
Neo4j Graph Data Science 1.5: Exploring the Speaker-Listener LPA Overlapping Community Detection Algorithm
The Neo4j Graph Data Science Library provides efficiently implemented, parallel versions of common graph algorithms for Neo4j, exposed as Cypher procedures. It recently published version 1.5, which introduces some fun new algorithms.
In this blog post, we’re going to explore the newly added Speaker-Listener Label Propagation algorithm with the help of a twitter dataset.
Launching Neo4j
We’re going to run Neo4j with the Graph Data Science Library using the following Docker Compose configuration:
version: '3.7'
services:
neo4j:
image: neo4j:4.2.3-enterprise
container_name: "neo4j4.2-gds1.5-exploration"
volumes:
- ./plugins-4.2:/plugins
- ./data-4.2:/data
ports:
- "7474:7474"
- "7687:7687"
environment:
- NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
- NEO4J_AUTH=neo4j/neo
- NEO4JLABS_PLUGINS=["apoc", "graph-data-science"]If you want to follow along with the examples used in the blog post, you can copy the configuration above to a file titled docker-compose.yml
We can now launch the Neo4j server by running the following command:
docker-compose upAfter we’ve launched that command, we need to wait until we see the following output:
neo4j4.2-gds1.5-exploration | 2021-02-03 21:39:15.346+0000 INFO Bolt enabled on 0.0.0.0:7687.
neo4j4.2-gds1.5-exploration | 2021-02-03 21:39:16.053+0000 INFO Remote interface available at http://localhost:7474/
neo4j4.2-gds1.5-exploration | 2021-02-03 21:39:16.053+0000 INFO Started.Importing a Twitter Social Graph
We’re going to import the Twitter Social Graph that I used in the Finding influencers and communities in the Graph Community blog post that I wrote in 2019.
Let’s first connect to Neo4j using the Cypher Shell:
docker exec -it neo4j4.2-gds1.5-exploration bin/cypher-shell -u neo4j -p neoConnected to Neo4j using Bolt protocol version 4.2 at neo4j://localhost:7687 as user neo4j.
Type :help for a list of available commands or :exit to exit the shell.
Note that Cypher queries must end with a semicolon.
neo4j@neo4j>The data for the Twitter Social Graph graph is available as a set of JSON lines files, which we can find at https://github.com/neo4j-devtools/neuler/blob/master/sample-data/twitter/users.json. Below is an example of one line from this file:
{"user":{"followers":2793,"following":1121,"name":"Synechron","bio":"Synechron is a leading Digital IT Consulting firm Accelerating Digital initiatives for banks, asset managers & insurance companies around the world.","id":625428620,"username":"Synechron"},"following":[],"followers":[50230435,117780256,856240505826496513,31112812,999543859398037504,873919885096693761,61085452,75043311,268191768]}We’re going to use some APOC procedures to convert these JSON files into the following graph structure:

Let’s first create a new database and setup some constraints to make sure we don’t end up with duplicates:
CREATE OR REPLACE DATABASE twitterblogpost;
:use twitterblogpost;
CREATE CONSTRAINT ON(u:User) ASSERT u.id IS unique;Now we’ll import the data:
WITH "https://github.com/neo4j-apps/neuler/raw/master/sample-data/twitter/users.json" AS url
CALL apoc.load.json(url)
YIELD value
MERGE (u:User {id: value.user.id })
SET u += value.user
WITH u, value
CALL {
WITH u, value
UNWIND value.following AS following
MERGE (f1:User {id: following})
MERGE (u)-[:FOLLOWS]->(f1)
RETURN count(*) AS followingCount
}
CALL {
WITH u, value
UNWIND value.followers AS follower
MERGE (f2:User {id: follower})
MERGE (u)<-[:FOLLOWS]-(f2)
RETURN count(*) AS followersCount
}
RETURN count(*) AS users;| users |
|---|
6526 |
We can see a Neo4j Browser visualisation of the import graph in the diagram below:

Speaker Listener Label Propagation Algorithm
The Speaker Listener Label Propagation (SLLPA) algorithm is a variation of the Label Propagation Algorithm, where instead of returning one community per node, it can return multiple communities per node. We can alternatively say that the SLLPA algorithm detects overlapping communities.
We can find out the name of the SLLPA procedures in the GDS library by running the following query:
CALL gds.list("sllpa")
YIELD name, description;| name | description |
|---|---|
"gds.alpha.sllpa.mutate" |
"The Speaker Listener Label Propagation algorithm is a fast algorithm for finding overlapping communities in a graph." |
"gds.alpha.sllpa.mutate.estimate" |
"Returns an estimation of the memory consumption for that procedure." |
"gds.alpha.sllpa.stats" |
"The Speaker Listener Label Propagation algorithm is a fast algorithm for finding overlapping communities in a graph." |
"gds.alpha.sllpa.stats.estimate" |
"Returns an estimation of the memory consumption for that procedure." |
"gds.alpha.sllpa.stream" |
"The Speaker Listener Label Propagation algorithm is a fast algorithm for finding overlapping communities in a graph." |
"gds.alpha.sllpa.stream.estimate" |
"Returns an estimation of the memory consumption for that procedure." |
"gds.alpha.sllpa.write" |
"The Speaker Listener Label Propagation algorithm is a fast algorithm for finding overlapping communities in a graph." |
"gds.alpha.sllpa.write.estimate" |
"Returns an estimation of the memory consumption for that procedure." |
We’re going to use the gds.alpha.sllpa.write procedure.
This algorithm runs the algorithm against an in-memory projected graph and stores the results as node properties.
The in-memory graph that we’re going to use will consist of USER nodes and the FOLLOWS relationships between them.
We’ll ignore the direction of the FOLLOWS relationship when computing communities.
We can do this by running the following query:
CALL gds.alpha.sllpa.write({
nodeProjection: "User",
relationshipProjection: {
FOLLOWS: {
orientation: 'UNDIRECTED'
}
},
maxIterations: 20
})
YIELD nodePropertiesWritten, ranIterations, writeMillis, createMillis, computeMillis;| nodePropertiesWritten | ranIterations | writeMillis | createMillis | computeMillis |
|---|---|---|---|---|
6526 |
20 |
20 |
14 |
478 |
By default, results are written to the pregel_communityids property.
We can have a look at some of these values by running the following query:
MATCH (user:User)
RETURN user.username, user.pregel_communityIds
LIMIT 5;| user.username | user.pregel_communityIds |
|---|---|
"webmink" |
[119] |
"Synechron" |
[119] |
"flablog" |
[185, 119] |
"didierdaglinckx" |
[3] |
"DailyPythonInfo" |
[119] |
webmink, Synechron, didierdaglinckx, and DailyPythonInfo all belong to only one community, whereas flablog belongs to a couple of communities.
How many users belong to multiple communities?
I wonder how many other users belong to multiple communities? We can find out by running the following query:
MATCH (u:User)
WITH count(*) AS totalCount
MATCH (u:User)
WITH totalCount, size(u.pregel_communityIds) as communities, count(*) AS count
RETURN communities, count, round(count * 100.0 / totalCount, 2) AS percentage
ORDER BY communities;| communities | count | percentage |
|---|---|---|
1 |
5703 |
87.39 |
2 |
801 |
12.27 |
3 |
22 |
0.34 |
We can also use Niels de Jong’s NeoDash to create a quick bar chart of these results:
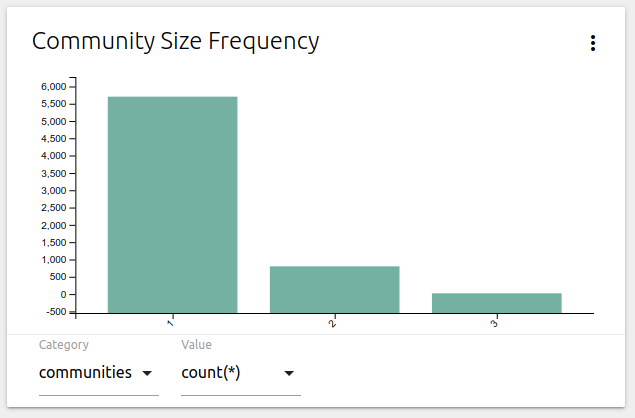
A massive majority of nodes have only one community, just over 10% have two communities, and only 0.3% fit into three communities.
Create community graph
Let’s have a look at the communities in more detail. We’re going to add the graph structure coloured in red in the diagram below:

We’ll first create a unique constraint on the id property for the Community label:
CREATE CONSTRAINT ON (c:Community) ASSERT c.id IS UNIQUE;And now we can create a Community node for each community and an IN_COMMUNITY relationship from each user to the communities that they belong to:
MATCH (u:User)
UNWIND u.pregel_communityIds AS communityId
MERGE (c:Community {id: communityId})
MERGE (u)-[:IN_COMMUNITY]->(c);0 rows available after 299 ms, consumed after another 0 ms
Added 1028 nodes, Created 7371 relationships, Set 1028 properties, Added 1028 labelsWe can see a Neo4j Browser visualisation of the new graph structure in the diagram below:

Find important users
I find that the best way to do community analysis is to look at the important nodes that belong to each one. We can compute the important nodes by running the PageRank algorithm, as shown below:
CALL gds.pageRank.write({
nodeProjection: "User",
relationshipProjection: "FOLLOWS",
maxIterations: 20,
writeProperty: "pagerank"
})
YIELD writeMillis, nodePropertiesWritten, ranIterations,
postProcessingMillis, createMillis, computeMillis;| writeMillis | nodePropertiesWritten | ranIterations | postProcessingMillis | createMillis | computeMillis |
|---|---|---|---|---|---|
35 |
6526 |
20 |
0 |
9 |
111 |
Each of the User nodes now has a pagerank property.
Individual communities
We can use this property as part of a query to find the top 5 users per community, as shown below:
MATCH (:User) WITH count(*) AS allUsers
MATCH (c:Community)<-[:IN_COMMUNITY]-(u:User)
WITH allUsers, c, u
ORDER BY c, u.pagerank DESC
WITH allUsers, c, collect(u) AS users
RETURN c.id, size(users) AS users,
round(size(users)*100.0 / allUsers, 3) AS percentage,
[u IN users | u {.username, score: round(u.pagerank, 3)}][..5] AS topUsers
ORDER BY size(users) DESC
LIMIT 10;| c.id | users | percentage | topUsers |
|---|---|---|---|
119 |
3960 |
60.68 |
[{score: 46.822, username: "TechCrunch"}, {score: 33.246, username: "awscloud"}, {score: 22.015, username: "hmason"}, {score: 20.332, username: "kellabyte"}, {score: 17.816, username: "KirkDBorne"}] |
157 |
1152 |
17.652 |
[{score: 46.105, username: "neo4j"}, {score: 25.847, username: "emileifrem"}, {score: 23.085, username: "mesirii"}, {score: 15.83, username: "GraphConnect"}, {score: 14.879, username: "jimwebber"}] |
34 |
636 |
9.746 |
[{score: 14.666, username: "jessitron"}, {score: 10.754, username: "WardCunningham"}, {score: 9.464, username: "springrod"}, {score: 8.98, username: "starbuxman"}, {score: 8.528, username: "garybernhardt"}] |
144 |
212 |
3.249 |
[{score: 12.834, username: "danbri"}, {score: 6.759, username: "ontotext"}, {score: 6.198, username: "StardogHQ"}, {score: 6.113, username: "kidehen"}, {score: 5.223, username: "juansequeda"}] |
22 |
96 |
1.471 |
[{score: 3.431, username: "_wald0"}, {score: 2.753, username: "Cyb3rWard0g"}, {score: 2.582, username: "ItsReallyNick"}, {score: 2.302, username: "TheColonial"}, {score: 1.86, username: "DanielGallagher"}] |
91 |
46 |
0.705 |
[{score: 0.358, username: "margueritegg"}, {score: 0.3, username: "budejicky"}, {score: 0.26, username: "politicalHEDGE"}, {score: 0.246, username: "420Cyber"}, {score: 0.237, username: "CryptoTrackerBt"}] |
81 |
33 |
0.506 |
[{score: 2.447, username: "vaaaaanquish"}, {score: 0.903, username: "snow_rabbit"}, {score: 0.841, username: "Moririn47273285"}, {score: 0.604, username: "OSS_News"}, {score: 0.591, username: "shiget84"}] |
1747 |
28 |
0.429 |
[{score: 0.278, username: "tech__lib"}, {score: 0.15, username: "niturkan"}, {score: 0.15, username: "djoman_fidele"}, {score: 0.15, username: "scholarsuniv"}, {score: 0.15, username: "seantabatabai"}] |
250 |
27 |
0.414 |
[{score: 1.666, username: "anwagnerdreas"}, {score: 1.243, username: "patrick_sahle"}, {score: 1.097, username: "Mareike2405"}, {score: 1.088, username: "AndreasKuczera"}, {score: 1.04, username: "fthierygeo"}] |
1160 |
22 |
0.337 |
[{score: 2.357, username: "Silkjaer"}, {score: 1.681, username: "Hodor"}, {score: 1.414, username: "HammerToe"}, {score: 1.262, username: "XrpCenter"}, {score: 1.036, username: "DevNullProd"}] |
-
Community 119 looks like it could be a Data Science cluster, but it also has very popular tech accounts.
-
Community 157 is full of Neo4j folks
-
Community 34 has people that are big in the Spring world
-
Community 22 looks like it has people doing security work
-
Community 144 is all about the semantic web and triple stores
Overlapping communities
Let’s now have a look at community overlap. We can compute the biggest overlaps between communities, by running the following query:
MATCH (c1:Community)<-[:IN_COMMUNITY]-(u)-[:IN_COMMUNITY]->(c2:Community)
WHERE id(c1) < id(c2)
WITH c1, c2, count(*) AS count
ORDER BY count DESC
LIMIT 20
CALL apoc.create.vRelationship(c1, "COMMON", {count: count}, c2)
YIELD rel
RETURN c1, rel, c2;We can see the results of running this query in the Neo4j Browser below:

The biggest overlap is between community 119 (Data Science/Popular Tech) and communities 34 (Spring) and 157 (Neo4j). The absolute overlap numbers between communities are much lower after that. We can compute similarity scores between the communities using the Jaccard Similarity algorithm, as shown below:
MATCH (c1:Community), (c2:Community)
WHERE id(c1) < id(c2)
WITH c1, c2, gds.alpha.similarity.jaccard(
[(c1)<-[:IN_COMMUNITY]-(u) | id(u)],
[(c2)<-[:IN_COMMUNITY]-(u) | id(u)]) AS score
WHERE score > 0
MERGE (c1)-[similar:SIMILAR]-(c2)
SET similar.score = score;This query computes the similarity betweeen Community nodes based on the users that they have in common and then creates a SIMILAR relationship between those Community nodes.
We can see the results of running this query in the Neo4j Browser below:

From this visualisation we can see that the overlap is tiny between community 119 and the others. The biggest similarity is 0.05 between community 119 and community 34, but the other similarities are much smaller. We can create a table of similarities by running the following query:
MATCH (c1:Community)<-[:IN_COMMUNITY]-(u)-[:IN_COMMUNITY]->(c2:Community)
WHERE id(c1) < id(c2)
WITH c1, c2, count(*) AS count
ORDER BY count DESC
LIMIT 20
MATCH (c1)-[similar:SIMILAR]-(c2)
RETURN c1.id, c2.id, count, round(similar.score, 3) AS score
ORDER BY score DESC
LIMIT 10;| c1.id | c2.id | count | score |
|---|---|---|---|
498 |
107 |
3 |
1.0 |
119 |
34 |
228 |
0.052 |
119 |
157 |
187 |
0.038 |
119 |
91 |
46 |
0.012 |
157 |
34 |
20 |
0.011 |
119 |
22 |
36 |
0.009 |
119 |
144 |
36 |
0.009 |
119 |
1747 |
28 |
0.007 |
157 |
144 |
8 |
0.006 |
119 |
81 |
21 |
0.005 |
There’s 100% overlap in the users in community 498 and community 107, but those communities only have 3 nodes! The general amount of overlap is very small.
Next we’re going to have a look at the highest-ranking users that belong to two communities. We can compute this by running the following query:
MATCH (c1:Community)<-[:IN_COMMUNITY]-(u)-[:IN_COMMUNITY]->(c2:Community)
WHERE id(c1) < id(c2)
WITH c1, c2, count(*) AS count, apoc.coll.sortNodes(collect(u), "pagerank")[..5] AS topNodes
RETURN c1.id, c2.id, count,
[node in topNodes | node {.username, score: round(node.pagerank, 3)}] AS topNodes
ORDER BY count DESC
LIMIT 10;| c1.id | c2.id | count | topNodes |
|---|---|---|---|
119 |
34 |
228 |
[{score: 14.666, username: "jessitron"}, {score: 10.754, username: "WardCunningham"}, {score: 8.528, username: "garybernhardt"}, {score: 6.882, username: "InfoQ"}, {score: 4.005, username: "skillsmatter"}] |
119 |
157 |
187 |
[{score: 6.681, username: "arcadeanalytics"}, {score: 4.694, username: "arangodb"}, {score: 4.55, username: "irregularbi"}, {score: 3.915, username: "CamSemantics"}, {score: 3.7, username: "CluedInHQ"}] |
119 |
91 |
46 |
[{score: 0.358, username: "margueritegg"}, {score: 0.3, username: "budejicky"}, {score: 0.26, username: "politicalHEDGE"}, {score: 0.246, username: "420Cyber"}, {score: 0.237, username: "CryptoTrackerBt"}] |
119 |
144 |
36 |
[{score: 3.195, username: "Synaptica"}, {score: 1.208, username: "mrgunn"}, {score: 1.126, username: "agentGav"}, {score: 0.684, username: "richdijkstra"}, {score: 0.544, username: "h2cm"}] |
119 |
22 |
36 |
[{score: 1.437, username: "s7ephen"}, {score: 0.983, username: "d4rkm4tter"}, {score: 0.978, username: "virusbtn"}, {score: 0.919, username: "CVEnew"}, {score: 0.795, username: "InsanityBit"}] |
119 |
1747 |
28 |
[{score: 0.278, username: "tech__lib"}, {score: 0.15, username: "niturkan"}, {score: 0.15, username: "djoman_fidele"}, {score: 0.15, username: "scholarsuniv"}, {score: 0.15, username: "seantabatabai"}] |
119 |
81 |
21 |
[{score: 2.447, username: "vaaaaanquish"}, {score: 0.604, username: "OSS_News"}, {score: 0.591, username: "shiget84"}, {score: 0.584, username: "kabukawa"}, {score: 0.424, username: "insomnyan"}] |
157 |
34 |
20 |
[{score: 2.631, username: "delitescere"}, {score: 2.424, username: "j_palka"}, {score: 2.398, username: "patbaumgartner"}, {score: 0.844, username: "hackcommitpush"}, {score: 0.673, username: "svzdvd"}] |
119 |
3361 |
12 |
[{score: 0.159, username: "hnbot"}, {score: 0.159, username: "Hn150"}, {score: 0.159, username: "SpacedadUNI"}, {score: 0.159, username: "TradeFlo"}, {score: 0.159, username: "nplexROC"}] |
119 |
209 |
10 |
[{score: 0.815, username: "matt_zeus"}, {score: 0.698, username: "stereocat"}, {score: 0.675, username: "hi86074659"}, {score: 0.552, username: "tetoran6"}, {score: 0.419, username: "qb0C80aE"}] |
@jessitron and @wardcunningham belong to communities 119 (Data Science/Popular Tech) and 34 (Spring). @arcadeanalytics, @arangodb, and @CluedInHQ all do work around graph databases, so they end up overlapping communities 119 (Data Science/Popular Tech) and 57 (Neo4j).
It would be interesting to see how strongly they belong in each community. The algorithm does compute an association strength score per node per community, but that score isn’t returned (at least at the moment!).
How do we use overlapping community detection?
So how do we use the results that we get from this algorithm? One way is to use this algorithm to work out which users to follow to learn about other communities. If we pick users who overlap with our community, those users may be better advocates for that community (from our perspective) than the top-ranked users in that community.
For example, if we’re a member of the Neo4j community, we could find fellow Neo4j users that interact with other communities, by running the following query:
MATCH (c1:Community {id: 157})<-[:IN_COMMUNITY]-(u)-[:IN_COMMUNITY]->(c2:Community)
WITH c1, c2, count(*) AS count, apoc.coll.sortNodes(collect(u), "pagerank")[..10] AS topNodes
RETURN c2.id, count,
[node in topNodes | node {.username, score: round(node.pagerank, 3)}] AS topNodes
ORDER BY count DESC
LIMIT 10;| c2.id | count | topNodes |
|---|---|---|
119 |
187 |
[{score: 6.681, username: "arcadeanalytics"}, {score: 4.694, username: "arangodb"}, {score: 4.55, username: "irregularbi"}, {score: 3.915, username: "CamSemantics"}, {score: 3.7, username: "CluedInHQ"}, {score: 2.89, username: "agm1984"}, {score: 2.882, username: "micahstubbs"}, {score: 2.208, username: "newsyc50"}, {score: 2.077, username: "gijn"}, {score: 2.013, username: "jwyg"}] |
34 |
20 |
[{score: 2.631, username: "delitescere"}, {score: 2.424, username: "j_palka"}, {score: 2.398, username: "patbaumgartner"}, {score: 0.844, username: "hackcommitpush"}, {score: 0.673, username: "svzdvd"}, {score: 0.643, username: "tonyennis"}, {score: 0.434, username: "jgerity"}, {score: 0.345, username: "gasi"}, {score: 0.298, username: "softvisresearch"}, {score: 0.279, username: "rafalkoko"}] |
144 |
8 |
[{score: 0.743, username: "PMissier"}, {score: 0.544, username: "intermineorg"}, {score: 0.343, username: "ConTechLive"}, {score: 0.338, username: "justin_littman"}, {score: 0.226, username: "yooj0907"}, {score: 0.213, username: "imo_weg"}, {score: 0.184, username: "webdevOp"}, {score: 0.15, username: "MahekHanfi"}] |
1558 |
3 |
[{score: 0.366, username: "liayeaaah"}, {score: 0.254, username: "King_Sloth95"}, {score: 0.254, username: "yasabdulkadir"}] |
1097 |
2 |
[{score: 0.311, username: "BiintAbib"}, {score: 0.242, username: "Fall__yaaram"}] |
266 |
2 |
[{score: 0.211, username: "i18nsolutions"}, {score: 0.166, username: "HarishMinions20"}] |
22 |
2 |
[{score: 3.431, username: "_wald0"}, {score: 0.15, username: "atatrdp"} |
3846 |
2 |
[{score: 0.15, username: "iamarvil"}, {score: 0.15, username: "JETZT_PRde"} |
3281 |
1 |
[{score: 0.15, username: "AlanPowiatowy"} |
1226 |
1 |
[{score: 0.15, username: "LearnPHPOnline_"}] |
The top users in community 119 are generally popular tech accounts, but the overlap with the Neo4j community returns other folks doing graph database work. If we want to learn about Spring, @delitescere and @patbaumgartner would be good people to follow. And if we’re interested in semantic web, @Pmissier or @intermineorg would be good bets.
In Summary
I first came across this algorithm about 18 months ago and thought it looked awesome, so I’m happy to see it added to the Graph Data Science Library. It seems to find only slight overlap between communities, so I’m not sure how well it’d do if there were communities with very similar members.
We’ve only looked at one use case for it in this blog post, but I’m sure there are others as well. Let me know if you have any questions/ideas in the comments.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.