
Apache Pinot: Exploring indexing techniques on Chicago Crimes
In Neha Pawar’s recent blog post, What Makes Apache Pinot fast?, she summarises it with the following sentence:
At the heart of the system, Pinot is a columnar store with several smart optimizations that can be applied at various stages of the query by the different Pinot components. Some of the most commonly used and impactful optimizations are data partitioning strategies, segment assignment strategies, smart query routing techniques, a rich set of indexes for filter optimizations, and aggregation optimization techniques.
https://www.startree.ai/blogs/what-makes-apache-pinot-fast-chapter-1/
In this blog post we’re going to explore one of these techniques, the indexes used for filter optimizations. We’ll do this with the help of one of my favourite datasets, the Chicago Crimes data set, which contains just over 7 million reported incidents of crime since 2001.

How will we assess the impact of indexes?
Before we look at this dataset, I want to recommend a video that Apache Pinot co-author Kishore Gopalakrishna recorded in December 2020, in which he explains how to know whether indexes that you’ve added are working.
Kishore goes through different query meta data properties that get returned, as shown in the screenshot below:
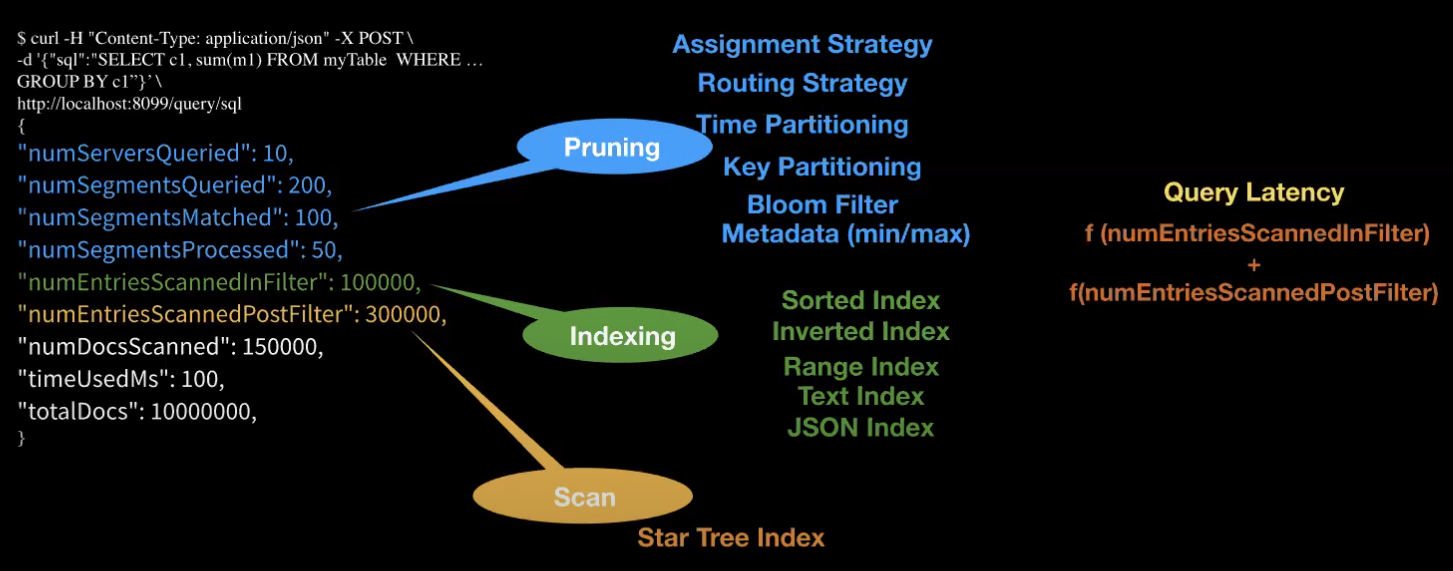
Each of the properties is impacted by the smart optimisations that Neha mentioned in her blog post, but here we’ll be focusing on numEntriesScannedInFilter.
Let’s get to it!
Setup
We’re going to spin up a local instance of Pinot using the following Docker compose config:
version: '3.7'
services:
zookeeper:
image: zookeeper:3.5.6
hostname: zookeeper
container_name: manual-zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
pinot-controller:
image: apachepinot/pinot:0.9.0
command: "StartController -zkAddress manual-zookeeper:2181"
container_name: "manual-pinot-controller"
volumes:
- ./config:/config
- ./data:/data
restart: unless-stopped
ports:
- "9000:9000"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.9.0
command: "StartBroker -zkAddress manual-zookeeper:2181"
restart: unless-stopped
container_name: "manual-pinot-broker"
volumes:
- ./config:/config
- ./data:/data
ports:
- "8099:8099"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.9.0
command: "StartServer -zkAddress manual-zookeeper:2181"
restart: unless-stopped
container_name: "manual-pinot-server"
volumes:
- ./config:/config
- ./data:/data
depends_on:
- pinot-brokerData
The Chicago Crimes dataset is available as a CSV file that contains just over 7 million crimes committed in Chicago from 2001 until today. A subset of the data is shown below:
Add Table
We’re going to import the data into a Pinot table.
First we’ll create a schema that defines the columns, types, and data types:
{
"schemaName": "crimes",
"dimensionFieldSpecs": [
{
"name": "ID",
"dataType": "INT"
},
{
"name": "CaseNumber",
"dataType": "STRING"
},
{
"name": "Block",
"dataType": "STRING"
},
{
"name": "IUCR",
"dataType": "STRING"
},
{
"name": "PrimaryType",
"dataType": "STRING"
},
{
"name": "Arrest",
"dataType": "BOOLEAN"
},
{
"name": "Domestic",
"dataType": "BOOLEAN"
},
{
"name": "Beat",
"dataType": "STRING"
},
{
"name": "District",
"dataType": "STRING"
},
{
"name": "Ward",
"dataType": "STRING"
},
{
"name": "CommunityArea",
"dataType": "STRING"
},
{
"name": "FBICode",
"dataType": "STRING"
},
{
"name": "Latitude",
"dataType": "DOUBLE"
},
{
"name": "Longitude",
"dataType": "DOUBLE"
}
],
"dateTimeFieldSpecs": [{
"name": "Date",
"dataType": "STRING",
"format" : "1:SECONDS:SIMPLE_DATE_FORMAT:MM/dd/yyyy HH:mm:ss a",
"granularity": "1:HOURS"
}]
}And now a table config:
{
"tableName": "crimes",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": 1
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"nullHandlingEnabled": true,
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "CaseNumber", "transformFunction": "\"Case Number\"" },
{"columnName": "PrimaryType", "transformFunction": "\"Primary Type\"" },
{"columnName": "CommunityArea", "transformFunction": "\"Community Area\"" },
{"columnName": "FBICode", "transformFunction": "\"FBI Code\"" }
]
},
"metadata": {}
}We’re mostly using the defaults here, the only unusual thing that we’re doing is specifying some transformConfigs to take care of column names containing spaces.
If you want to learn more about these transformations, see my blog post on Importing CSV files with columns containing spaces.
We can create the table by running the following command:
docker exec -it manual-pinot-controller bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-basic.json \
-schemaFile /config/schema.json -execImport CSV file
Next we’re going to import the CSV file. To do this we’ll define the following ingestion job spec:
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/data'
includeFileNamePattern: 'glob:**/Crimes_-_2001_to_Present.csv'
outputDirURI: '/opt/pinot/data/crimes'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'crimes'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'docker exec \
-it manual-pinot-controller bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile /config/job-spec.ymlQuerying Pinot
We’re going to run queries against Pinot using the Query Console of the Pinot Data Explorer. You can access this at http://localhost:9000/#/query.
We can write SQL queries in the SQL Editor and then run them by pressing 'Cmd + Enter'. We’ll then toggle "Show JSON Format" so that we can see the meta data of our query. You can see a screenshot below:
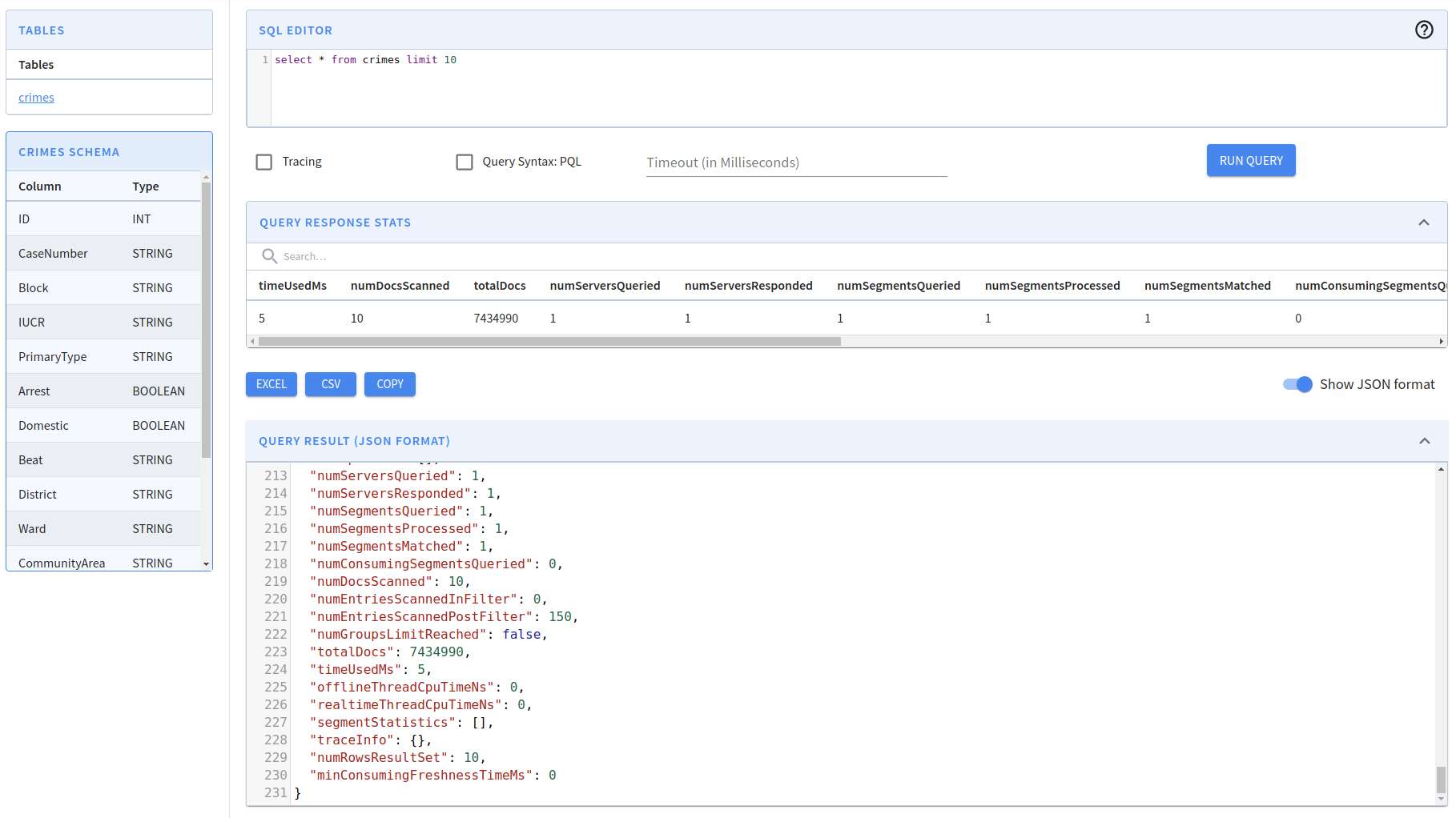
{
"numServersQueried": 1,
"numServersResponded": 1,
"numSegmentsQueried": 1,
"numSegmentsProcessed": 1,
"numSegmentsMatched": 1,
"numConsumingSegmentsQueried": 0,
"numDocsScanned": 10,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 150,
"numGroupsLimitReached": false,
"totalDocs": 7434990,
"timeUsedMs": 5
}From this meta data, the main thing that we learn is that there are 7,434,990 documents/rows in this table In the rest of this post we’re only going to focus on the following properties:
{
"numDocsScanned": 10,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 150,
"timeUsedMs": 5
}We’re going to analyse a query that checks the equality of one column.
Forward index
Let’s start with a query that counts the number of crimes committed where an arrest has happened:
select count(*)
from crimes
WHERE Beat = '1434'{
"numDocsScanned": 27973,
"numEntriesScannedInFilter": 7434990,
"numEntriesScannedPostFilter": 0,
"timeUsedMs": 71
}From these values we can see that the SQL engine has had to scan every document to check its value for the Arrest column and that there were 27,973 documents that matched this predicate.
Forward index + Inverted Index on Beat column
One optimisation that we can do is to add the Arrest column as an inverted index.
With an inverted index, Pinot keeps a map from each unique value to a bitmap of rows, meaning that we’ll no longer have to scan all the values in these column.
We can add an inverted index as tableIndexConfig.invertedIndexColumns, as shown in the following table config:
{
"tableName": "crimes_inverted",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": 1
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP",
"invertedIndexColumns": [
"Beat"
]
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "CaseNumber", "transformFunction": "\"Case Number\"" },
{"columnName": "PrimaryType", "transformFunction": "\"Primary Type\"" },
{"columnName": "CommunityArea", "transformFunction": "\"Community Area\"" },
{"columnName": "FBICode", "transformFunction": "\"FBI Code\"" }
]
},
"metadata": {}
}We could apply that to our existing crimes table, but to make it easier to compare the different techniques we’re going to create a new table for each technique.
Run the following command to add a new table crimes_inverted based on this table config:
docker exec -it manual-pinot-controller bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-basic.json \
-schemaFile /config/schema.json -execNow we’re going to import the same CSV into this table, using the following ingestion job spec:
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/data'
includeFileNamePattern: 'glob:**/Crimes_beat_sorted.csv'
outputDirURI: '/opt/pinot/data/crimes_inverted'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'crimes_inverted'
schemaURI: 'http://localhost:9000/tables/crimes/schema'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'Because our table name and schema name are different we need to explicitly specify the schemaURI, otherwise it will try to look for a non existent schema at http://localhost:9000/tables/crimes_inverted/schema.
We’re also using a different outputDirURI than for the previous job spec.
We need to do this so that the segments from the crimes table don’t get included in the crimes_inverted table.
Run the ingestion job:
docker exec \
-it manual-pinot-controller bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile /config/job-spec-inverted.ymlOnce the job has finished, we can run our query again:
select count(*)
from crimes_inverted
WHERE Beat = '1434'We should see the following output:
{
"numDocsScanned": 1992434,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 0,
"timeUsedMs": 3,
}Our query is almost 20x faster than it was before and the numEntriesScannedInFilter is down to 0.
Sorted Forward Index on Beat column
We could instead create a sorted index. With a sorted index, Pinot keeps a mapping from unique values to start and end document/row ids.
|
Note
|
The sorted (forward) index for the |
A table can only have one sorted column and, for offline data ingestion the data in that column must be sorted before we ingest it into Pinot. Since the CSV file isn’t too big, we can sort it using Pandas and write the sorted data to a new CSV file, using the following script:
import pandas as pd
df = pd.read_csv("data/Crimes_-_2001_to_Present.csv", dtype=object)
df.sort_values(by=["Beat"]).to_csv("data/Crimes_beat_sorted.csv", index=False)Now let’s create a new table, which we’ll call crimes_sorted:
{
"tableName": "crimes_sorted",
"tableType": "OFFLINE",
"segmentsConfig": {
"replication": 1
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"loadMode": "MMAP",
"sortedColumn": [
"Beat"
]
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "CaseNumber", "transformFunction": "\"Case Number\"" },
{"columnName": "PrimaryType", "transformFunction": "\"Primary Type\"" },
{"columnName": "CommunityArea", "transformFunction": "\"Community Area\"" },
{"columnName": "FBICode", "transformFunction": "\"FBI Code\"" }
]
},
"metadata": {}
}Run the following command to add a new table crimes_sorted based on this table config:
docker exec -it manual-pinot-controller bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-sorted-index.json \
-schemaFile /config/schema.json -execAnd finally let’s create an ingestion job spec to import the CSV file:
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/data'
includeFileNamePattern: 'glob:**/Crimes_beat_sorted.csv'
outputDirURI: '/opt/pinot/data/crimes-sorted'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'crimes_sorted'
schemaURI: 'http://localhost:9000/tables/crimes/schema'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'Again we need to specify the schemaURI since our table name and schema name differ.
We can ingest the data by running the following command:
docker exec \
-it manual-pinot-controller bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile /config/job-spec-sorted.ymlOnce the job has finished, we can run our query again:
select count(*)
from crimes_sorted
WHERE Beat = '1434'We should see the following output:
{
"numDocsScanned": 27973,
"numEntriesScannedInFilter": 0,
"numEntriesScannedPostFilter": 0,
"timeUsedMs": 3,
}Again we don’t have any numEntriesScannedInFilter, but the query time isn’t all that different to when we used the inverted index.
Space vs Time Trade-off
The disadvantage of adding extra indexes is that they take up more space on disk. We can check how much space each of our tables consumes by running the following:
{
printf "%-20s%-12s\n" "Table" "Bytes"
for table in 'crimes' 'crimes_sorted' 'crimes_inverted'; do
size=`curl -X GET "http://localhost:9000/tables/${table}/size?detailed=true" -H "accept: application/json" 2>/dev/null | jq '.reportedSizeInBytes'`;
printf "%-20s%-12s\n" ${table} ${size};
done
}Table Bytes
crimes 340797740
crimes_sorted 332435811
crimes_inverted 355940552Looking at these numbers, we can see that:
-
The
crimes_invertedtable takes up the most space, but we shouldn’t be too surprised because this is the only table that has two indexes for theBeatcolumn: a default forward index and a inverted index. -
The sorted forward index used by the
crimes_sortedtable for theBeatcolumn actually takes up less space than the unsorted forward index that’s used by default.
If we want to see a break down of the space usage, we can do that by executing the following command:
for table in 'crimes' 'crimes_sorted' 'crimes_inverted'; do
printf "Table: $table\n"
docker exec -it manual-pinot-server ls -l /tmp/data/pinotServerData/${table}_OFFLINE/${table}_OFFLINE_0/v3/
printf "\n"
doneTable: crimes
total 332824
-rw-r--r-- 1 root root 340783919 Nov 30 12:11 columns.psf
-rw-r--r-- 1 root root 16 Nov 30 12:11 creation.meta
-rw-r--r-- 1 root root 2335 Nov 30 12:11 index_map
-rw-r--r-- 1 root root 11470 Nov 30 12:11 metadata.properties
Table: crimes_sorted
total 324656
-rw-r--r-- 1 root root 332421987 Nov 30 14:02 columns.psf
-rw-r--r-- 1 root root 16 Nov 30 14:02 creation.meta
-rw-r--r-- 1 root root 2331 Nov 30 14:02 index_map
-rw-r--r-- 1 root root 11477 Nov 30 14:02 metadata.properties
Table: crimes_inverted
total 347612
-rw-r--r-- 1 root root 355926631 Nov 30 13:51 columns.psf
-rw-r--r-- 1 root root 16 Nov 30 13:16 creation.meta
-rw-r--r-- 1 root root 2417 Nov 30 13:51 index_map
-rw-r--r-- 1 root root 11488 Nov 30 13:16 metadata.propertiesConclusion
In this post we’ve taken a brief look at two of Apache Pinot’s indexing techniques and applied them to a query that counted the number of crimes on a specific beat. Our query runs 20x faster and we only had a small space increase when using an inverted index and actually saved space with the sorted forward index.
In our next post we’ll look at other indexes and apply them to queries that filter on more than one field.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.