
Neo4j: Enriching an existing graph by querying the Wikidata SPARQL API
This is the third post in a series about querying Wikidata’s SPARQL API. In the first post we wrote some basic queries, in the second we learnt about the SELECT and CONSTRUCT clauses, and in this post we’re going to import query results into an existing Neo4j graph.

Setting up Neo4j
We’re going to use the following Docker Compose configuration in this blog post:
version: '3.7'
services:
neo4j:
image: neo4j:4.0.0-enterprise
container_name: "quickgraph-aus-open"
volumes:
- ./plugins:/plugins
- ./data:/data
- ./import:/var/lib/neo4j/import
ports:
- "7474:7474"
- "7687:7687"
environment:
- "NEO4J_ACCEPT_LICENSE_AGREEMENT=yes"
- "NEO4J_AUTH=neo4j/neo"
- NEO4JLABS_PLUGINS=["apoc"]Once we’ve created that file we need to open a terminal session where that file lives and then run docker-compose up to launch Neo4j.
Let’s connect to our Neo4j instance using the Cypher Shell tool:
$ docker exec -it quickgraph-aus-open cypher-shell -u neo4j -p neo -d system
Connected to Neo4j 4.0.0 at neo4j://localhost:7687 as user neo4j.
Type :help for a list of available commands or :exit to exit the shell.
Note that Cypher queries must end with a semicolon.
neo4j@system>And now let’s create a database to use for this blog post:
CREATE DATABASE enrichwikidata;
:use enrichwikidata;We’re going to create nodes representing some popular tennis players:
UNWIND ["Nick Kyrgios", "Lleyton Hewitt", "Stan Wawrinka", "Roger Federer"] AS name
MERGE (:Player {name: name});0 rows available after 31 ms, consumed after another 0 ms Added 4 nodes, Set 4 properties, Added 4 labels |
Querying Wikidata
Now we’re reading to query Wikidata. We’re going to execute the following query, which returns the data of birth and nationality of Nick Kyrgios, against Wikidata’s SPARQL API:
SELECT *
WHERE { ?person wdt:P106 wd:Q10833314 ;
rdfs:label 'Nick Kyrgios'@en ;
wdt:P569 ?dateOfBirth ;
wdt:P27 [ rdfs:label ?countryName ] .
filter(lang(?countryName) = "en")
}where we’ll substitute the third line of the query with the names of different tennis players. As a refresher, if we run this query, we’ll get the following output:
| person | dateOfBirth | countryName |
|---|---|---|
1995-04-27T00:00:00Z |
Australia |
At the moment these results are in a tabular/CSV structure, but we can have the API return a JSON structure by providing the header Accept: 'application/sparql-results+json'.
The following Cypher query uses the apoc.load.jsonParams procedure to execute a SPARQL query against Wikidata’s SPARQL API:
MATCH (player:Player)
WHERE player.name = "Nick Kyrgios"
WITH "SELECT *
WHERE { ?person wdt:P106 wd:Q10833314 ;
rdfs:label \"" + player.name + "\"@en ;
wdt:P569 ?dateOfBirth ;
wdt:P27 [ rdfs:label ?countryName ] .
filter(lang(?countryName) = \"en\")
}" AS sparql
CALL apoc.load.jsonParams(
"https://query.wikidata.org/sparql?query=" + apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"},
null
)
YIELD value
RETURN valueIf we run that query, we’ll see the following output:
| value |
|---|
|
This looks like it should be reasonably easy to parse, so let’s now do something with this data instead of just returning it!
Importing Wikidata into an existing graph
We’re going to add the date of birth to the dateOfBirth property of each Player node, create a Country node based on the nationality value, and then create a NATIONALITY relationship from the Player to the Country.
We’ll also add the wikidataImportDone property to each Player node so that we know when a node has already been processed.
The following query does what we want:
MATCH (player:Player)
WHERE player.name = "Nick Kyrgios"
WITH "SELECT *
WHERE { ?person wdt:P106 wd:Q10833314 ;
rdfs:label \"" + player.name + "\"@en ;
wdt:P569 ?dateOfBirth ;
wdt:P27 [ rdfs:label ?countryName ] .
filter(lang(?countryName) = \"en\")
}" AS sparql, player
CALL apoc.load.jsonParams(
"https://query.wikidata.org/sparql?query=" + apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"},
null
)
YIELD value
// We use apoc.do.when here because the API might return no results for
// our player and we need to handle that case
CALL apoc.do.when(
size(value.results.bindings) > 0,
'WITH value.results.bindings[0] AS result, player
// Add date of birth and wikiDataImportDone properties
SET player.dateOfBirth = date(datetime(result.dateOfBirth.value)),
player.wikidataImportDone = true
// Create country node
MERGE (c:Country {name: result.countryName.value })
// Create relationship between player and country
MERGE (player)-[:NATIONALITY]->(c)
RETURN player',
'SET player.wikidataImportDone = true RETURN player',
{value: value, player: player})
YIELD value AS result
return player;| player |
|---|
(:Player {name: "Nick Kyrgios", wikidataImportDone: TRUE, dateOfBirth: 1995-04-27, id: "106401"}) |
The Neo4j visualisation below shows what our graph looks like after this query has run:
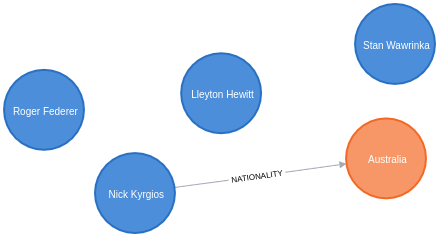
Let’s enrich the rest of our graph from Wikidata, which we can do by running the following query:
// Find all unprocessed players
MATCH (player:Player)
WHERE not(exists(player.wikidataImportDone))
WITH "SELECT *
WHERE { ?person wdt:P106 wd:Q10833314 ;
rdfs:label \"" + player.name + "\"@en ;
wdt:P569 ?dateOfBirth ;
wdt:P27 [ rdfs:label ?countryName ] .
filter(lang(?countryName) = \"en\")
}" AS sparql, player
CALL apoc.load.jsonParams(
"https://query.wikidata.org/sparql?query=" + apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"},
null
)
YIELD value
CALL apoc.do.when(
size(value.results.bindings) > 0,
'WITH value.results.bindings[0] AS result, player
SET player.dateOfBirth = date(datetime(result.dateOfBirth.value)),
player.wikidataImportDone = true
MERGE (c:Country {name: result.countryName.value })
MERGE (player)-[:NATIONALITY]->(c)
RETURN player',
'SET player.wikidataImportDone = true RETURN player',
{value: value, player: player})
YIELD value AS result
return player;| player |
|---|
(:Player {name: "Lleyton Hewitt", wikidataImportDone: TRUE, dateOfBirth: 1981-02-24}) |
(:Player {name: "Stan Wawrinka", wikidataImportDone: TRUE, dateOfBirth: 1985-03-28}) |
(:Player {name: "Roger Federer", wikidataImportDone: TRUE, dateOfBirth: 1981-08-08}) |
And the Neo4j visualisation below shows what our graph looks like after this query has run:
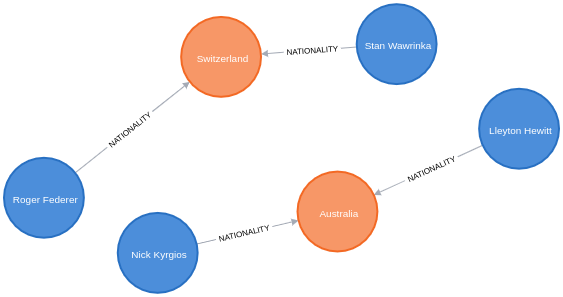
Enriching the Australian Open Graph
Now we’re going to apply this same approach to enrich the Australian Open Graph. Let’s switch to the database for the men’s tournaments:
:use mensAnd now we’ll tweak the query that iterates over all players, calls the Wikipedia API, and uses the results to update the graph.
We’re going to use the apoc.periodic.iterate procedure so that we can process the players in batches of 20 rather than committing all the meta data in one transaction:
CALL apoc.periodic.iterate(
"MATCH (player:Player) WHERE not(exists(player.wikidataImportDone)) RETURN player",
" WITH 'SELECT *
WHERE { ?person wdt:P106 wd:Q10833314 ;
rdfs:label \"' + player.name + '\"@en ;
wdt:P569 ?dateOfBirth ;
wdt:P27 [ rdfs:label ?countryName ] .
filter(lang(?countryName) = \"en\")
}' AS sparql, player
CALL apoc.load.jsonParams(
\"https://query.wikidata.org/sparql?query=\" + apoc.text.urlencode(sparql),
{ Accept: \"application/sparql-results+json\"},
null
)
YIELD value
CALL apoc.do.when(
size(value.results.bindings) > 0,
'WITH value.results.bindings[0] AS result, player
SET player.dateOfBirth = date(datetime(result.dateOfBirth.value)),
player.wikidataImportDone = true
MERGE (c:Country {name: result.countryName.value })
MERGE (player)-[:NATIONALITY]->(c)
RETURN player',
'SET player.wikidataImportDone = true RETURN player',
{value: value, player: player})
YIELD value AS result
RETURN count(*)",
{batchSize: 20});After running a few exploratory queries, I realised that about 1/5 of the players weren’t found in Wikidata. Some of those players aren’t famous enough to have an entry in Wikidata, but some of them have a different spelling of their name in the two datasets.
I updated the names of the finalists by running the following query:
UNWIND [
{wrong: "Arnaud Clement", right: "Arnaud Clément"},
{wrong: "Rainer Schuettler", right: "Rainer Schüttler"},
{wrong: "Fernando Gonzalez", right: "Fernando González"},
{wrong: "Marin Cilic", right: "Marin Čilić"}
] AS name
MATCH (p:Player {name: name.wrong})
SET p.name = name.right
REMOVE p.wikidataImportDoneAnd then I re-ran the previous query to import Wikidata.
Querying the enriched graph
And now that the graph’s been updated, let’s write some queries that uses this new data.
How many participants did each country have in the Australian Open?
Let’s start simple by running the following query which returns the number of players grouped by country:
MATCH (country:Country)<-[:NATIONALITY]-(player)
RETURN country.name, count(*) AS players
ORDER BY players DESC
LIMIT 10;| country.name | players |
|---|---|
"Australia" |
49 |
"United States of America" |
46 |
"France" |
36 |
"Germany" |
31 |
"Italy" |
26 |
"Argentina" |
22 |
"Russia" |
20 |
"Spain" |
17 |
"United States" |
16 |
"United Kingdom" |
12 |
Unsurprisingly Australia have the most participants, although the United States aren’t far behind.
How many finalists did each country have?
Next, we’re going to find out how many times a country had a player in the final:
MATCH (country:Country)<-[:NATIONALITY]-(player)-->(match:Match {round: "F"})
WITH country, count(*) AS finals, collect(distinct player.name) AS players
WHERE finals > 1
RETURN country.name, finals, players
ORDER BY finals DESC;| country.name | finals | players |
|---|---|---|
"Switzerland" |
8 |
["Stan Wawrinka", "Roger Federer"] |
"Serbia" |
8 |
["Novak Djokovic"] |
"Spain" |
5 |
["Rafael Nadal"] |
"United Kingdom" |
5 |
["Andy Murray"] |
"Russia" |
4 |
["Marat Safin", "Yevgeny Kafelnikov"] |
"United States of America" |
3 |
["Andre Agassi"] |
"France" |
2 |
["Arnaud Clément", "Jo-Wilfried Tsonga"] |
Australia now don’t even appear on the list. Their only finalist since 2000 was Lleyton Hewitt in the 2005 final, which he lost to Marat Safin.
And it’s painful to see Andy Murray in there with 5 finals for the United Kingdom, but unfortunately losing all of them.
What was the lowest average age of the finalists?
Let’s finish with a query that uses the date of birth property. The following query returns the top 10 finalists ordered by lowest average age:
MATCH (match:Match {round: "F"})-[:IN_TOURNAMENT]-(tournament:Tournament),
(winner)-[:WINNER]->(match),
(loser)-[:LOSER]->(match),
(winner)-[:NATIONALITY]-(winnerCountry),
(loser)-[:NATIONALITY]-(loserCountry)
WITH tournament, winner, loser, match, winnerCountry, loserCountry,
duration.between(winner.dateOfBirth, date({year: tournament.year})) AS winnerAge,
duration.between(loser.dateOfBirth, date({year: tournament.year})) AS loserAge
RETURN tournament.year, winner.name, loser.name, match.score,
winnerCountry.name, loserCountry.name,
winnerAge.years + "y" + winnerAge.monthsOfYear + "m" AS winnerAgeFormatted,
loserAge.years + "y" + loserAge.monthsOfYear + "m" AS loserAgeFormatted
ORDER BY winnerAge + loserAge / 2
LIMIT 5;| tournament.year | winner.name | loser.name | match.score | winnerCountry.name | loserCountry.name | winnerAgeFormatted | loserAgeFormatted |
|---|---|---|---|---|---|---|---|
2008 |
"Novak Djokovic" |
"Jo-Wilfried Tsonga" |
"4-6 6-4 6-3 7-6(2)" |
"Serbia" |
"France" |
"20y7m" |
"22y8m" |
2004 |
"Roger Federer" |
"Marat Safin" |
"7-6(3) 6-4 6-2" |
"Switzerland" |
"Russia" |
"22y4m" |
"23y11m" |
2006 |
"Roger Federer" |
"Marcos Baghdatis" |
"5-7 7-5 6-0 6-2" |
"Switzerland" |
"Republic of Cyprus" |
"24y4m" |
"20y6m" |
2011 |
"Novak Djokovic" |
"Andy Murray" |
"6-4 6-2 6-3" |
"Serbia" |
"United Kingdom" |
"23y7m" |
"23y7m" |
2009 |
"Rafael Nadal" |
"Roger Federer" |
"7-5 3-6 7-6(3) 3-6 6-2" |
"Spain" |
"Switzerland" |
"22y6m" |
"27y4m" |
4 of the top 5 youngest finals of the 21st century happened in the first decade. Since then the ages have been increasing as the tournament has been dominated by Djokovic and to a lesser extent Federer, both of whom are more than 30 years old now.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.