.get("YOUTUBE_API_KEY")
api = Api(api_key=API_KEY)And finally, let’s take a look at the function to get all the comment threads for a video:
def get_all_comment_threads(api, video_id, per_page=10):
threads = []
token = None
while True:
response = api.get_comment_threads(
video_id=video_id,
count=per_page,
page_token=token
)
threads.append(response)
token = response.nextPageToken
if not token:
break
return threadsWe can use the function like this to get all the top-level comments for Matt’s video:
threads = get_all_comment_threads(api, "Ml179HQoy9o", per_page=100)
all_comments = [
item.snippet.topLevelComment.snippet.textDisplay
for t in threads for item in t.items
]
len(all_comments), all_comments[:10](
104,
[
'It's nice that these embeddings are generated much faster, but have you ran any tests to see if they're any good?',
'Can you make a video on How vector database work? It's internal working',
'Great video! would love to see the vector DB video as well',
'Hi Matt . You are realy impresionante. Could you share with me a siurce Code of video example. I'll be very happy',
'Would love a video on db options',
'Thanks a lot for your great videos! Please make a video on "how to" and "which" of vector databases.',
'Great content! Super useful embedding. Seems we need to use nomic API from now on for using the embedding?',
'So are these embeddings 'better' than some of the huggingface embeddings? Having said that the more important question is what is in that flask, i think thats what we all want to know! 😊',
'I feel like I’m missing something because I fundamentally don’t understand the use cases for embedding',
'Do people actually use llama2 for embeddings though?'
]
)We’ve got 104 comments to work with and you can see from this sample that the comments cover a range of different things from people saying how much they enjoyed the video to others who want to know what the use case is for them.
Generating embeddings
Now that we’ve got the comments to work with, we’re going to create some embeddings. Embeddings take a piece of content and convert it into an array of floating-point numbers.
Those floating point numbers represent the semantic meaning of the content according to the embedding model’s view of the world. We don’t have any idea what the individual numbers mean, but they’re capturing some characteristics of the content that we’ve embedded.
|
If you’re interested in learning more about embedding algorithms, the best resource that I’ve come across is Simon Willison’s blog post. |
While I love arrays of floating-point numbers as much as the next developer, what makes embeddings useful is that we can compare them to each other. For example, we could use them to find similar blog posts, which I wrote about a few weeks ago. Or, in our case, we can create clusters of embeddings based on their closeness in n-dimensional space.
But that’s for the next section! Let’s first create the embeddings, which we’re going to do using Ollama, so let’s get that library installed:
pip install ollamaYou’ll also need to make sure that you’ve downloaded and installed Ollama. If you’re running on a Mac it will then be automatically running in the background, but you can also start the Ollama server manually:
ollama servetime=2024-02-28T07:21:02.893Z level=INFO source=images.go:710 msg="total blobs: 64"
time=2024-02-28T07:21:02.908Z level=INFO source=images.go:717 msg="total unused blobs removed: 0"
time=2024-02-28T07:21:02.910Z level=INFO source=routes.go:1019 msg="Listening on 127.0.0.1:11434 (version 0.1.27)"
time=2024-02-28T07:21:02.910Z level=INFO source=payload_common.go:107 msg="Extracting dynamic libraries..."
time=2024-02-28T07:21:02.928Z level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [metal]"Ollama supports two embedding algorithms at the time of writing - Nomic Embed Text and all-minilm. Nomic Embed got a lot of attention recently because it’s the first text embedding model that’s open source, uses open data, and has open training code. That sounds like more than enough reasons to give it a try, so let’s pull that down to our machine:
ollama pull nomic-embed-textNow we’re ready to create some embeddings. The Nomic algorithm has a maximum context length of 8192 - in other words, the text that we embed must not have more characters than that. Let’s quickly calculate some descriptive statistics on the number of characters in our dataset:
import statistics
comments_length = [len(c) for c in all_comments]
(
min(comments_length),
max(comments_length),
sum(comments_length)/len(comments_length),
statistics.median(comments_length)
)(5, 850, 160.05769230769232, 104.5)We’ve got quite a big range here but all the comments are below the limit. Keep in mind that the amount of times to embed some text is correlated with how many characters it has i.e. the bigger the text, the longer it takes! We can create embeddings by running the following code:
embeddings = [
ollama.embeddings(model='nomic-embed-text', prompt=comment)['embedding']
for comment in all_comments
]It took 2 seconds to embed all these comments on my Mac M1.
If you ran ollama serve, you can see how long it took to embed each comment by looking at the logs:
[GIN] 2024/02/28 - 07:25:24 | 200 | 1.27146875s | 127.0.0.1 | POST "/api/embeddings"
[GIN] 2024/02/28 - 07:25:24 | 200 | 10.114416ms | 127.0.0.1 | POST "/api/embeddings"
[GIN] 2024/02/28 - 07:25:24 | 200 | 9.779417ms | 127.0.0.1 | POST "/api/embeddings"
...
[GIN] 2024/02/28 - 07:25:26 | 200 | 12.372084ms | 127.0.0.1 | POST "/api/embeddings"
[GIN] 2024/02/28 - 07:25:26 | 200 | 11.281209ms | 127.0.0.1 | POST "/api/embeddings"
[GIN] 2024/02/28 - 07:25:26 | 200 | 12.692333ms | 127.0.0.1 | POST "/api/embeddings"The amount of time that it takes is quite low for us because the comments don’t have many characters. We should expect this time to go up if we embed larger chunks of text.
Now that we’ve got the embeddings, let’s do a quick sanity check.
I’m going to nick the cosine_similarity from Simon Willison’s blog to help out:
def cosine_similarity(a, b):
dot_product = sum(x * y for x, y in zip(a, b))
magnitude_a = sum(x * x for x in a) ** 0.5
magnitude_b = sum(x * x for x in b) ** 0.5
return dot_product / (magnitude_a * magnitude_b)We’re going to create an embedding for the text Great video. I loved it and find the most similar comments to that embedding.
search_embedding = ollama.embeddings(
model='nomic-embed-text',
prompt="Great Video. I loved it."
)['embedding']
sorted([
(comment, cosine_similarity(embedding, search_embedding))
for comment, embedding in zip(all_comments, embeddings)
], key=lambda x: x[1]*-1)[:5][
('Your voice is amazing. I could listen to you present on anything man. Amazing video', 0.6389594729369522),
('Hi Matt, thanks for making these videos. It is very informative and helpful.', 0.6236011957217291),
('I really loved this video! Great and super timely topic. Yes on a Vector DB comparison video.', 0.6122029716924652),
('You are a great teacher!! I want to see more videos of yours. Thanks for your service🙇', 0.5930268150386624),
('thank you, I really appreciate your works and support. can't wait next video.', 0.5906926818452719)
]That looks pretty good to me - all of those comments are saying that they enjoyed the video.
Cluster the embeddings
Next, we’re going to cluster the embeddings so that the embeddings for similar comments are near to each other in embedding space. We’ll be using plot.ly and scikit-learn, so let’s install those libraries:
pip install plotly scikit-learnThere are a variety of clustering techniques that we could use, one of which is hierarchical clustering, a technique that builds a hierarchy of clusters.
plot.ly has a create_dendrogram function that performs hierarchical clustering and renders the resulting tree.
Let’s give that a try:
import plotly.figure_factory as ff
import numpy as np
fig = ff.create_dendrogram(np.array(embeddings))
fig.update_layout(width=1500, height=1000)
fig.show()The resulting diagram is shown below:
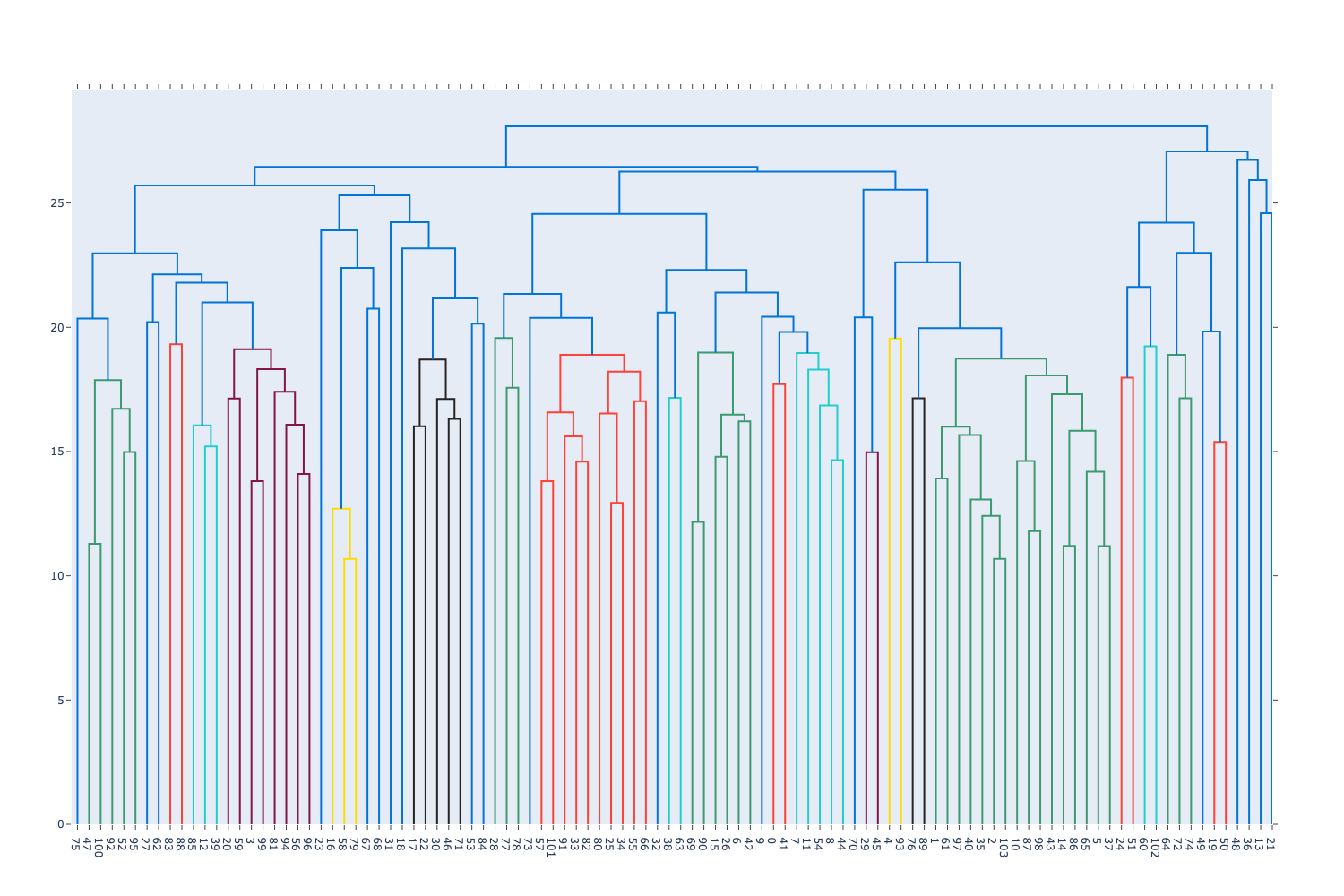
The cluster breaks into two at the top level, but there are a lot more values on the left-hand side. If we go down one more level on each side, we end up with 6 clusters, which looks like it might be a good way of cutting the data.
It’s kinda hard to know exactly what the right number of clusters should be, but let’s start with 6 and see how we go. We can create cluster labels for each embedding using the following scikit-learn code:
from scipy.cluster.hierarchy import linkage, cut_tree, dendrogram
from collections import defaultdict
# Compute cluster labels
complete_clustering = linkage(embeddings, method="complete", metric="cosine")
cluster_labels = cut_tree(complete_clustering, n_clusters=6).reshape(-1, )
# Create a label -> comments dictionary
groups = defaultdict(list)
for id, label in zip(all_comments, cluster_labels):
groups[label].append(id)Let’s have a look at what’s in each cluster:
for k,v in groups.items():
print(f"Cluster: {k} ({len(v)})")
print(v[:5])Cluster: 0 (52)
['It's nice that these embeddings are generated much faster, but have you ran any tests to see if they're any good?', 'Can you make a video on How vector database work? It's internal working', 'Great video! would love to see the vector DB video as well', 'Would love a video on db options', 'Thanks a lot for your great videos! Please make a video on "how to" and "which" of vector databases.']
Cluster: 1 (19)
['Hi Matt . You are realy impresionante. Could you share with me a siurce Code of video example. I'll be very happy', 'Hi Matt, love your content - super stuff thank you, this is exactly what I was looking for and you explain it so well, I am working on a project of RAG search using open-source for a big Genomics project, providing specific information to users of the service, really detailed information about which test to request etc this video came just at the right time 👍', 'I hate shorts. Those videos are for young people who can't concentrate on anything for even 2 minutes.', 'just a heads up bunnies can fly', 'This is such good content. Can you do a full video tutorial on a production case of a best rag strategy. There's so many out there .']
Cluster: 2 (13)
['0.1.27 🙂', 'Thank you Matt! 🎉', '<3', 'great stuff Thanks for the valuable information', 'Matt, less is more, look after the family.']
Cluster: 3 (16)
['I am not familiar yet with ollama. I have been waiting for the windows version... Does it only support specific embeddings? I use for example BGE embeddings for rag. Is this possible? I also see in comments that ollama does not support multi user inference concurrently. If true than it's ok for testing but not for production. <br>Btw: I prefer 2 legs Bunnies than flying Bunnies😉', 'Maybe you could share with us the update procedure if we're running ollama webui for windows out of local docker, the best way to update it without screwing it up?', 'Thanks for your superb videos, your content is so rich and well paced - would like to see more about model training using ollama and embedding', 'Can you share a tutorial on how to do this? I have not used embeddings so far and am still quite new to Ollama. Any resources you can share are highly appreciated.', 'Definitely do the side by side for the db options in the context of ollama on something like an M2. Our work machines for the public school system are M2s with only 8 gigs of RAM, as a reference point. The potential for a local teaching assistant is definitely close']
Cluster: 4 (3)
['Don't wasting time on Gemma, it is just not worth it.', 'Great video! Embeddings take Ollama to the next level! And I love that you dont lose a word about Gemma ;)', 'Vids keep getting better - and thanks - I overlooked the embeddings due to gemma!']
Cluster: 5 (1)
['keep up']Cluster 0 seems to be people asking Matt to do a video about vector databases and Cluster 4 is about Google’s Gemma model, but (at least from 5 comments) it’s not obvious to me what the other clusters contain. There’s also a big difference in the number of items in each cluster, which doesn’t help.
If we put the clustering code into a function, we can play around with different cluster sizes more easily:
from scipy.cluster.hierarchy import linkage, cut_tree, dendrogram
from collections import defaultdict
def compute_clusters(n_clusters=3):
complete_clustering = linkage(embeddings, method="complete", metric="cosine")
cluster_labels = cut_tree(complete_clustering, n_clusters=n_clusters).reshape(-1, )
groups = defaultdict(list)
for id, label in zip(all_comments, cluster_labels):
groups[label].append(id)
return groups, cluster_labelsThis function also returns the cluster labels, because we’ll need those in the next section.
We can call the function like this:
for k,v in compute_clusters(n_clusters=9)[0].items():
print(f"Cluster: {k} ({len(v)})")
print(v[:5])Cluster: 0 (11)
['It's nice that these embeddings are generated much faster, but have you ran any tests to see if they're any good?', 'Do people actually use llama2 for embeddings though?', 'did they finally add batching support?', 'You show running some random curl command for 0.25 sec of the video against <b>some</b> local API you setup beforehand that exposes <b>some</b> type of embedding behavior... and then never mention anything more about the most important piece of information in this entire video... is this like an intentional mystery video, like a luminal space bit, except it's a tech review art piece or something?', 'ok, but what everyone wants to know is if its better at any given task than the now dime a dozen competitors. we have oobabooga, lmstudio, some forge thing, llama itself in either c++ or python format and more']
Cluster: 1 (25)
['Can you make a video on How vector database work? It's internal working', 'Great video! would love to see the vector DB video as well', 'Would love a video on db options', 'Thanks a lot for your great videos! Please make a video on "how to" and "which" of vector databases.', 'Cool! Good news!<br>Lets discuss vector db, algorithms for vector search']
Cluster: 2 (16)
['Hi Matt . You are realy impresionante. Could you share with me a siurce Code of video example. I'll be very happy', 'Hi Matt, love your content - super stuff thank you, this is exactly what I was looking for and you explain it so well, I am working on a project of RAG search using open-source for a big Genomics project, providing specific information to users of the service, really detailed information about which test to request etc this video came just at the right time 👍', 'I hate shorts. Those videos are for young people who can't concentrate on anything for even 2 minutes.', 'This is such good content. Can you do a full video tutorial on a production case of a best rag strategy. There's so many out there .', 'Thank you Matt for making these videos!']
Cluster: 3 (16)
['Great content! Super useful embedding. Seems we need to use nomic API from now on for using the embedding?', 'So are these embeddings 'better' than some of the huggingface embeddings? Having said that the more important question is what is in that flask, i think thats what we all want to know! 😊', 'I feel like I’m missing something because I fundamentally don’t understand the use cases for embedding', 'What about the most accurate embedding, the one that captures the semantic meaning of a text very well?', 'Thank you! swapping my langchain embedding model with nomic-embed-text, really speed it up. This really is bigger news then gemma']
Cluster: 4 (13)
['0.1.27 🙂', 'Thank you Matt! 🎉', '<3', 'great stuff Thanks for the valuable information', 'Matt, less is more, look after the family.']
Cluster: 5 (16)
['I am not familiar yet with ollama. I have been waiting for the windows version... Does it only support specific embeddings? I use for example BGE embeddings for rag. Is this possible? I also see in comments that ollama does not support multi user inference concurrently. If true than it's ok for testing but not for production. <br>Btw: I prefer 2 legs Bunnies than flying Bunnies😉', 'Maybe you could share with us the update procedure if we're running ollama webui for windows out of local docker, the best way to update it without screwing it up?', 'Thanks for your superb videos, your content is so rich and well paced - would like to see more about model training using ollama and embedding', 'Can you share a tutorial on how to do this? I have not used embeddings so far and am still quite new to Ollama. Any resources you can share are highly appreciated.', 'Definitely do the side by side for the db options in the context of ollama on something like an M2. Our work machines for the public school system are M2s with only 8 gigs of RAM, as a reference point. The potential for a local teaching assistant is definitely close']
Cluster: 6 (3)
['just a heads up bunnies can fly', 'i think bunny can fly, i just saw in your video', 'Your bunny wrote<br>On a serious note great vids mate']
Cluster: 7 (3)
['Don't wasting time on Gemma, it is just not worth it.', 'Great video! Embeddings take Ollama to the next level! And I love that you dont lose a word about Gemma ;)', 'Vids keep getting better - and thanks - I overlooked the embeddings due to gemma!']
Cluster: 8 (1)
['keep up']Now the comments about making a video on vector databases have moved into Cluster 1 and Cluster 0 is people asking if the generated embeddings are any good. Cluster 2 is people asking for code and a longer tutorial. Cllustr 6 has the bunnies and Cluster 7 still has no love for Gemma.
I think 9 clusters is doing a better job at pulling out the types of comments than 6 was doing, but we could certainly play around with other values.
Visualise the embeddings
Finally, we’re going to visualise the embeddings along with their labels. To visualise the data we need to reduce the number of dimensions in the embeddings to either 2 or 3 dimensions, otherwise it’ll be too hard for our poor human eyes to understand what’s going on!
As with clustering, there are many algorithms to do this. One of the best known is called t-SNE or T-distributed Stochastic Neighbor Embedding, which has an implementation in scikit-learn.
The t-SNE documentation suggests that we should first reduce the dimensionality of our vectors to 50 before using it to reduce noise and speed up computation. We’ve only got 100 vectors so I don’t think speed will be an issue. We’ll live a bit on the wild side and feed the embeddings straight in.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, verbose=1)
tsne_results = tsne.fit_transform(np.array(embeddings))[t-SNE] Computing 91 nearest neighbors...
[t-SNE] Indexed 104 samples in 0.015s...
[t-SNE] Computed neighbors for 104 samples in 0.042s...
[t-SNE] Computed conditional probabilities for sample 104 / 104
[t-SNE] Mean sigma: 6.827137
[t-SNE] KL divergence after 250 iterations with early exaggeration: 59.206711
[t-SNE] KL divergence after 1000 iterations: 0.402528import plotly.graph_objects as go
_, cluster_labels = compute_clusters(n_clusters=9)
df = pd.DataFrame(tsne_results, columns=['x', 'y'])
df["comments"] = all_comments
df["label"] = cluster_labels
fig = go.Figure(data=go.Scatter(
x=df['x'],
y=df['y'],
marker=dict(color=df['label'], size=15),
mode='markers',
text=df['comments'])
)
fig.show()You can see an animated version of the clusters below:
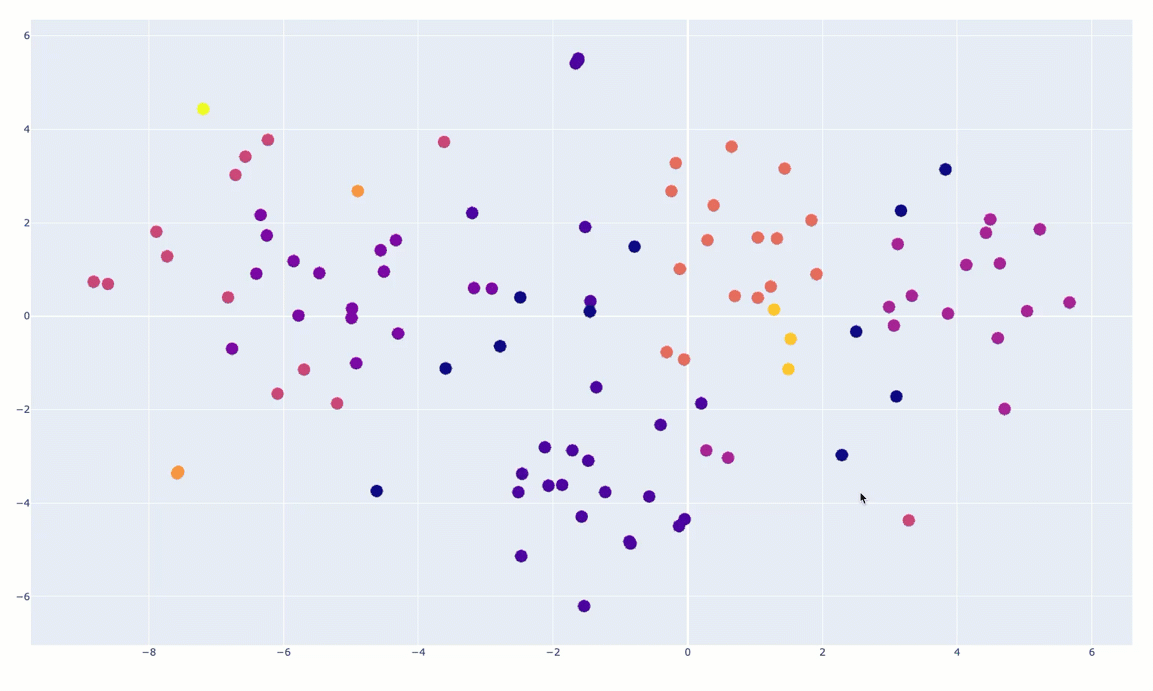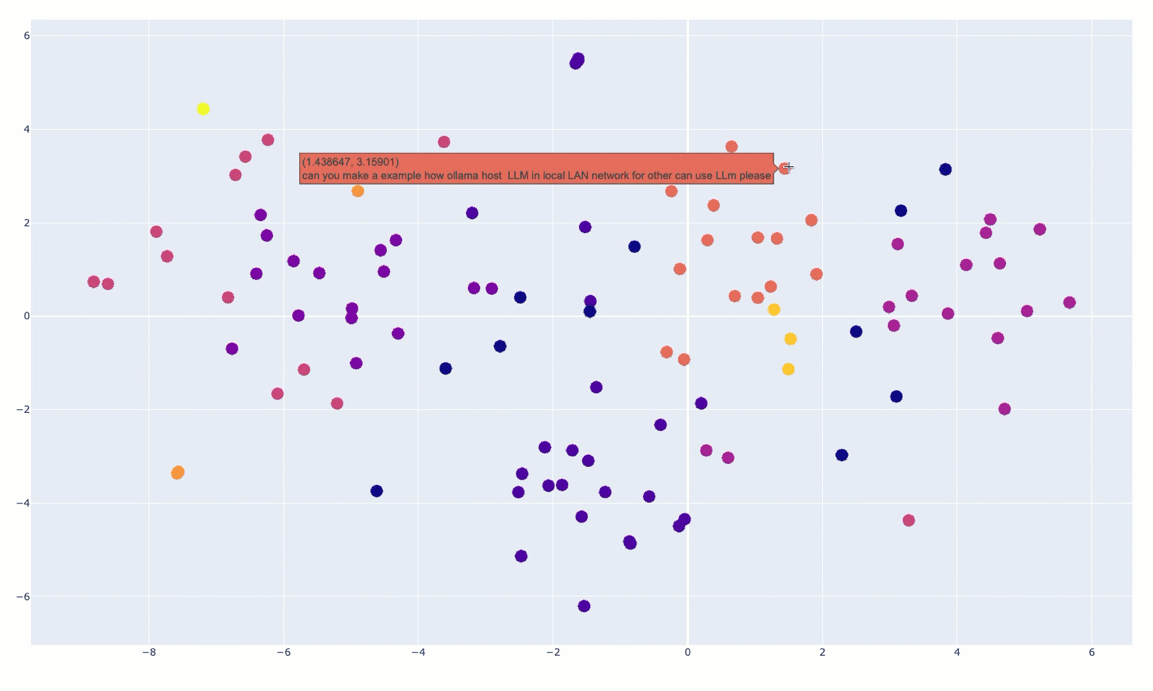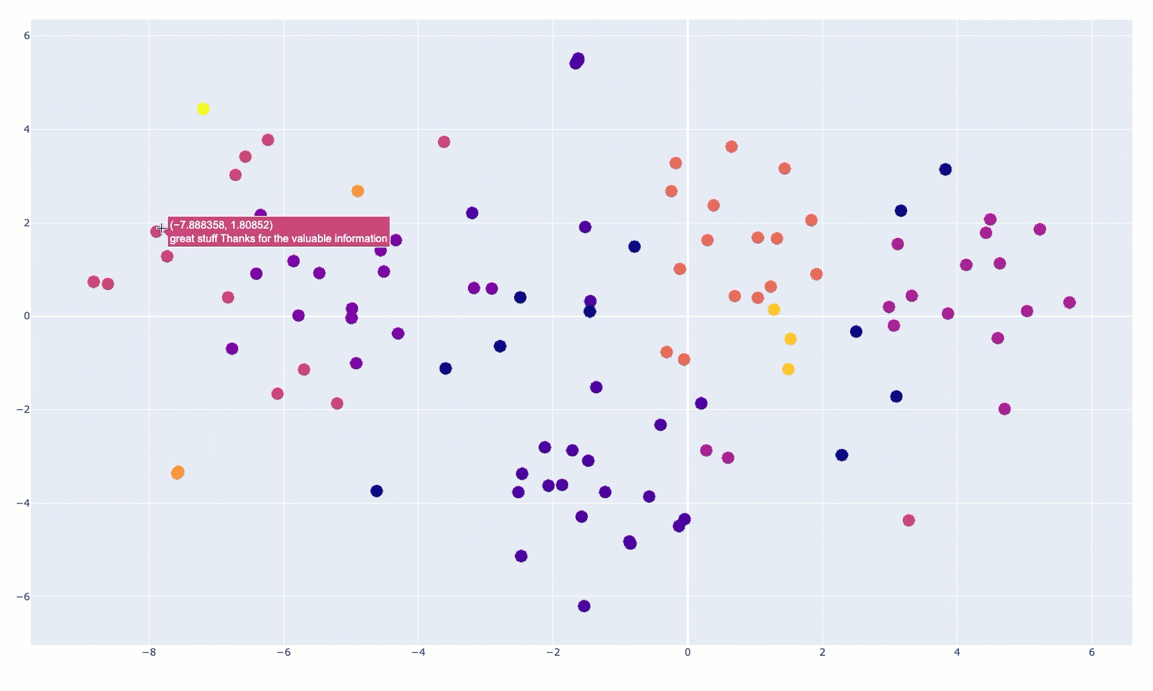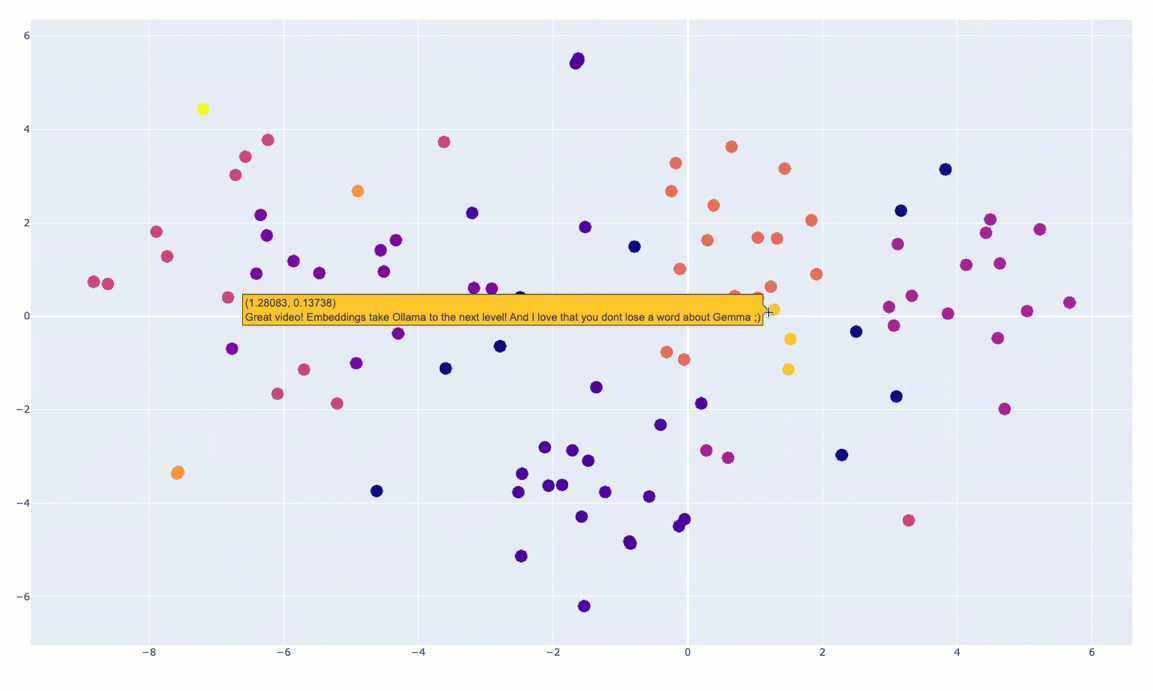
And then I’ve done some manual annotation of the clusters in the following diagram:

What next?
Hopefully that’s shown you some interesting ways that we can use embeddings to make sense of YouTube comments, but there are certainly more things that we can do. Some things off the top of my head:
-
Use a large language model to come up with cluster labels
-
Give a large language model the clusters + comments and ask it to evaluate the clusters. Or maybe we could even get the LLM to do the clustering for us?
-
Try out some different clustering methods and dimensionality reduction techniques
-
Put all of this into an interactive application so that we can iterate on different approaches more easily
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.