
Ollama: Experiments with few-shot prompting on Llama2 7B
A problem that I’m currently trying to solve is how to work out whether a given sentence is a question. If there’s a question mark on the end we can assume it is a question, but what about if the question mark’s been left off?
Few-shot prompting is a technique where we provide some examples in our prompt to try to guide the LLM to do what we want. And, this seemed like a good opportunity to try it out on Meta’s Llama2 7B Large Language Model using Ollama.
|
I’ve created a video showing how to do this on my YouTube channel, Learn Data with Mark, so if you prefer to consume content through that medium, I’ve embedded it below: |
But before we do that, we’re going to create a baseline where we don’t provide any examples.
I’ve created a file, sentences.csv, which contains sentences in one column and whether I think they’re a question in the other.
| Sentence | IsQuestion |
|---|---|
The weather is quite pleasant today. |
false |
Have you ever been to Paris |
true |
I enjoy reading books on rainy days. |
false |
What is your favorite type of cuisine |
true |
The movie last night was exhilarating. |
false |
She has a collection of vintage postcards. |
false |
Can you believe it’s already October |
true |
I think the library closes at 6 pm. |
false |
Where do you usually go for vacation |
true |
It’s amazing how time flies. |
false |
The concert last night was incredible. |
false |
Have you finished the report yet |
true |
He likes to play soccer on weekends. |
false |
What time does the meeting start |
true |
I can’t believe how fast the kids are growing up. |
false |
Is the grocery store open on Sundays |
true |
She has a knack for solving complex puzzles. |
false |
Guess who just got promoted |
true |
The painting in the hallway is quite striking. |
false |
Could be that he forgot our appointment. |
false |
A sentence-focused model with no examples
Next, we’re going to create a model specifically for determining if something is a question.
We’re going to create a model file, Modelfile-question-llama2-base, which should look like this:
FROM llama2
TEMPLATE """
<s>
[INST]
{{- if .First }}
<<SYS>>
{{.System}}
<</SYS>>
{{- end }}
{{.Prompt}}
[/INST]
"""
SYSTEM """You are a question analyzer. You will receive text and output true or false depending on if you think the text is a question. Do NOT try to answer the question."""The exact format used in the TEMPLATE section will vary depending on the model that you’re using, but this is the one for Llama2.
We can then run the following command:
ollama create \
question-llama2-base \
-f Modelfile-question-llama2-baseparsing modelfile
looking for model
creating model template layer
creating model system layer
creating config layer
using already created layer sha256:8daa9615cce30c259a9555b1cc250d461d1bc69980a274b44d7eda0be78076d8
using already created layer sha256:8c17c2ebb0ea011be9981cc3922db8ca8fa61e828c5d3f44cb6ae342bf80460b
using already created layer sha256:7c23fb36d80141c4ab8cdbb61ee4790102ebd2bf7aeff414453177d4f2110e5d
using already created layer sha256:e35ab70a78c78ebbbc4d2e2eaec8259938a6a60c34ebd9fd2e0c8b20f2cdcfc5
writing layer sha256:259d89c66e53cd019f48e7f41127a0f9d7cc522b58c35cfd1411395e5e81cf8f
writing layer sha256:04f603753dacd8b5f855cdde37290d26ce45b283114fb40c00646c3f063333f4
writing layer sha256:846424fbd2c37f30a9ccc3a33efe20b24ff44988293b92d35bb80c1d4fcb4b09
writing manifest
removing any unused layers
successWe can then call the model passing in say one of the sentences:
ollama run \
question-llama2-base \
"The weather is quite pleasant today."TrueIt’s kinda working, but we can already see that it’s not returning the result in the format that I suggested.
Let’s have a look at how it gets on with all the sentences using the Llama Index library.
We’re also going to install a utility library called mpu that we’ll use to coerce the boolean string in the CSV file to a boolean value, as well as scikit-learn to see how well the model does.
pip install llama_index mpu scikit-learnWe’ll first load the sentences:
import csv
from mpu.string import str2bool
with open('sentences.csv', 'r') as sentences_file:
reader = csv.reader(sentences_file, delimiter=",")
next(reader)
sentences = [(row[0], str2bool(row[1])) for row in reader]
sentencesWe’re also going to create a couple of helper functions to render the results:
def handle_result(is_sentence, llm_answer):
result = f"Actual: {str(is_sentence).ljust(5)} LLM: {llm_answer}"
print(f"{sentence.ljust(60)} {result}")
def handle_error(is_sentence, ex, llm_says):
result = f"Actual: {str(is_sentence).ljust(5)} LLM: {ex} - {llm_says}"
print(f"{sentence.ljust(60)} {result}")Now, let’s initialise the Llama2 model:
from llama_index.llms import Ollama
base_llama2 = Ollama(model="question-llama2-base")And iterate over each of the sentences, asking the LLM whether it’s a sentence, and then checking the answer.
We’re using the JSON module to parse the result since true and false are valid JSON values.
import json
llm_answers=[]
for sentence, is_sentence in sentences:
llm_says = base_llama2.complete(sentence).text
try:
llm_answer = json.loads(llm_says)
handle_result(is_sentence, llm_answer)
llm_answers.append(llm_answer)
except json.JSONDecodeError as ex:
handle_error(is_sentence, ex, llm_says)
llm_answers.append(None)If we run that code, we see the following output:
The weather is quite pleasant today. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Have you ever been to Paris Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
I enjoy reading books on rainy days. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
What is your favorite type of cuisine Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
The movie last night was exhilarating. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
She has a collection of vintage postcards. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Can you believe it’s already October Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
I think the library closes at 6 pm. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Where do you usually go for vacation Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
It’s amazing how time flies. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
The concert last night was incredible. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Have you finished the report yet Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
He likes to play soccer on weekends. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
What time does the meeting start Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
I can't believe how fast the kids are growing up. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Is the grocery store open on Sundays Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
She has a knack for solving complex puzzles. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Guess who just got promoted Actual: True LLM: Expecting value: line 1 column 1 (char 0) - True
The painting in the hallway is quite striking. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - True
Could be that he forgot our appointment. Actual: False LLM: Expecting value: line 1 column 1 (char 0) - TrueSo it hasn’t returned a value in the correct format for any of the 20 questions and it’s returning True every single time, which isn’t very useful.
We can see how many we computed correctly by running the following code:
len([
predicted
for predicted, actual in zip(llm_answers, [s[1] for s in sentences])
if predicted == actual
])0Unsurprisingly we have none right since the LLM didn’t return a value in the correct format.
A sentence-focused model with examples
Let’s see if we fare any better with a model that’s been given a few examples of what we want it to do. The Modelfile for this approach is shown below:
FROM llama2
TEMPLATE """
<s>
[INST]
{{- if .First }}
<<SYS>>
{{.System}}
<</SYS>>
{{- end }}
My name is Mark
[/INST]
false
</s>
<s>
[INST]
Can you do it with OpenAI?
[/INST]
true
</s>
<s>
[INST]
Will you make another tutorial
[/INST]
true
</s>
<s>
[INST]
{{.Prompt}}
[/INST]
"""
SYSTEM """You are a question analyzer. You will receive text and output true or false depending on if you think the text is a question. Do NOT try to answer the question."""Let’s build that model:
ollama create \
question-llama2 \
-f Modelfile-question-llama2Now let’s go back to our Python environment and give this one a try. First up, initialising the model:
llama2 = Ollama(model="question-llama2")And now let’s loop over the sentences like we did before:
llm_answers=[]
for sentence, is_sentence in sentences:
llm_says = llama2.complete(sentence).text
try:
llm_answer = json.loads(llm_says)
handle_result(is_sentence, llm_answer)
llm_answers.append(llm_answer)
except json.JSONDecodeError as ex:
handle_error(is_sentence, ex, llm_says)
llm_answers.append(None)The weather is quite pleasant today. Actual: False LLM: False
Have you ever been to Paris Actual: True LLM: False
I enjoy reading books on rainy days. Actual: False LLM: True
What is your favorite type of cuisine Actual: True LLM: False
The movie last night was exhilarating. Actual: False LLM: False
She has a collection of vintage postcards. Actual: False LLM: False
Can you believe it’s already October Actual: True LLM: True
I think the library closes at 6 pm. Actual: False LLM: False
Where do you usually go for vacation Actual: True LLM: True
It’s amazing how time flies. Actual: False LLM: True
The concert last night was incredible. Actual: False LLM: Extra data: line 2 column 1 (char 6) - false
</s>
Have you finished the report yet Actual: True LLM: True
He likes to play soccer on weekends. Actual: False LLM: False
What time does the meeting start Actual: True LLM: True
I can't believe how fast the kids are growing up. Actual: False LLM: True
Is the grocery store open on Sundays Actual: True LLM: True
She has a knack for solving complex puzzles. Actual: False LLM: True
Guess who just got promoted Actual: True LLM: True
The painting in the hallway is quite striking. Actual: False LLM: False
Could be that he forgot our appointment. Actual: False LLM: TrueThat looks better already, although it looks like we’re sometimes getting an </s> token returned as well.
Let’s update the code to strip those out:
llm_answers=[]
for sentence, is_sentence in sentences:
llm_says = llama2.complete(sentence).text
try:
llm_answer = json.loads(llm_says.replace("</s>", ""))
handle_result(is_sentence, llm_answer)
llm_answers.append(llm_answer)
except json.JSONDecodeError as ex:
handle_error(is_sentence, ex, llm_says)
llm_answers.append(None)If we run it again, we see the following output:
The weather is quite pleasant today. Actual: False LLM: False
Have you ever been to Paris Actual: True LLM: False
I enjoy reading books on rainy days. Actual: False LLM: True
What is your favorite type of cuisine Actual: True LLM: False
The movie last night was exhilarating. Actual: False LLM: False
She has a collection of vintage postcards. Actual: False LLM: False
Can you believe it’s already October Actual: True LLM: True
I think the library closes at 6 pm. Actual: False LLM: False
Where do you usually go for vacation Actual: True LLM: True
It’s amazing how time flies. Actual: False LLM: True
The concert last night was incredible. Actual: False LLM: False
Have you finished the report yet Actual: True LLM: True
He likes to play soccer on weekends. Actual: False LLM: False
What time does the meeting start Actual: True LLM: True
I can't believe how fast the kids are growing up. Actual: False LLM: True
Is the grocery store open on Sundays Actual: True LLM: True
She has a knack for solving complex puzzles. Actual: False LLM: True
Guess who just got promoted Actual: True LLM: True
The painting in the hallway is quite striking. Actual: False LLM: False
Could be that he forgot our appointment. Actual: False LLM: TrueKeep in mind that LLMs aren’t deterministic, so we may well see different results between runs. Now that we’ve got a proper result for each sentence, we can compute some metrics.
Import the following functions from scikit-learn:
from sklearn.metrics import confusion_matrix, precision_score, recall_scoreFirst, we’re going to compute the precision score, which measures the True Positive / (True Positive + False Positive).
This metric describes the ability of the LLM not to label as a question a sentence that is not a question.
We can compute this metric with the following code:
precision_score([s[1] for s in sentences], llm_answers, zero_division=0.0)0.5454545454545454We can also compute the recall score, which measures the True Positive / (True Positive + False Negative).
This metric describes the ability of the LLM to find all the questions in the dataset.
We can compute this metric with the following code:
recall_score([s[1] for s in sentences], llm_answers)0.75We can also compute a confusion matrix, which shows the true/false positives/negatives on a 2x2 grid.
matrix = confusion_matrix([s[1] for s in sentences], llm_answers)
matrixarray([[7, 5],
[2, 6]])This one is better visualised, so let’s create a diagram with the following function, which uses the seaborn library:
import seaborn as sns
def render_confusion_matrix(matrix):
ax = sns.heatmap(matrix, annot=False, cmap=['white'], cbar=False,
linecolor='black', linewidths=1,
xticklabels=['Negative', 'Positive'],
yticklabels=['Negative', 'Positive']
)
labels = ['TN', 'FP', 'FN', 'TP']
for i in range(2):
for j in range(2):
ax.text(j+0.5, i+0.4, f"{str(matrix[i, j])}",
fontsize=16,
horizontalalignment='center',
verticalalignment='center')
ax.text(j+0.5, i+0.55, f"{labels[i * 2 + j]}",
color='green' if labels[i * 2 + j][0] == "T" else 'red',
fontsize=14,
horizontalalignment='center',
verticalalignment='center')
ax.xaxis.tick_top()
ax.xaxis.set_ticks_position('top')
ax.set_ylabel('Data (Truth)')
ax.set_xlabel('LLM prediction')If we render the matrix:
render_confusion_matrix(matrix)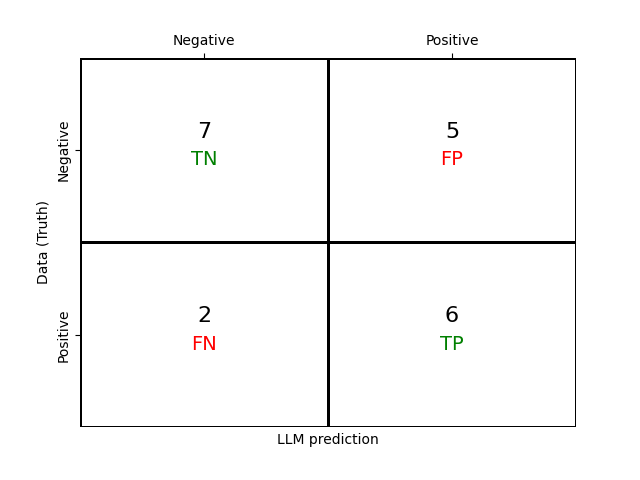
Summary
Overall, we can see that our LLM isn’t doing a great job here! It’s better at working out if something isn’t a question than if it is a question, but even there it still gets some wrong.
My next experiment will be to see if I can get better results with one of the Llama2 models that has more parameters.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.