
GPT 3.5 Turbo vs GPT 3.5 Turbo Instruct
Last week OpenAI sent out the following email introducing the gpt-3.5-turbo-instruct large language model:
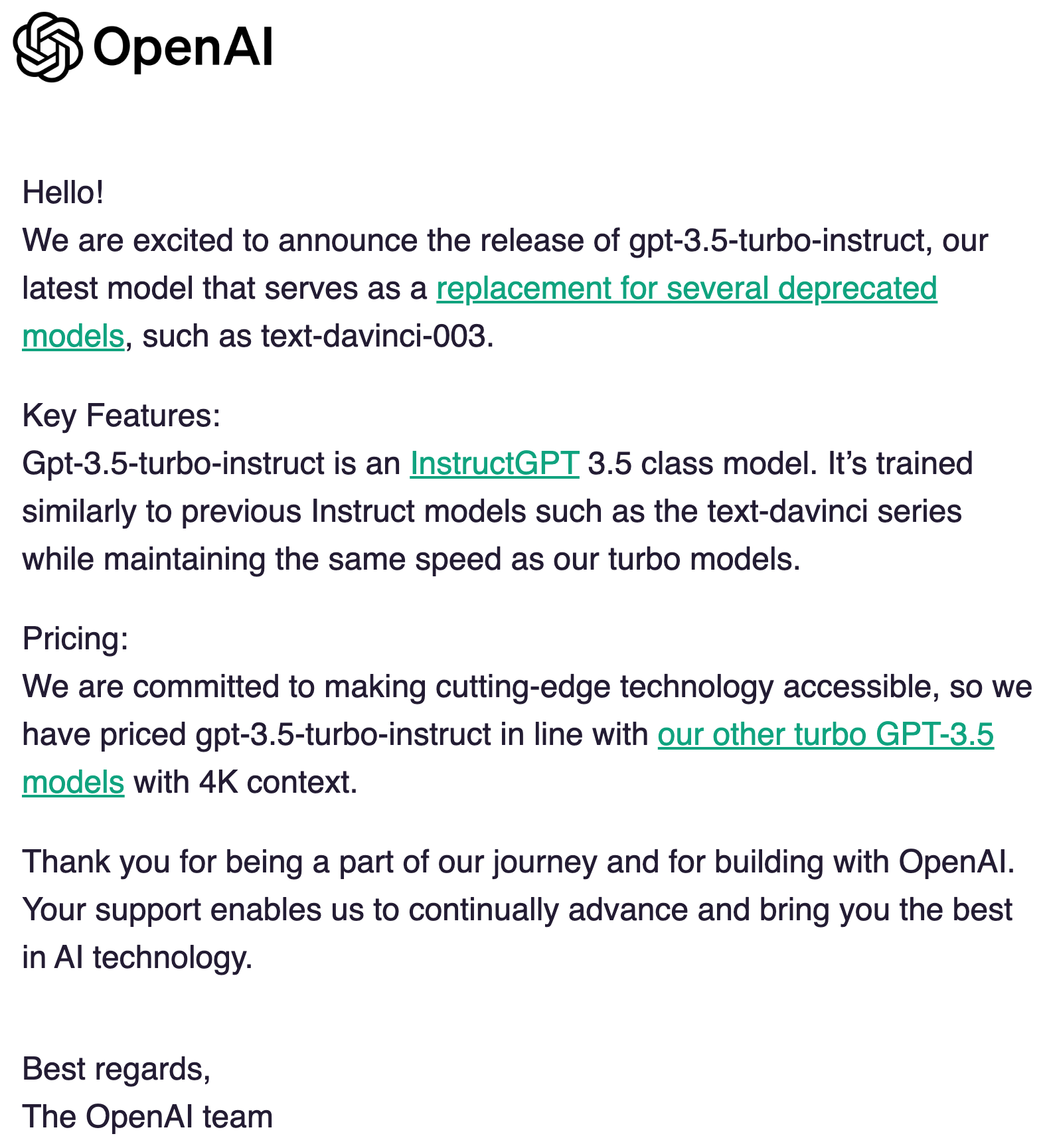
I’ve never completely understood the difference between the chat and instruct models, so this seemed like a good time to figure it out. In this blog post, we’re going to give the models 5 tasks to do and then we’ll see how they get on.
|
I’ve created a video showing how to do this on my YouTube channel, Learn Data with Mark, so if you prefer to consume content through that medium, I’ve embedded it below: You can also find all the code at the GPT-Instruct-Tutorial.ipynb notebook. |
Setup
First things first, let’s install some libraries:
pip install langchain openai python-dotenv wikipediaI’ve got my OpenAI key in a file called .env, so let’s first import that:
import dotenv
dotenv.load_dotenv()And now we’re going to create chat and instruct models. First, chat:
from langchain.chat_models import ChatOpenAI
turbo = ChatOpenAI(model_name="gpt-3.5-turbo")And then instruct:
from langchain.llms import OpenAI
turbo_instruct = OpenAI(model_name="gpt-3.5-turbo-instruct")Answering factual questions 🤓
It’s time to put the models through their paces. Task number 1 is to answer a factual question:
question = "Did Microsoft acquire OpenAI?"We can get the chat LLM’s answer by running the following:
print(turbo.predict(question))No, Microsoft has not acquired OpenAI. However, Microsoft has provided financial support to OpenAI and the two companies have formed a partnership to work together on AI research and development.
CPU times: user 32.8 ms, sys: 4.46 ms, total: 37.3 ms
Wall time: 3.28 sNow it’s instruct’s turn:
print(turbo_instruct.predict(question))No, Microsoft did not acquire OpenAI. Microsoft and OpenAI have a partnership where Microsoft invests $1 billion in OpenAI's research and development efforts.
CPU times: user 5.79 ms, sys: 3.06 ms, total: 8.85 ms
Wall time: 866 msInstruct is a bit more concise, but they more or less say the same thing.
Replying with empathy 💕
Next up, replying with empathy. Let’s pretend I’m sad and need cheering up. What will they suggest?
question = "I'm feeling sad today. Can you cheer me up?"Chat is first up:
print(turbo.predict(question))I'm sorry to hear that you're feeling sad today, but I'll do my best to cheer you up! Remember that it's normal to have ups and downs, and this feeling won't last forever. Here are a few things that might brighten your day:
1. Reach out to a loved one: Talking to someone you trust about how you're feeling can provide support and comfort.
2. Do something you enjoy: Engaging in activities you love, such as listening to music, reading a book, or watching a funny movie, can help lift your spirits.
3. Practice self-care: Take some time to focus on yourself. Whether it's taking a relaxing bath, going for a walk in nature, or treating yourself to your favorite snack, prioritize your well-being.
4. Surround yourself with positivity: Surround yourself with things that make you happy. This could be listening to uplifting music, reading inspirational quotes, or looking at photos that bring back good memories.
5. Help others: Sometimes, doing something kind for someone else can give you a sense of fulfillment and joy. Consider volunteering, helping a friend, or even offering a kind word or gesture to brighten someone else's day.
Remember, it's okay to feel sad, but always know that brighter days are ahead. Take care of yourself and seek support when you need it.
CPU times: user 6.18 ms, sys: 3.23 ms, total: 9.41 ms
Wall time: 13.8 sI think there are some decent suggestions there, although it does take a long time to produce the answer - just under 14 seconds. Let’s see how instruct gets on:
print(turbo_instruct.predict(question))Of course! Here are a few things that might make you smile:
1. Look at some funny memes or watch a funny video. Laughter is the best medicine!
2. Call or text a friend or family member and have a chat. Sometimes just talking to someone can help lift our spirits.
3. Take a walk outside and enjoy some fresh air and sunshine. Nature has a way of making us feel better.
4. Treat yourself to something nice, like your favorite snack or a warm cup of tea.
5. Put on some upbeat music and dance around your room. It's hard to be sad when you're dancing!
Remember, it's okay to feel sad sometimes. But know that it won't last forever and there are always things we can do to make ourselves feel better. Sending you virtual hugs and positive vibes!
CPU times: user 5.34 ms, sys: 2.37 ms, total: 7.71 ms
Wall time: 2.43 sThe suggestions are pretty similar, but less detailed. It is, however, 5 times faster, which was surprising to me. I thought instruct would give short answers and that it would be quicker because of that, but there seems to be maybe a more fundamental difference that’s making it generate answers more quickly.
Code generation 💻
Time for task number 3, which is a code generation task. We’re going to ask the models to create a function that iterates through a CSV file and prints out every other line.
question = "Can you write a Python function that reads a CSV file and prints out every other row?"Over to you, chat:
print(turbo.predict(question))Yes, here's an example of a Python function that reads a CSV file and prints out every other row:
```python
import csv
def print_every_other_row(csv_file):
with open(csv_file, 'r') as file:
reader = csv.reader(file)
row_num = 0
for row in reader:
if row_num % 2 == 0:
print(row)
row_num += 1
# Example usage
print_every_other_row('example.csv')
```
In this function, we use the `csv` module to read the CSV file. The `csv.reader` object allows us to iterate over the rows of the file. We keep a counter `row_num` to keep track of the row number, and if `row_num` is even (i.e., every other row), we print the row.
CPU times: user 5.41 ms, sys: 3.07 ms, total: 8.48 ms
Wall time: 9.23 sThat looks good to me and having tested it, the code does do what I asked! Let’s see what instruct comes up with:
print(turbo_instruct.predict(question))def print_every_other_row(file_name):
# open the CSV file
with open(file_name, 'r') as csv_file:
# use the csv module to read the file
reader = csv.reader(csv_file)
# loop through each row in the file
for i, row in enumerate(reader):
# check if the row is odd
if i % 2 == 1:
# print the row
print(row)
CPU times: user 7.04 ms, sys: 3.57 ms, total: 10.6 ms
Wall time: 3.4 sThis time we get just the function.
I’d say this function is cleaner than the other one, but it has missed the import csv line that we need to use the CSV module.
Analysing sentiment 😊
Let’s make things a bit more interesting and see if the models can analyse the sentiment of a sentence.
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("Analyse the sentiment of the following text: {text}")
question = prompt.format(text="The DuckDB team is happy to announce the latest DuckDB release (0.9.0).")We’re gonna run this one three times each to see if the responses differ between runs:
for _ in range(0,3):
print(turbo.predict(question))The sentiment of the given text is positive.
The sentiment of the given text is positive.
The sentiment of the following text is positive. The use of words like "happy" and "announce" indicates a positive sentiment. Additionally, the mention of the latest release suggests excitement and satisfaction.
CPU times: user 16.7 ms, sys: 5.17 ms, total: 21.8 ms
Wall time: 5.88 sAnd instruct:
for _ in range(0,3):
print(turbo_instruct.predict(question))Positive
Positive
Positive
CPU times: user 15.9 ms, sys: 4.64 ms, total: 20.6 ms
Wall time: 1.21 sThere’s quite a big difference in the responses this time. Chat returns a full sentence every time, including an explanation on the 3rd try. Instruct returns a single word each time.
Summarising a Wikipedia page 📄
And now it’s time for our last task - summarising a Wikipedia page. And that page is going to be the one about the Laver Cup, a team tennis tournament that was played last weekend.
from langchain.document_loaders import WikipediaLoader
docs = WikipediaLoader(query="Laver Cup", load_max_docs=1).load()
docs[0].page_contentBelow is a sample of the data on that page:
'The Laver Cup is an international indoor hard court men\'s team tennis tournament between Team Europe and Team World, the latter of which is composed of players from all other continents except Europe. Usually held annually since 2017, the tournament is intended to be the Ryder Cup of the tennis world. It normally takes place two weeks after the US Open, with the location rotating between various host cities (that usually do not have an ATP Tour event); alternating yearly between European cities and cities in the rest of the world. In addition to the guaranteed participation fees which are based upon the players\' ATP rankings, each member of the winning team gets $250,000 in prize money, but the tournament itself does not count towards the players\' point totals in the ATP Tour for that year.In May 2019, the Laver Cup became an officially sanctioned ATP Tour event.'There’s a lot more after that, but let’s see how well our LLMs get on if we ask them to find 5 interesting things from the page.
prompt = PromptTemplate.from_template("Give me 5 interesting things from this text: {text}")
question = prompt.format(text=docs[0].page_content)Chat, you’re up:
print(turbo.predict(question))1. The Laver Cup is an international indoor hard court men's team tennis tournament that takes place annually since 2017.
2. The tournament is intended to be the Ryder Cup of the tennis world, modeled after the biennial golf tournament between the United States and Europe.
3. The location of the tournament rotates between various host cities, alternating yearly between European cities and cities in the rest of the world.
4. Matches during the Laver Cup tournament differ from conventional 3-set matches played on the ATP Tour, with a 10-point "match tiebreak" being played instead of a deciding final set.
5. The tournament is named after Australian tennis player Rod Laver, who is considered one of the greatest players in the sport's history and has achieved the Grand Slam twice.
CPU times: user 32.7 ms, sys: 4.44 ms, total: 37.2 ms
Wall time: 8.87 sAnd now instruct:
print(turbo_instruct.predict(question))1. The Laver Cup is named after Australian tennis legend Rod Laver, who is widely regarded as one of the greatest players in the sport's history.
2. The tournament is intended to be the equivalent of the Ryder Cup in golf, with the best players from Europe competing against the best players from the rest of the world.
3. Matches during the Laver Cup follow a unique format, with a "match tiebreak" being played if the match is tied at one set all.
4. The winning team receives a prize of $250,000, in addition to guaranteed participation fees based on players' ATP rankings.
5. The idea for the Laver Cup was inspired by Roger Federer, and was created in partnership with his management company, a Brazilian businessman, and Tennis Australia.
CPU times: user 17.3 ms, sys: 17.7 ms, total: 35 ms
Wall time: 2.11 sBoth results are pretty good and have pulled out the main points.
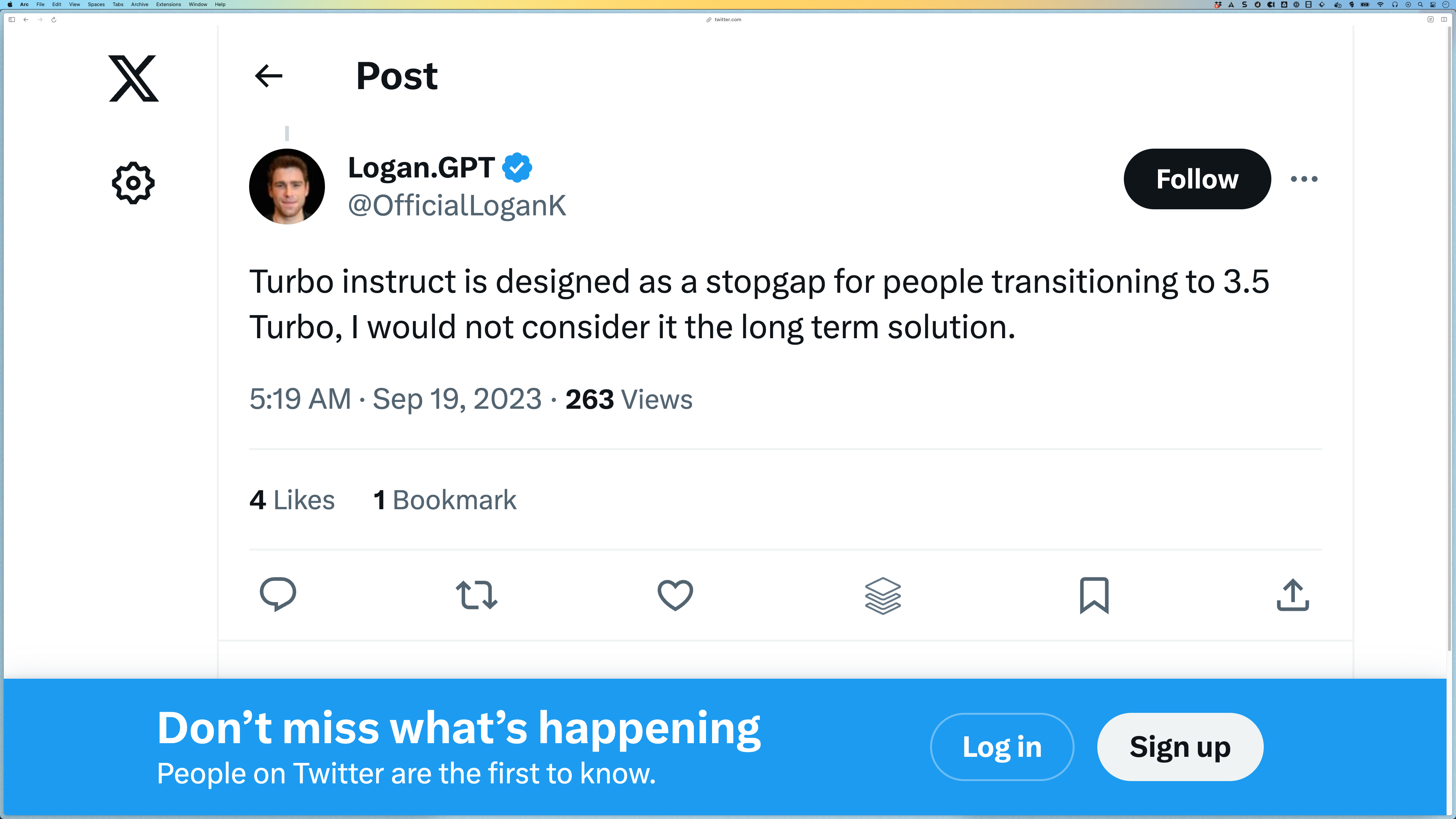
Interestingly, it seems like the Instruct model might not stick around for long if the following tweet is anything to go by:
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.