
Tennis Head to Head with DuckDB and Streamlit
In this blog post we’re going to learn how to build an application to compare the matches between two ATP tennis players. DuckDB and Streamlit will be our partners in crime for this mission.
Set up
To get started, let’s create a virtual environment:
python -m venv .venv
source .venv/bin/activateAnd now install some libraries:
pip install duckdb streamlit streamlit-searchboxAnd now let’s open a file, app.py and import the packages:
import streamlit as st
import duckdb
from streamlit_searchbox import st_searchboxNext, let’s create a DuckDB connection and import the httpfs module, which we’ll use in just a minute:
atp_duck = duckdb.connect('atp.duck.db', read_only=True)
atp_duck.sql("INSTALL httpfs")
atp_duck.sql("LOAD httpfs")Importing ATP matches
We’re going to import some matches from the ATP tennis tour using the following code:
csv_files = [
f"https://raw.githubusercontent.com/JeffSackmann/tennis_atp/master/atp_matches_{year}.csv"
for year in range(1968,2024)
]
atp_duck.execute("""
CREATE OR REPLACE TABLE matches AS
SELECT * FROM read_csv_auto($1, types={'winner_seed': 'VARCHAR', 'loser_seed': 'VARCHAR'})
""", [csv_files])We can check that the table has been populated by running the following command:
atp_duck.table("matches").project("tourney_date, winner_name, loser_name, score").limit(5)┌──────────────┬─────────────────┬─────────────────┬─────────┐
│ tourney_date │ winner_name │ loser_name │ score │
│ int64 │ varchar │ varchar │ varchar │
├──────────────┼─────────────────┼─────────────────┼─────────┤
│ 19680708 │ Douglas Smith │ Peter Ledbetter │ 6-1 7-5 │
│ 19680708 │ Louis Pretorius │ Maurice Pollock │ 6-1 6-1 │
│ 19680708 │ Cecil Pedlow │ John Mulvey │ 6-2 6-2 │
│ 19680708 │ Tom Okker │ Unknown Fearmon │ 6-1 6-1 │
│ 19680708 │ Armistead Neely │ Harry Sheridan │ 6-2 6-4 │
└──────────────┴─────────────────┴─────────────────┴─────────┘Searching for players
Now we’re going to create a Streamlit app on top of this data. Let’s start by adding a title:
st.title("ATP Head to Head")And now we’ll create a function that will let us search for players:
def search_players(search_term):
query = '''
SELECT DISTINCT winner_name AS player
FROM matches
WHERE player ilike '%' || $1 || '%'
UNION
SELECT DISTINCT loser_name AS player
FROM matches
WHERE player ilike '%' || $1 || '%'
'''
values = atp_duck.execute(query, parameters=[search_term]).fetchall()
return [value[0] for value in values]Next, we’re going to need some search boxes for the players, which is where the streamlit_searchbox library comes in handy.
left, right = st.columns(2)
with left:
player1 = st_searchbox(search_players, label="Player 1", key="player1_search")
with right:
player2 = st_searchbox(search_players, label="Player 2", key="player2_search")
st.markdown("***")
st.header(f"{player1} vs {player2}")
st.error("No matches found between these players.")We can then launch the Streamlit app by running the following command:
streamlit run app.pyIf we navigate to http://localhost:8501, we’ll see the following screen where we can search for players:
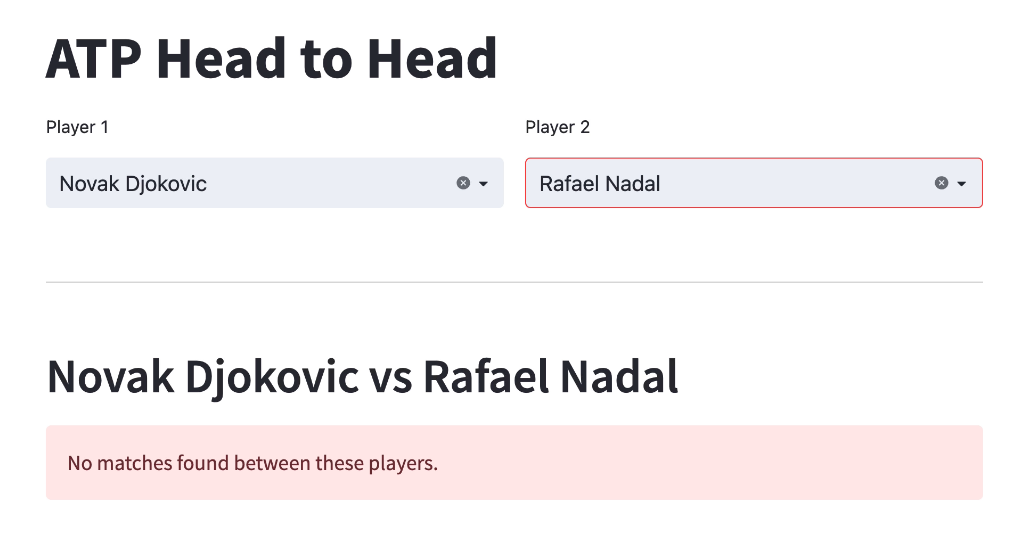
Finding matches
Let’s now update the app to find matches between players:
matches_for_players = atp_duck.execute("""
SELECT tourney_date,tourney_name, surface, round, winner_name, score
FROM matches
WHERE (loser_name = $1 AND winner_name = $2) OR
(loser_name = $2 AND winner_name = $1)
ORDER BY tourney_date DESC
""", [player1, player2]).fetchdf()Let’s also count the number of wins that each player has and we’ll update the header too:
player1_wins = matches_for_players[matches_for_players.winner_name == player1].shape[0]
player2_wins = matches_for_players[matches_for_players.winner_name == player2].shape[0]
st.header(f"{player1} {player1_wins}-{player2_wins} {player2}")If we go back to our web browser, we’ll see this:
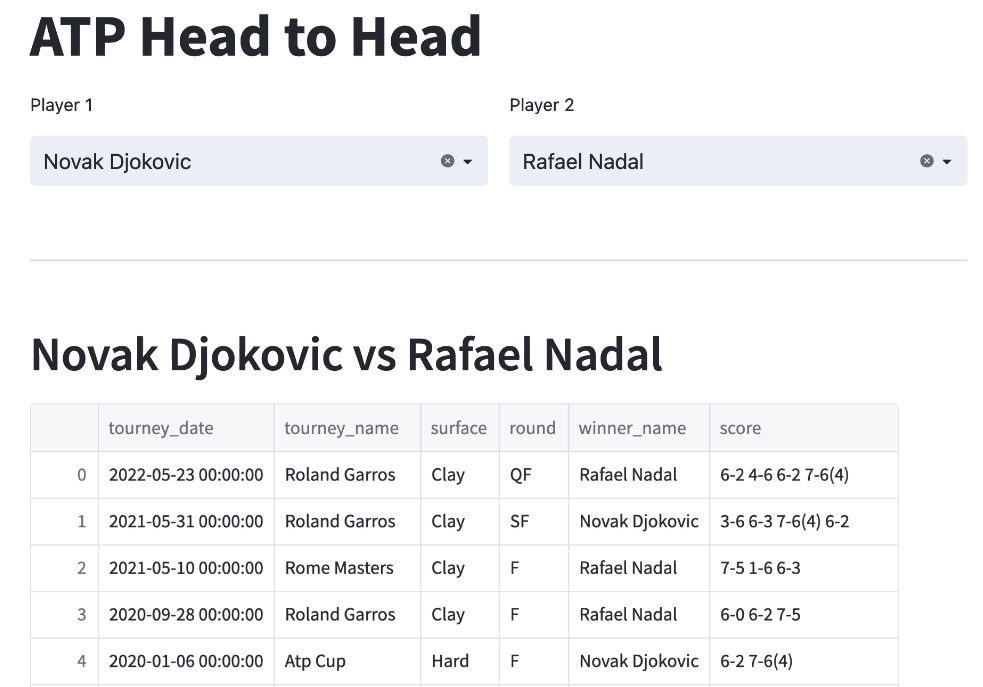
So far, so good.
Aggregation by surface and round
Let’s now do some aggregations. One of the cool things about DuckDB is that we can query a Pandas DataFrame as if its a table. The code below groups wins by round and surface:
left, right = st.columns(2)
with left:
st.markdown(f'#### By Surface')
by_surface = atp_duck.sql("""
SELECT winner_name AS player, surface, count(*) AS wins
FROM matches_for_players
GROUP BY ALL
""").fetchdf()
st.dataframe(by_surface.pivot(index="surface", columns="player" ,values="wins"))
with right:
st.markdown(f'#### By Round')
by_surface = atp_duck.sql("""
SELECT winner_name AS player, round, count(*) AS wins
FROM matches_for_players
GROUP BY ALL
""").fetchdf()
st.dataframe(by_surface.pivot(index="round", columns="player" ,values="wins"))And if we go back to the web browser:
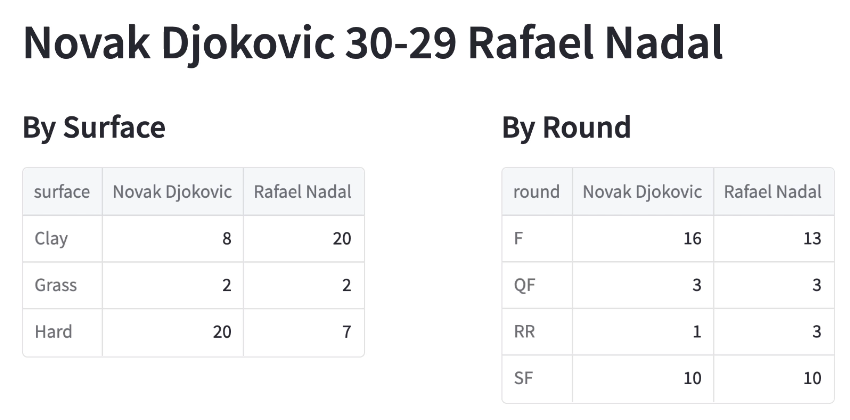
We can now search for other players and see how they’ve performed against each other.
Summary
These two tools make it super easy to quickly create data apps. The full code used in this blog post is on this Gist.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.