
Apache Pinot: Sorted indexes on offline tables
I’ve recently been learning all about Apache Pinot’s sorted forward indexes. I was initially going to explain how they work for offline and real-time tables, but the post got a bit long, so instead we’ll have two blog posts. In this one we’ll learn how sorted indexes are applied for offline tables.

Launch Components
We’re going to spin up a local instance of Pinot using the following Docker compose config:
version: '3.7'
services:
zookeeper:
image: zookeeper:3.5.6
hostname: zookeeper
container_name: zookeeper-strava
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
pinot-controller:
image: apachepinot/pinot:0.9.3
command: "StartController -zkAddress zookeeper-strava:2181 -dataDir /data"
container_name: "pinot-controller-strava"
volumes:
- ./config:/config
- ./data:/data
- ./input:/input
restart: unless-stopped
ports:
- "9000:9000"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.9.3
command: "StartBroker -zkAddress zookeeper-strava:2181"
restart: unless-stopped
container_name: "pinot-broker-strava"
ports:
- "8099:8099"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.9.3
command: "StartServer -zkAddress zookeeper-strava:2181"
restart: unless-stopped
container_name: "pinot-server-strava"
depends_on:
- pinot-brokerWe can launch all the components by running the following command:
docker-compose upCreate Schema
We’re going to explore sorted indexes using a dataset of my Strava activities. We’ll be using the following schema:
{
"schemaName": "activities",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "LONG"
},
{
"name": "altitude",
"dataType": "DOUBLE"
},
{
"name": "hr",
"dataType": "INT"
},
{
"name": "cadence",
"dataType": "INT"
},
{
"name": "rawTime",
"dataType": "INT"
},
{
"name": "distance",
"dataType": "DOUBLE"
},
{
"name": "lat",
"dataType": "DOUBLE"
},
{
"name": "lon",
"dataType": "DOUBLE"
},
{
"name": "location",
"dataType": "BYTES"
}
],
"dateTimeFieldSpecs": [{
"name": "timestamp",
"dataType": "TIMESTAMP",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}We can create the schema by running the following command:
docker exec -it pinot-controller-strava bin/pinot-admin.sh AddSchema \
-schemaFile /config/schema.json -execCreate Table
Now let’s create an offline table based on that schema.
{
"tableName": "activities_offline",
"tableType": "OFFLINE",
"segmentsConfig": {
"timeColumnName": "timestamp",
"replication": 1,
"schemaName": "activities"
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "location", "transformFunction": "toSphericalGeography(stPoint(lon, lat))" },
{"columnName": "timestamp", "transformFunction": "FromDateTime(\"time\", 'yyyy-MM-dd HH:mm:ssZ')" }
]
},
"metadata": {}
}We can create a table by running the following command:
docker exec -it pinot-controller-strava bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-offline.json \
-execWhat is a sorted index?
Before we ingest any data, let’s remind ourselves about the definition of a sorted index.
When a column is physically sorted, Pinot uses a sorted forward index with run-length encoding on top of the dictionary-encoding. Instead of saving dictionary ids for each document id, Pinot will store a pair of start and end document ids for each value.
docs.pinot.apache.org/basics/indexing/forward-index#sorted-forward-index-with-run-length-encoding
A diagram showing how a sorted index works conceptually is shown below:
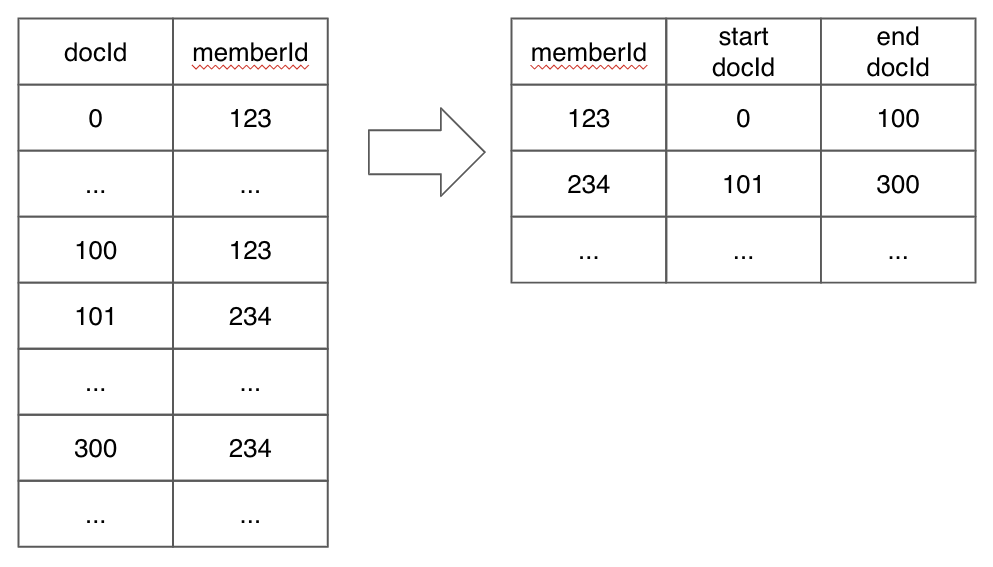
The advantage of having a sorted index is that queries that filter by that column will be more performant since the query engine doesn’t need to scan through every document to check if they match the filtering criteria.
When creating a segment Pinot does a single pass over every column to check whether the data is sorted. Columns that contain sorted data will use a sorted forward index.
|
Note
|
Sorted indexes are determined for each segment. This means that a column could be sorted in one segment, but not in another one. |
Ingesting Data
Now let’s import some data into our table. We’ll be importing data from CSV files that contain some of the lat/longs from a few of my Strava runs.
activity1.csv contains the first 5 recorded points from one run:
| lat | lon | id | distance | altitude | hr | cadence | time | rawTime |
|---|---|---|---|---|---|---|---|---|
56.265595 |
12.859432 |
2776420839 |
1.5 |
11.2 |
88 |
0 |
2019-10-09 21:25:25+00:00 |
0 |
56.26558 |
12.85943 |
2776420839 |
3.1 |
11.2 |
89 |
79 |
2019-10-09 21:25:26+00:00 |
1 |
56.265566 |
12.859438 |
2776420839 |
4.6 |
11.3 |
89 |
79 |
2019-10-09 21:25:27+00:00 |
2 |
56.265503 |
12.859488 |
2776420839 |
12.2 |
11.4 |
92 |
79 |
2019-10-09 21:25:30+00:00 |
5 |
56.265451 |
12.85952 |
2776420839 |
18.4 |
11.4 |
97 |
83 |
2019-10-09 21:25:32+00:00 |
7 |
And activity2.csv contains 5 recorded points from two different runs:
| lat | lon | id | distance | altitude | hr | cadence | time | rawTime |
|---|---|---|---|---|---|---|---|---|
-20.400632 |
57.597161 |
3120683481 |
0.0 |
284.4 |
73 |
97 |
2020-02-22 03:48:39+00:00 |
0 |
-20.400629 |
57.597158 |
3120683481 |
0.2 |
284.4 |
73 |
46 |
2020-02-22 03:48:40+00:00 |
1 |
-20.400595 |
57.597163 |
3120683481 |
4.0 |
284.3 |
73 |
46 |
2020-02-22 03:48:42+00:00 |
3 |
-20.400398 |
57.597157 |
3120683481 |
26.1 |
285.4 |
73 |
82 |
2020-02-22 03:48:49+00:00 |
10 |
-20.400278 |
57.597101 |
3120683481 |
40.7 |
284.7 |
76 |
84 |
2020-02-22 03:48:53+00:00 |
14 |
56.434599 |
12.838058 |
3092741860 |
0.8 |
12.3 |
88 |
59 |
2020-02-12 06:19:59+00:00 |
0 |
56.434604 |
12.83807 |
3092741860 |
1.8 |
12.3 |
88 |
59 |
2020-02-12 06:20:00+00:00 |
1 |
56.434625 |
12.838106 |
3092741860 |
5.0 |
12.1 |
87 |
59 |
2020-02-12 06:20:03+00:00 |
4 |
56.434717 |
12.838408 |
3092741860 |
26.5 |
11.0 |
87 |
82 |
2020-02-12 06:20:10+00:00 |
11 |
56.434718 |
12.838463 |
3092741860 |
29.9 |
10.8 |
91 |
82 |
2020-02-12 06:20:11+00:00 |
12 |
docker exec \
-it pinot-controller-strava bin/pinot-admin.sh LaunchDataIngestionJob \
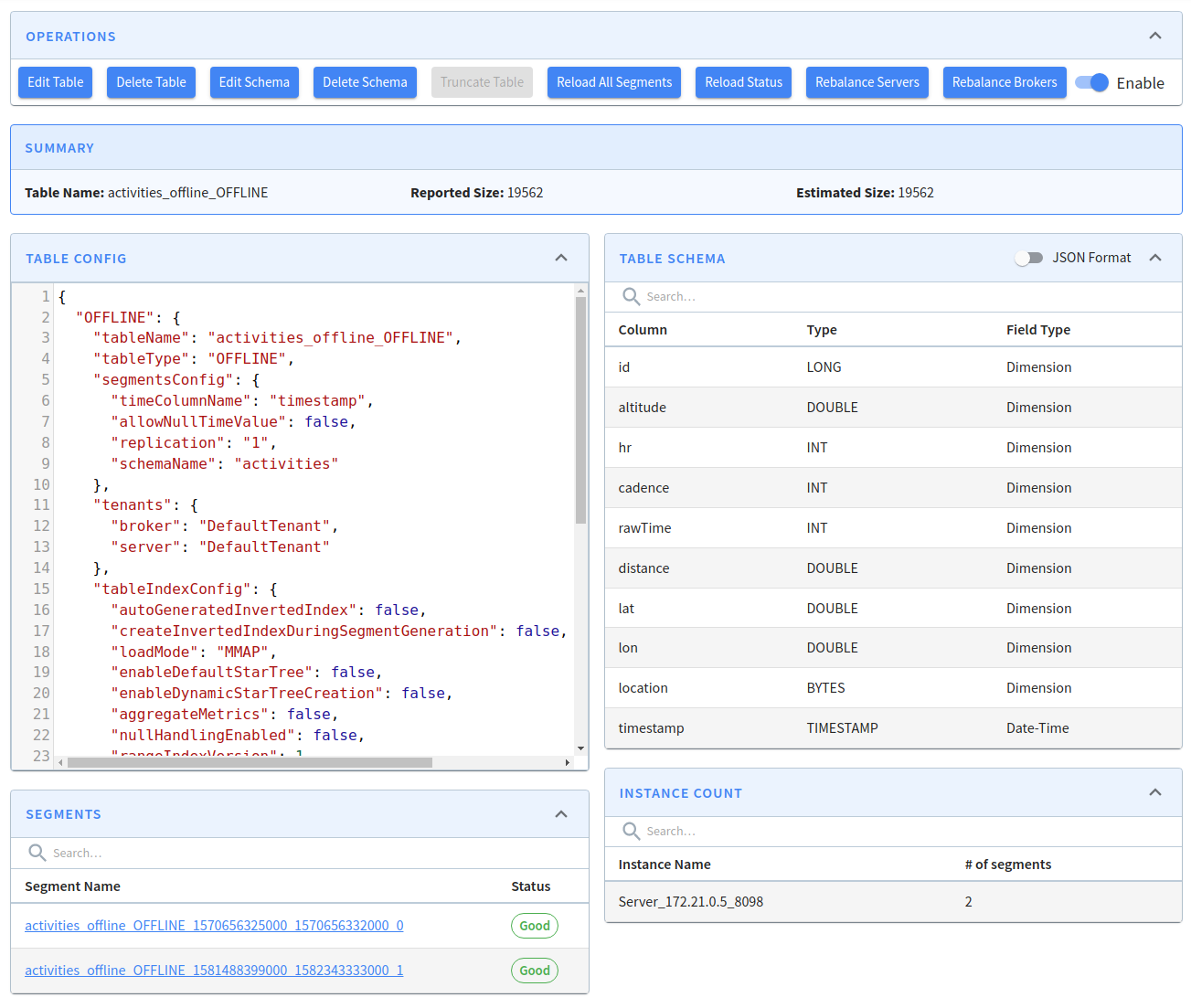
-jobSpecFile /config/job-spec.ymlOnce the job has run we’ll have two segments in our table, which we can see by navigating to http://localhost:9000/#/tenants/table/activities_offline_OFFLINE. You should see something like the following:
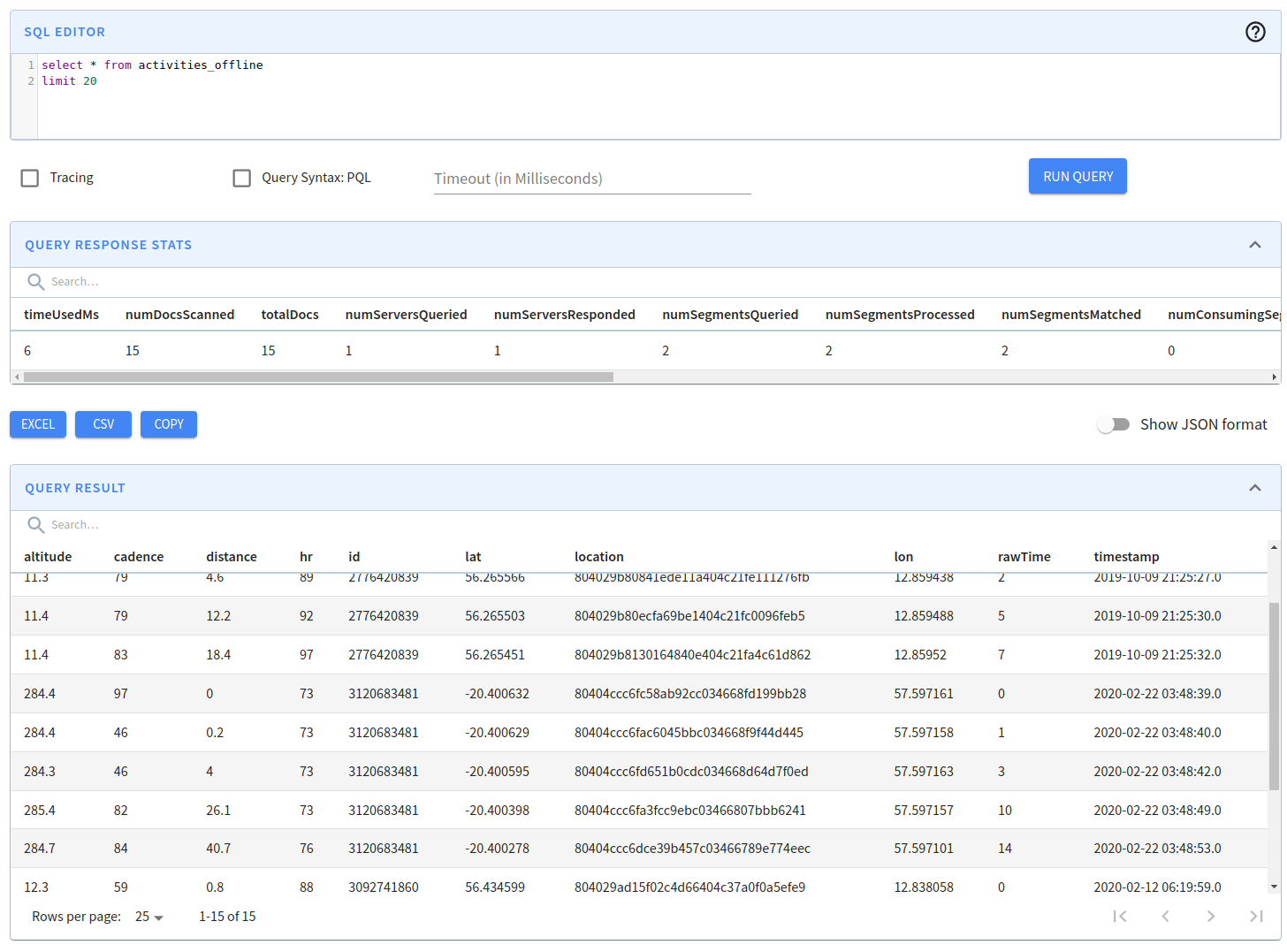
If the segments are showing up we can be reasonably sure that the import has worked, but let’s also navigate to http://localhost:9000/#/query to make sure. If we run a query against the table, we should see something like the following:
Checking sorted status
Next, we’re going to check on the sorted status of the columns in each segment.
First let’s collect all the columns in the activities schema:
export queryString=`curl -X GET "http://localhost:9000/schemas/activities" -H "accept: application/json" 2>/dev/null |
jq -r '[.dimensionFieldSpecs,.dateTimeFieldSpecs | .[] | .name ] | join("&columns=")'`And now let’s call the getServerMetaData endpoint and filter the response to get the segment name, input file, and column names with sorted status:
curl -X GET "http://localhost:9000/segments/activities_offline/metadata?columns=${queryString}" \
-H "accept: application/json" 2>/dev/null |
jq -c '.[] | select(.columns != null) | {
segment: .segmentName,
importedFrom: .custom ["input.data.file.uri"],
columns: .columns | map({(.columnName): .sorted})
}'If we run this command, we’ll see the following output:
{
"segment": "activities_offline_OFFLINE_1581488399000_1582343333000_1",
"importedFrom": "file:/input-blog/activity2.csv",
"columns": [
{"altitude": false},
{"distance": false},
{"hr": false},
{"lon": false},
{"cadence": false},
{"rawTime": false},
{"location": false},
{"id": false},
{"lat": true},
{"timestamp": false}
]
}
{
"segment": "activities_offline_OFFLINE_1570656325000_1570656332000_0",
"importedFrom": "file:/input-blog/activity1.csv",
"columns": [
{"altitude": true},
{"distance": true},
{"hr": true},
{"lon": false},
{"cadence": true},
{"rawTime": true},
{"location": false},
{"id": true},
{"lat": false},
{"timestamp": true}
]
}|
Note
|
I have formatted the JSON output using the FracturedJson tool in the web browser to make it easier to read. |
From this output we can see that the segment created from activity1.csv has many more sorted columns than the one created from activity2.csv.
The only column that was explicitly sorted is timestamp, but rawTime and distance are also sorted because they are correlated with timestamp within an activity.
For the activity2.csv segment the only sorted column is lat, which is sorted by chance more than anything else!
None of the other columns are sorted.
Summary
So that’s the end of this first post explaining how sorted indexes work in Apache Pinot. Hopefully it all made sense, but if not feel free to ask any questions on the Pinot Community Slack.
In our next post we’ll learn how sorted indexes work on real-time tables.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.