
Materialize: Creating multiple views on one source
This is another post describing my exploration of Materialize, a SQL streaming database. In this post we’re going to learn how to create multiple views on top of the same underlying source.

We’re still going to be using data extracted from Strava, an app that I use to record my runs, but this time we have more detailed information about each run.
As in the previous blog posts, each run is represented as JSON document and store in the activities-detailed-all.json file in JSON lines format.
Below is an example of one line in this file:
head -n1 data/activities-detailed-all.json |
jq -c '{id, distance, moving_time, elapsed_time,
total_elevation_gain, elv_high, elev_low, average_speed,
max_speed, average_heartrate, max_heartrate, start_date,
best_efforts, splits_metric, splits_standard, segments_efforts}'{"id":259558400,"distance":3116.1,"moving_time":"0:17:48","elapsed_time":"0:17:55","total_elevation_gain":0,"elv_high":null,"elev_low":6,"average_speed":2.918,"max_speed":7.2,"average_heartrate":null,"max_heartrate":null,"start_date":"2015-02-25T06:18:39+00:00","best_efforts":[{"effort_name":"400m","moving_time":131,"elapsed_time":130,"effort_distance":400,"average_heartrate":null,"max_heartrate":null},{"effort_name":"1/2 mile","moving_time":266,"elapsed_time":265,"effort_distance":805,"average_heartrate":null,"max_heartrate":null},{"effort_name":"1k","moving_time":336,"elapsed_time":336,"effort_distance":1000,"average_heartrate":null,"max_heartrate":null},{"effort_name":"1 mile","moving_time":548,"elapsed_time":547,"effort_distance":1609,"average_heartrate":null,"max_heartrate":null}],"splits_metric":[{"distance":1002.9,"elapsed_time":"0:05:48","elevation_difference":3.2,"moving_time":"0:05:41","average_heartrate":null,"split":1,"pace_zone":0,"average_speed":2.94},{"distance":999.4,"elapsed_time":"0:05:48","elevation_difference":-1.9,"moving_time":"0:05:48","average_heartrate":null,"split":2,"pace_zone":0,"average_speed":2.87},{"distance":1001.7,"elapsed_time":"0:05:39","elevation_difference":-2.1,"moving_time":"0:05:39","average_heartrate":null,"split":3,"pace_zone":0,"average_speed":2.95},{"distance":112.1,"elapsed_time":"0:00:40","elevation_difference":0.7,"moving_time":"0:00:40","average_heartrate":null,"split":4,"pace_zone":0,"average_speed":2.8}],"splits_standard":[{"distance":1612.2,"elapsed_time":"0:09:21","elevation_difference":4.7,"moving_time":"0:09:14","average_heartrate":null,"split":1,"pace_zone":0,"average_speed":2.91},{"distance":1503.9,"elapsed_time":"0:08:34","elevation_difference":-4.8,"moving_time":"0:08:34","average_heartrate":null,"split":2,"pace_zone":0,"average_speed":2.93}],"segments_efforts":null}Connecting to Materialize
We’re going to query that data using Materialize, which we’ll set up using the following Docker Compose configuration:
version: '3'
services:
materialize:
image: materialize/materialized:v0.5.3
container_name: "materialize-sandbox-docker-compose"
volumes:
- ./data:/data
ports:
- "6875:6875"The data directory containing the activities-detailed-all.json file is in the mneedham/materialize-sandbox/strava GitHub repository.
The repository also contains setup instructions.
Once we’ve cloned that repository, we can launch Materialize by running the following command:
docker-compose upWe’re now ready to connect to Materialize, which we can do using the psql CLI tool:
psql -h localhost -p 6875 materializepsql (12.5 (Ubuntu 12.5-0ubuntu0.20.04.1), server 9.5.0)
Type "help" for help.
materialize=>Creating a materialized view
We’re going to start by creating a source around the file:
CREATE SOURCE activities_detailed_source
FROM FILE '/data/activities-detailed-all.json'
WITH(tail=true)
FORMAT TEXT;Not it’s time to create some views on top of the source.
We’ll start with the activites_detailed view, which returns the raw values from the JSON file:
CREATE VIEW activities_detailed AS
SELECT (val->>'id')::float::bigint AS id,
(val->>'start_date')::timestamp AS start_date,
(val->'best_efforts') AS best_efforts,
(val->'splits_metric') AS splits_metric,
(val->'splits_standard') AS splits_standard,
(val->'segment_efforts') AS segment_efforts
FROM (SELECT text::json AS val FROM activities_detailed_source);We’re not going to do any direct querying against this view, so we create a VIEW rather than a MATERIALIZED VIEW.
If we want to query that view, we’ll need to make sure we append the AS OF clause to the end of our query, as shown in the following example:
SELECT *
FROM activities_detailed
LIMIT 1
AS OF 1;| id | start_date | best_efforts | splits_metric | splits_standard | segment_efforts |
|---|---|---|---|---|---|
3217642015 |
2020-03-25 18:27:10 |
[] |
|
|
[] |
This view returns JSON arrays for splits_metric, splits_standard, best_efforts, and segment_efforts.
It’d be good if we could explode those array elements into individual rows so that we could query them, which we can do with the jsonb_array_elements function that I wrote about in Materialize: Querying JSON arrays.
We’d generally be querying each of these things separately, so we’ll create one materialized view for each one, as shown in the following diagram:
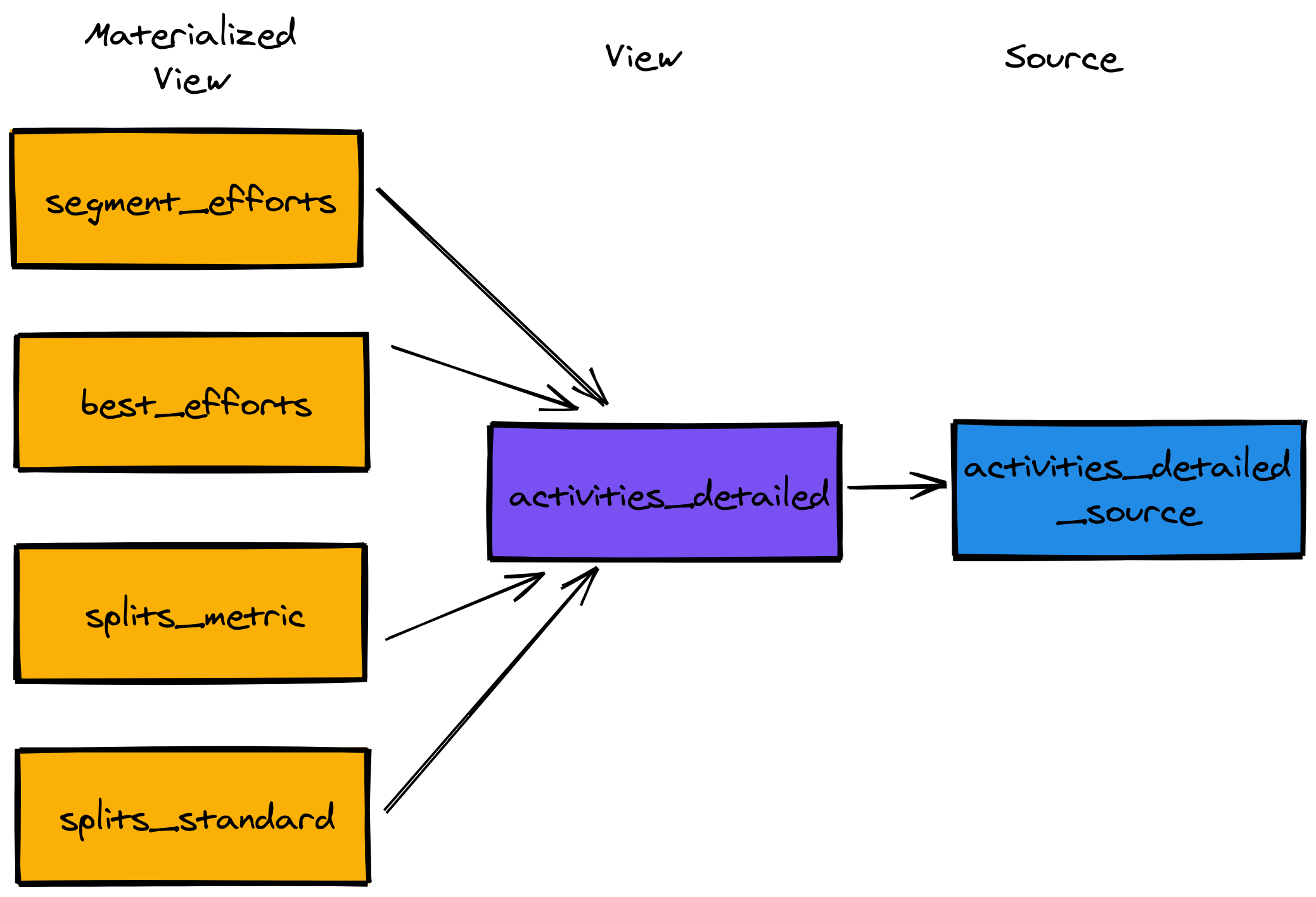
Let’s see how to create a couple of those materialized views. We can do this by running the following queries:
CREATE MATERIALIZED VIEW best_efforts AS
SELECT id, start_date,
(effort->>'effort_name') AS effort_name,
(effort->>'effort_distance')::float AS distance,
(effort->>'elapsed_time')::float AS elapsed_time,
(effort->>'moving_time')::float AS moving_time,
(effort->>'average_heartrate')::float AS average_heartrate,
(effort->>'max_heartrate')::float AS max_heartrate
FROM (
SELECT id, start_date, best_efforts
FROM activities_detailed
), jsonb_array_elements(best_efforts) AS effort;CREATE MATERIALIZED VIEW segment_efforts AS
SELECT id, start_date,
(effort->>'segment_id') AS segment_id,
(effort->>'segment_name') AS segment_name,
(effort->>'distance')::float AS distance,
(effort->>'elapsed_time')::float AS elapsed_time,
(effort->>'moving_time')::float AS moving_time
FROM (
SELECT id, start_date, segment_efforts
FROM activities_detailed
), jsonb_array_elements(segment_efforts) AS effort;Querying the materialized views
Now that we’ve created those views, it’s time to query them.
We’ll start by finding the fastest 10km runs that I’ve done
select start_date, to_char(to_timestamp(moving_time), 'HH24:MI:SS') AS time
from best_efforts
WHERE effort_name = '10k'
ORDER BY moving_time
LIMIT 10;| start_date | time |
|---|---|
2018-08-18 09:50:40 |
00:44:03 |
2018-07-11 04:24:10 |
00:44:17 |
2019-06-14 10:14:39 |
00:44:32 |
2018-10-20 06:14:46 |
00:44:38 |
2018-05-19 08:55:00 |
00:44:43 |
2018-10-27 09:48:01 |
00:44:54 |
2018-07-20 11:05:28 |
00:44:57 |
2018-06-01 04:17:44 |
00:45:00 |
2019-05-25 06:45:53 |
00:45:03 |
2018-08-08 04:28:36 |
00:45:06 |
All my fastest times were in 2018 or 2019! I haven’t been anywhere near that sort of pace for a long while.
If we have the id for a specific run we can write a query to find all the best efforts for that run, as shown below:
select start_date,
effort_name,
to_char(to_timestamp(moving_time), 'MI:SS') AS time
from best_efforts
WHERE id=2448908609
ORDER BY moving_time
LIMIT 10;| start_date | effort_name | time |
|---|---|---|
2019-06-14 10:14:39 |
400m |
01:39 |
2019-06-14 10:14:39 |
1/2 mile |
03:23 |
2019-06-14 10:14:39 |
1k |
04:15 |
2019-06-14 10:14:39 |
1 mile |
06:52 |
2019-06-14 10:14:39 |
2 mile |
13:57 |
2019-06-14 10:14:39 |
5k |
21:53 |
2019-06-14 10:14:39 |
10k |
44:32 |
Now let’s move onto segment efforts. We can find the most popular segments by running the following query:
select segment_id, segment_name, count(*) AS count
from segment_efforts
GROUP BY segment_id, segment_name
ORDER BY count DESC
LIMIT 5;| segment_id | segment_name | count |
|---|---|---|
17236468 |
Lap of the track |
260 |
17875147 |
York to Vet |
226 |
17875143 |
Stanley to Bridge |
186 |
23952234 |
The misdiseaveing incline |
96 |
23952158 |
5 gym dash |
93 |
Lap of the track is a running track that I’ve clearly done a lot of laps on. Let’s explore those laps in more detail:
SELECT start_date,
to_char(to_timestamp(min(moving_time)), 'MI:SS') AS fastestTime,
to_char(to_timestamp(max(moving_time)), 'MI:SS') AS slowestTime,
to_char(to_timestamp(avg(moving_time)), 'MI:SS') AS averageTime,
count(*) AS lapsDone
FROM segment_efforts
WHERE segment_id = '17236468'
GROUP BY start_date
ORDER BY min(moving_time)
LIMIT 5;| start_date | fastesttime | slowesttime | averagetime | lapsdone |
|---|---|---|---|---|
2018-04-02 16:05:31 |
01:42 |
02:08 |
01:55 |
18 |
2018-03-26 02:23:47 |
01:46 |
02:10 |
02:07 |
15 |
2016-07-22 05:18:37 |
01:48 |
02:10 |
02:01 |
9 |
2016-08-03 12:16:23 |
01:49 |
02:06 |
02:01 |
13 |
2020-03-11 02:35:09 |
01:50 |
02:24 |
02:11 |
25 |
Again my fastest laps were in 2018! I clearly need to work on my speed.
In summary
One of the things that I really like about Materialize is that you can defer data transformation. I’m used to having to decide up front how I want to shape the data and then having the queries I can write be limited by that initial transformation. With Materialize you can instead create a single source and then later on create as many views as you want to analyse the data in all different ways.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.