
Twint: Loading tweets into Kafka and Neo4j
In this post we’re going to load tweets via the twint library into Kafka, and once we’ve got them in there we’ll use the Kafka Connect Neo4j Sink Plugin to get them into Neo4j.
What is twint?
Twitter data has always been some of the most fun to play with, but over the years the official API has become more and more restritive, and it now takes a really long time to download enough data to do anything interesting. I was therefore intrigued when Michael showed me the twint library, which describes itself as:
An advanced Twitter scraping & OSINT tool written in Python that doesn’t use Twitter’s API, allowing you to scrape a user’s followers, following, Tweets and more while evading most API limitations
We can install the library via pip using the following command:
pip install --upgrade -e git+https://github.com/twintproject/twint.git@origin/master#egg=twintRetrieving tweets
Let’s learn how to use the library.
The following code will retrieve tweets since 20th May 2019 for the search term neo4j OR "graph database" OR "graph databases" OR graphdb OR graphconnect OR @neoquestions OR @Neo4jDE OR @Neo4jFr OR neotechnology and save them into the file tweets.json:
import twint
import json
c = twint.Config()
c.Search = "neo4j OR \"graph database\" OR \"graph databases\" OR graphdb OR graphconnect OR @neoquestions OR @Neo4jDE OR @Neo4jFr OR neotechnology"
c.Store_json = True
c.Custom["user"] = ["id", "tweet", "user_id", "username", "hashtags", "mentions"]
c.User_full = True
c.Output = "tweets.json"
c.Since = "2019-05-20"
c.Hide_output = True
twint.run.Search(c)We can have a look at the contents of that file by running the following command:
$ head -n5 tweets.json
{"id": 1133394643830345728, "conversation_id": "1133334287841992704", "created_at": 1559057315000, "date": "2019-05-28", "time": "16:28:35", "timezone": "BST", "user_id": 900548798, "username": "geolytix", "name": "GEOLYTIX", "place": null, "tweet": "have you benchmarked against OSRM? that is best of the 'standard' approaches. I know others ...incluidng us ;-)... doing interesting r&d with massively parallel approach with 1000's of graph database for crazy speeds.", "mentions": ["murraydata", "rapidsai", "ordnancesurvey", "transportgovuk", "puntofisso"], "urls": [], "photos": [], "replies_count": 1, "retweets_count": 0, "likes_count": 1, "location": "", "hashtags": [], "link": "https://twitter.com/Geolytix/status/1133394643830345728", "retweet": null, "quote_url": "", "video": 0}
{"id": 1133393703148687361, "conversation_id": "1133393703148687361", "created_at": 1559057090000, "date": "2019-05-28", "time": "16:24:50", "timezone": "BST", "user_id": 892256485, "username": "neoquestions", "name": "Neo Questions", "place": null, "tweet": "\"neo4j - Return single instance of node - querying by property?\" #neo4jquestions https://stackoverflow.com/questions/56307118/neo4j-return-single-instance-of-node-querying-by-property …", "mentions": "", "urls": ["https://stackoverflow.com/questions/56307118/neo4j-return-single-instance-of-node-querying-by-property"], "photos": [], "replies_count": 0, "retweets_count": 0, "likes_count": 0, "location": "", "hashtags": ["#neo4jquestions"], "link": "https://twitter.com/NeoQuestions/status/1133393703148687361", "retweet": null, "quote_url": "", "video": 0}
{"id": 1133393003656167424, "conversation_id": "1133393003656167424", "created_at": 1559056924000, "date": "2019-05-28", "time": "16:22:04", "timezone": "BST", "user_id": 135805905, "username": "phermar", "name": "Pablo Hernández", "place": null, "tweet": "An illuminating story of @emileifrem, the #Entrepreneur who founded @neo4j, the #Startup offering a graph platform for Data Analysis. https://www.forbes.com/sites/alejandrocremades/2019/05/28/this-entrepreneur-went-from-having-2000-left-in-the-bank-to-building-a-billion-dollar-business/#3d0f1b7b3192 …", "mentions": ["emileifrem", "neo4j"], "urls": ["https://www.forbes.com/sites/alejandrocremades/2019/05/28/this-entrepreneur-went-from-having-2000-left-in-the-bank-to-building-a-billion-dollar-business/#3d0f1b7b3192"], "photos": [], "replies_count": 0, "retweets_count": 0, "likes_count": 0, "location": "", "hashtags": ["#entrepreneur", "#startup"], "link": "https://twitter.com/phermar/status/1133393003656167424", "retweet": null, "quote_url": "", "video": 0}
{"id": 1133392446279344128, "conversation_id": "1133392446279344128", "created_at": 1559056791000, "date": "2019-05-28", "time": "16:19:51", "timezone": "BST", "user_id": 892256485, "username": "neoquestions", "name": "Neo Questions", "place": null, "tweet": "\"How to efficiently store time-series values for each node in NEO4J?\" #neo4jquestions https://stackoverflow.com/questions/56345345/how-to-efficiently-store-time-series-values-for-each-node-in-neo4j …", "mentions": "", "urls": ["https://stackoverflow.com/questions/56345345/how-to-efficiently-store-time-series-values-for-each-node-in-neo4j"], "photos": [], "replies_count": 0, "retweets_count": 0, "likes_count": 0, "location": "", "hashtags": ["#neo4jquestions"], "link": "https://twitter.com/NeoQuestions/status/1133392446279344128", "retweet": null, "quote_url": "", "video": 0}
{"id": 1133392332416606214, "conversation_id": "1132026469675225088", "created_at": 1559056764000, "date": "2019-05-28", "time": "16:19:24", "timezone": "BST", "user_id": 954001, "username": "ryguyrg", "name": "ryan boyd", "place": null, "tweet": "agreed on the spider :-( sounds like a valid comment on the amazon review! https://www.amazon.com/Graph-Algorithms-Practical-Examples-Apache/dp/1492047686/ …", "mentions": ["odbmsorg", "neo4j", "amyhodler", "markhneedham"], "urls": ["https://www.amazon.com/Graph-Algorithms-Practical-Examples-Apache/dp/1492047686/"], "photos": [], "replies_count": 0, "retweets_count": 0, "likes_count": 0, "location": "", "hashtags": [], "link": "https://twitter.com/ryguyrg/status/1133392332416606214", "retweet": null, "quote_url": "", "video": 0}What about if we don’t want to write to a JSON file, but want to write those JSON objects to somewhere not supported by the library?
The writing of data to the JSON file is done by the twint.storage.write.Json function, which we can replace with our own function using the following code:
import twint
import sys
module = sys.modules["twint.storage.write"]
def Json(obj, config):
tweet = obj.__dict__
print(tweet)
module.Json = Json
c = twint.Config()
c.Search = "neo4j OR \"graph database\" OR \"graph databases\" OR graphdb OR graphconnect OR @neoquestions OR @Neo4jDE OR @Neo4jFr OR neotechnology"
c.Store_json = True
c.Custom["user"] = ["id", "tweet", "user_id", "username", "hashtags", "mentions"]
c.User_full = True
c.Output = "tweets.json"
c.Since = "2019-05-20"
c.Hide_output = True
twint.run.Search(c)If we run that tweets will now be printed to stdout instead of being written to tweets.json:
$ python print_tweets.py | head -n5
{'id': 1133418564013174784, 'id_str': '1133418564013174784', 'conversation_id': '1133412611347886080', 'datetime': 1559063018000, 'datestamp': '2019-05-28', 'timestamp': '18:03:38', 'user_id': 2481818113, 'user_id_str': '2481818113', 'username': 'onejsninja', 'name': 'ECONNREFUSED', 'profile_image_url': 'https://pbs.twimg.com/profile_images/1122732844231610368/ccIfr_eK.jpg', 'place': None, 'timezone': 'BST', 'mentions': ['pensnaku', 'neo4j'], 'urls': [], 'photos': [], 'video': 0, 'tweet': '🙌', 'location': '', 'hashtags': [], 'replies_count': '0', 'retweets_count': '0', 'likes_count': '0', 'link': 'https://twitter.com/onejsninja/status/1133418564013174784', 'retweet': None, 'quote_url': ''}
{'id': 1133417664347594752, 'id_str': '1133417664347594752', 'conversation_id': '1133417664347594752', 'datetime': 1559062803000, 'datestamp': '2019-05-28', 'timestamp': '18:00:03', 'user_id': 2355868690, 'user_id_str': '2355868690', 'username': 'theokraay', 'name': 'Theo van Kraay', 'profile_image_url': 'https://pbs.twimg.com/profile_images/953427963227394050/zMqFsTlX.jpg', 'place': None, 'timezone': 'BST', 'mentions': '', 'urls': ['https://lnkd.in/dC9jYFC'], 'photos': [], 'video': 0, 'tweet': 'Discover how to use the execution profile step for #AzureCosmosDB Gremlin API graph databases. Samples...... https://lnkd.in/dC9jYFC\xa0', 'location': '', 'hashtags': ['#azurecosmosdb'], 'replies_count': '0', 'retweets_count': '0', 'likes_count': '0', 'link': 'https://twitter.com/TheoKraay/status/1133417664347594752', 'retweet': None, 'quote_url': ''}
{'id': 1133412611347886080, 'id_str': '1133412611347886080', 'conversation_id': '1133412611347886080', 'datetime': 1559061598000, 'datestamp': '2019-05-28', 'timestamp': '17:39:58', 'user_id': 378668650, 'user_id_str': '378668650', 'username': 'pensnaku', 'name': 'Eedee Naku', 'profile_image_url': 'https://pbs.twimg.com/profile_images/1123867014903287808/1QKtbWAt.jpg', 'place': None, 'timezone': 'BST', 'mentions': ['neo4j'], 'urls': [], 'photos': [], 'video': 0, 'tweet': 'Enjoying my first few days with @neo4j and Cypher. ASCII art. ( ) - [ ] -> ( );', 'location': '', 'hashtags': [], 'replies_count': '1', 'retweets_count': '2', 'likes_count': '7', 'link': 'https://twitter.com/pensnaku/status/1133412611347886080', 'retweet': None, 'quote_url': ''}
{'id': 1133410865607319559, 'id_str': '1133410865607319559', 'conversation_id': '1133410865607319559', 'datetime': 1559061182000, 'datestamp': '2019-05-28', 'timestamp': '17:33:02', 'user_id': 2545730773, 'user_id_str': '2545730773', 'username': 'wbsbike', 'name': 'Will Snipes', 'profile_image_url': 'https://pbs.twimg.com/profile_images/474224499441688576/_qqblwJY.jpeg', 'place': None, 'timezone': 'BST', 'mentions': ['youtube'], 'urls': ['https://youtu.be/v6QI3YlYPrE'], 'photos': [], 'video': 0, 'tweet': 'How Graph Technology is Changing AIJake Graham Neo4j,Alicia Frame Neo4j https://youtu.be/v6QI3YlYPrE\xa0 via @YouTube', 'location': '', 'hashtags': [], 'replies_count': '0', 'retweets_count': '0', 'likes_count': '0', 'link': 'https://twitter.com/wbsbike/status/1133410865607319559', 'retweet': None, 'quote_url': ''}
{'id': 1133410195537833985, 'id_str': '1133410195537833985', 'conversation_id': '1133410195537833985', 'datetime': 1559061023000, 'datestamp': '2019-05-28', 'timestamp': '17:30:23', 'user_id': 872808354720223236, 'user_id_str': '872808354720223236', 'username': 'oraclecourse', 'name': 'Oracle DBA Courses', 'profile_image_url': 'https://pbs.twimg.com/profile_images/956551490205835264/ODMsVpoX.jpg', 'place': None, 'timezone': 'BST', 'mentions': '', 'urls': ['https://twitter.com/OracleCourse/status/1133409940289277953'], 'photos': [], 'video': 0, 'tweet': '#ECO18 #ERP #ExploreOracle #ethereum #TDD #Essbase25 #EmergingTech #futurecities #frontend #Followback #FakeData #Fintech #fintechgeek #freeads #fourweeks #financecourses #fastest #financialservices #groundbreakerstour #ggupgrade #GraphDB #goals #GDPR #GoOracle #GoldenGate https://twitter.com/OracleCourse/status/1133409940289277953\xa0…', 'location': '', 'hashtags': ['#eco18', '#erp', '#exploreoracle', '#ethereum', '#tdd', '#essbase25', '#emergingtech', '#futurecities', '#frontend', '#followback', '#fakedata', '#fintech', '#fintechgeek', '#freeads', '#fourweeks', '#financecourses', '#fastest', '#financialservices', '#groundbreakerstour', '#ggupgrade', '#graphdb', '#goals', '#gdpr', '#gooracle', '#goldengate'], 'replies_count': '0', 'retweets_count': '0', 'likes_count': '0', 'link': 'https://twitter.com/OracleCourse/status/1133410195537833985', 'retweet': None, 'quote_url': 'https://twitter.com/OracleCourse/status/1133409940289277953'}So far so good. Now that we can get access to the tweet objects we can store them in Kafka instead of printing them to the console.
Storing tweets in Kafka
I’ve created a Docker Compose template that launches the containers we’ll use for the rest of the post. It’s available in the kafka-connect-neo4j GitHub repository.
git clone git@github.com:mneedham/kafka-connect-neo4j.git && cd kafka-connect-neo4j
docker-compose upWe should see the following output from running that command:
Starting zookeeper-kc ... done
Starting broker-kc ... done
Starting neo4j-kc ... done
Starting schema_registry-kc ... done
Starting ksql-server-kc ... done
Starting connect-kc ... done
Starting control-center-kc ... done
Attaching to zookeeper-kc, broker-kc, ksql-server-kc, neo4j-kc, schema_registry-kc, connect-kc, control-center-kcWhile that’s running, we’ll install the confluent-kafka-python driver using the following command:
pip install confluent-kafka[avro]We can now update the Json function that we wrote earlier to store our tweets into the tweets topic:
import twint
import sys
import json
from confluent_kafka import avro
from confluent_kafka.avro import AvroProducer
# Define Avro schema
value_schema_str = """
{
"namespace": "my.test",
"name": "value",
"type": "record",
"fields" : [
{ "name": "id", "type": "long" },
{ "name": "tweet", "type": "string" },
{ "name": "datetime", "type": "long" },
{ "name": "username", "type": "string" },
{ "name": "user_id", "type": "long" },
{ "name": "hashtags", "type": {"type": "array", "items": "string"} }
]
}
"""
key_schema_str = """
{
"namespace": "my.test",
"name": "key",
"type": "record",
"fields" : [
{
"name" : "name",
"type" : "string"
}
]
}
"""
kafka_broker = 'localhost:9092'
schema_registry = 'http://localhost:8081'
value_schema = avro.loads(value_schema_str)
key_schema = avro.loads(key_schema_str)
producer = AvroProducer({
'bootstrap.servers': kafka_broker,
'schema.registry.url': schema_registry
}, default_key_schema=key_schema, default_value_schema=value_schema)
module = sys.modules["twint.storage.write"]
def Json(obj, config):
tweet = obj.__dict__
print(tweet)
producer.produce(topic='tweets', value=tweet, key={"name": "Key"})
producer.flush()
module.Json = Json
c = twint.Config()
c.Search = "neo4j OR \"graph database\" OR \"graph databases\" OR graphdb OR graphconnect OR @neoquestions OR @Neo4jDE OR @Neo4jFr OR neotechnology"
c.Store_json = True
c.Custom["user"] = ["id", "tweet", "user_id", "username", "hashtags", "mentions"]
c.User_full = True
c.Output = "tweets.json"
c.Since = "2019-05-20"
c.Hide_output = True
twint.run.Search(c)Since the events we stored used an Avro schema, we’ll use the kafka-avro-console-consumer command to query the topic:
$ docker exec schema_registry-kc kafka-avro-console-consumer --topic tweets --bootstrap-server broker:9093 --from-beginning
[2019-05-28 17:10:59,610] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
....
[2019-05-28 17:10:59,918] INFO Kafka version : 2.1.1-cp1 (org.apache.kafka.common.utils.AppInfoParser)
[2019-05-28 17:10:59,918] INFO Kafka commitId : 9aa84c2aaa91e392 (org.apache.kafka.common.utils.AppInfoParser)
[2019-05-28 17:11:00,035] INFO Cluster ID: Ai8uZd6RS7iUToW3jRwBTQ (org.apache.kafka.clients.Metadata)
[2019-05-28 17:11:00,036] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] Discovered group coordinator broker:9093 (id: 2147483646 rack: null) (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2019-05-28 17:11:00,038] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] Revoking previously assigned partitions [] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
[2019-05-28 17:11:00,038] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] (Re-)joining group (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2019-05-28 17:11:00,047] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] Successfully joined group with generation 1 (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2019-05-28 17:11:00,048] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] Setting newly assigned partitions [tweets-0] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
[2019-05-28 17:11:00,065] INFO [Consumer clientId=consumer-1, groupId=console-consumer-8062] Resetting offset for partition tweets-0 to offset 0. (org.apache.kafka.clients.consumer.internals.Fetcher)
{"id":1133394643830345728,"tweet":"have you benchmarked against OSRM? that is best of the 'standard' approaches. I know others ...incluidng us ;-)... doing interesting r&d with massively parallel approach with 1000's of graph database for crazy speeds.","datetime":1559057315000,"username":"geolytix","user_id":900548798,"hashtags":[]}
{"id":1133393703148687361,"tweet":"\"neo4j - Return single instance of node - querying by property?\" #neo4jquestions https://stackoverflow.com/questions/56307118/neo4j-return-single-instance-of-node-querying-by-property …","datetime":1559057090000,"username":"neoquestions","user_id":892256485,"hashtags":["#neo4jquestions"]}
{"id":1133393003656167424,"tweet":"An illuminating story of @emileifrem, the #Entrepreneur who founded @neo4j, the #Startup offering a graph platform for Data Analysis. https://www.forbes.com/sites/alejandrocremades/2019/05/28/this-entrepreneur-went-from-having-2000-left-in-the-bank-to-building-a-billion-dollar-business/#3d0f1b7b3192 …","datetime":1559056924000,"username":"phermar","user_id":135805905,"hashtags":["#entrepreneur","#startup"]}
{"id":1133392446279344128,"tweet":"\"How to efficiently store time-series values for each node in NEO4J?\" #neo4jquestions https://stackoverflow.com/questions/56345345/how-to-efficiently-store-time-series-values-for-each-node-in-neo4j …","datetime":1559056791000,"username":"neoquestions","user_id":892256485,"hashtags":["#neo4jquestions"]}
{"id":1133392332416606214,"tweet":"agreed on the spider :-( sounds like a valid comment on the amazon review! https://www.amazon.com/Graph-Algorithms-Practical-Examples-Apache/dp/1492047686/ …","datetime":1559056764000,"username":"ryguyrg","user_id":954001,"hashtags":[]}Great, all good so far! Now we’re ready to get the tweets from Kafka into Neo4j.
Storing tweets in Neo4j
As mentioned at the beginning of this post, we’re going to use the Kafka Connect Neo4j Sink Plugin to get the data from Kafka into Neo4j. The Kafka Connect Neo4j Sink Plugin was launched in February, and is a tool that makes it easy to load streaming data from Kafka into Neo4j. You control ingestion by defining Cypher statements per topic that you want to ingest. Those are then executed for batches of events coming in.
We can create a new connector by running the following command:
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/ \
-d '{
"name": "connect.sink.neo4j.tweets",
"config": {
"topics": "tweets",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"neo4j.server.uri": "bolt://neo4j:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "neo",
"neo4j.topic.cypher.tweets": "WITH event AS data MERGE (t:Tweet {id: data.id}) SET t.text = data.tweet, t.createdAt = datetime({epochmillis:data.datetime}) MERGE (u:User {username: data.username}) SET u.id = data.user_id MERGE (u)-[:POSTED]->(t) FOREACH (ht IN data.hashtags | MERGE (hashtag:HashTag {value: ht}) MERGE (t)-[:HAS_HASHTAG]->(hashtag))"
}
}'This creates a consumer that takes messages from the tweets topic and runs the Cypher query defined by neo4j.topic.cypher.tweets.
We can then run the following Cypher query to explore the data that’s been loaded into Neo4j:
MATCH path = (u:User)-[:POSTED]->(t:Tweet)-[:HAS_HASHTAG]->(ht)
RETURN path
LIMIT 100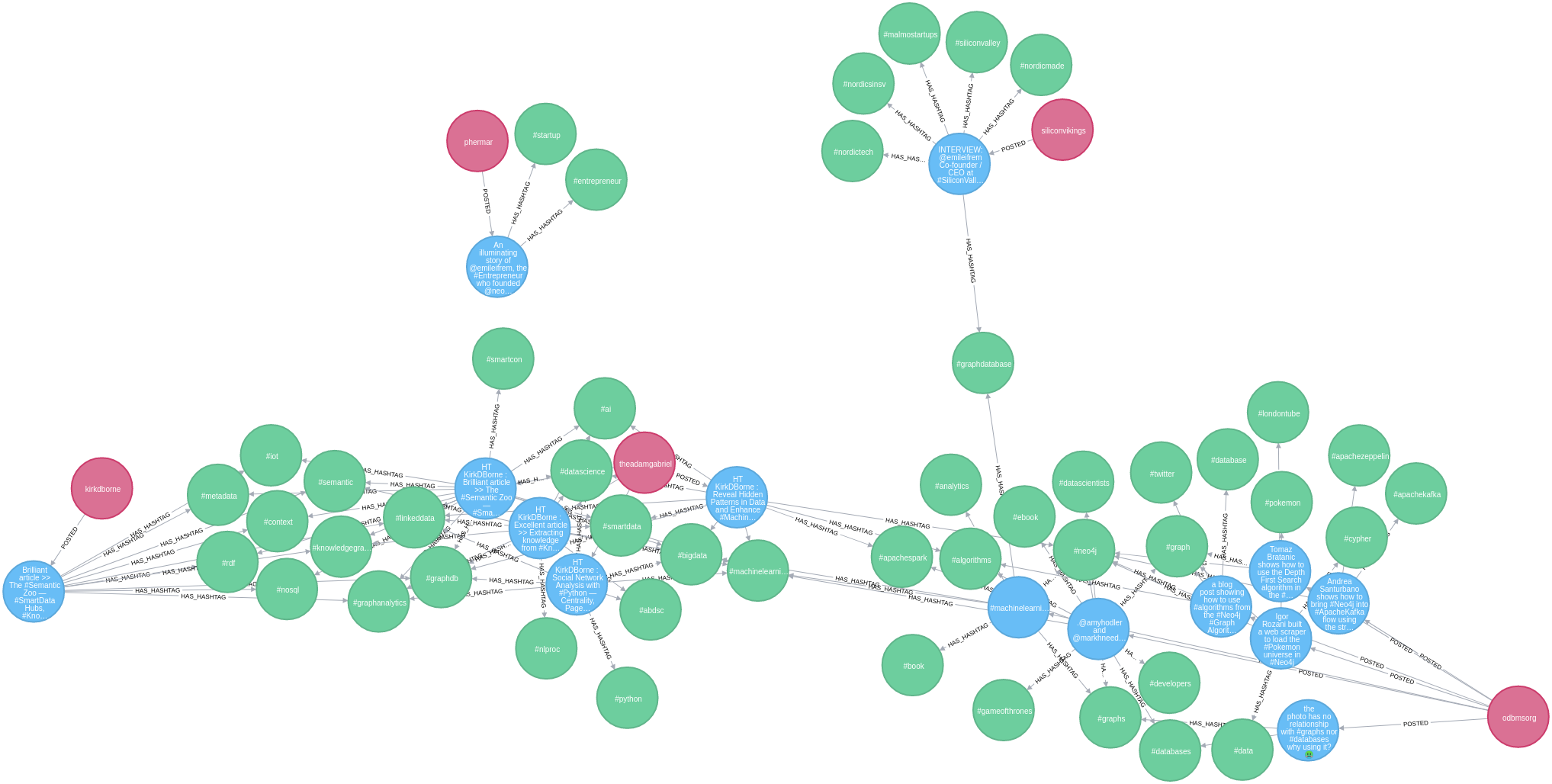
Summary
And that’s it! Hopefully this post has shown how easy it is to load data from Kafka into Neo4j using the Kafka Connect Sink. Below are useful resources in case you want to reproduce any part of this post:
-
Blog post announcing the launch of the Kafka Connect Neo4j Sink Plugin
-
GitHub gist showing the evolution of our tweet processing code
-
kafka-connect-neo4j repository for launching all the infrastructure used
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.