
Processing Neo4j Transaction Events with KSQL and Kafka Streams
The Neo4j Streams Library lets users send transaction events to a Kafka topic, and in this post we’re going to learn how to explore these events using the KSQL streaming SQL Engine.
All the infrastructure used in this post can be launched locally from Docker compose, using the following command:
git clone git@github.com:mneedham/ksql-kafka-neo4j-streams.git && cd ksql-kafka-neo4j-streams
docker-compose-upRunning this command will create four containers:
Starting zookeeper-blog ...
Starting broker-blog ...
Starting ksql-server-blog ...
Starting neo4j-blog ...While that’s running, let’s learn how to use the Neo4j Streams Library. The library has four parts:
-
Neo4j Streams Procedure: a procedure to send a payload to a topic
-
Neo4j Streams Producer: a transaction event handler events that sends data to a Kafka topic
-
Neo4j Streams Consumer: a Neo4j application that ingest data from Kafka topics into Neo4j via templated Cypher Statements
-
Kafka-Connect Plugin: a plugin for the Confluent Platform that allows to ingest data into Neo4j, from Kafka topics, via Cypher queries.
We’re going to use the Neo4j Streams Producer to configure a source that will publish all nodes with the User label to the users_blog topic.
If we were deploying Neo4j in a non Docker environment we’d do this by adding the following line to our Neo4j Configuration file:
streams.source.topic.nodes.users_blog= User{*}But in our case we’re using Docker, so instead we’ll define the following environment variable:
NEO4J_streams_source_topic_nodes_users__blog: User{*}We can also see this configuration in the Docker Compose file:
Now we’re going to run a Cypher fragment that creates some User nodes in the Neo4j Browser, which is accessible from http://localhost:7474:
UNWIND range(0, 100) AS id
CREATE (u:User {id: id})
> Added 101 labels, created 101 nodes, set 101 properties, completed after 173 ms.The diagram below shows the workflow of our query going into Neo4j, and then events being published to Kafka:
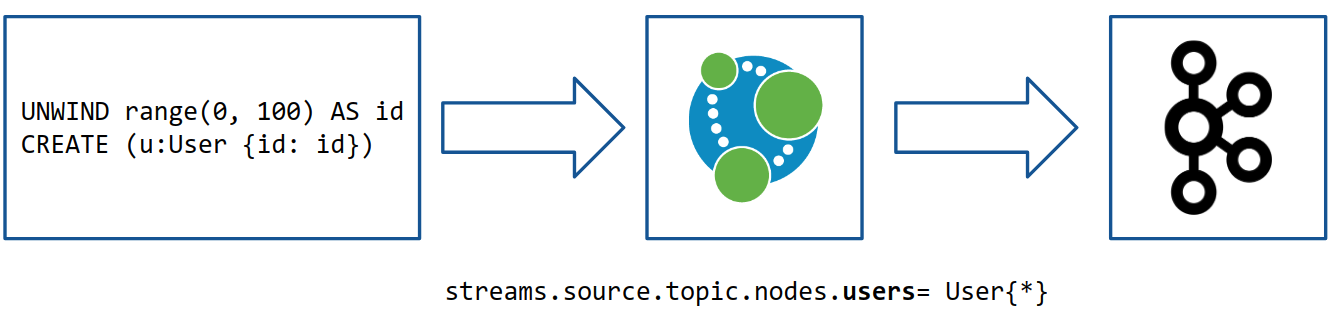
Once this query has completed, events capturing the creation of those nodes will be published to the users_blog topic.
We can then use KSQL to explore that data.
But first things first, what is KSQL?
KSQL is the streaming SQL engine for Apache Kafka®. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. KSQL is scalable, elastic, fault-tolerant, and real-time. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
We’ll execute KSQL queries using the KSQL CLI Docker container. Before we launch that container we need to know the name of the network on which our other containers are running. We can run the following code to determine the network:
for container in `docker container ls --format "{{.Names}}"`; do
network=`docker inspect $container --format='{{ .HostConfig.NetworkMode }}'`
printf '%-20s %-15s\n' $container $network
done
ksql-server-blog ksql-kafka-neo4j-streams_default
neo4j-blog ksql-kafka-neo4j-streams_default
broker-blog ksql-kafka-neo4j-streams_default
zookeeper-blog ksql-kafka-neo4j-streams_defaultAll of our containers are using the network called ksql-kafka-neo4j-streams_default, a value that we’ll pass to the --network parameter when we launch the KSQL CLI container:
$ docker run --network ksql-kafka-neo4j-streams_default --rm --interactive --tty confluentinc/cp-ksql-cli:5.2.1 http://ksql-server:8088Note that the http://ksql-server:8088 value at the end of the command refers to the container name and listener port of our KSQL Server, which we can see in the following fragment of our Docker Compose file:
ksql-server:
container_name: ksql-server
image: "confluentinc/cp-ksql-server:5.2.1"
depends_on:
- broker
environment:
KSQL_BOOTSTRAP_SERVERS: broker:9093
KSQL_LISTENERS: http://0.0.0.0:8088When we run that command we should see the following output:
===========================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ \| | =
= | ' /| (___ | | | | | =
= | < \___ \| | | | | =
= | . \ ____) | |__| | |____ =
= |_|\_\_____/ \___\_\______| =
= =
= Streaming SQL Engine for Apache Kafka® =
===========================================
Copyright 2017-2018 Confluent Inc.
CLI v5.2.1, Server v5.2.1 located at http://ksql-server:8088
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>If we see this prompt we’re ready to roll.
We’ll create a stream over the users_blog topic by running the following query:
CREATE STREAM users_blog(
payload STRUCT<
id varchar,
type varchar,
before STRUCT<
labels ARRAY<varchar>,
`properties` MAP<varchar,varchar>
>,
after STRUCT<
labels ARRAY<varchar>,
`properties` MAP<varchar,varchar>
>
>,
meta STRUCT <
timestamp bigint,
operation varchar,
username varchar
>
)
WITH(KAFKA_TOPIC='users_blog', value_format='json');The fields and field types defined in this stream are based on the event definitions from the Transaction Event Handler section of the Neo4j Streams documentation.
Next we’ll run the following statement to tell KSQL to read from the beginning of the topic:
ksql> SET 'auto.offset.reset' = 'earliest';
Successfully changed local property 'auto.offset.reset' to 'earliest'. Use the UNSET command to revert your change.And now let’s query the stream:
ksql> SELECT * FROM users_blog LIMIT 10;
1558621108556 | 4-0 | {ID=0, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=0}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108828 | 5-1 | {ID=1, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=1}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108830 | 6-2 | {ID=2, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=2}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108831 | 7-3 | {ID=3, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=3}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108832 | 8-4 | {ID=4, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=4}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108833 | 9-5 | {ID=5, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=5}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108834 | 10-6 | {ID=6, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=6}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108835 | 11-7 | {ID=7, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=7}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108835 | 12-8 | {ID=8, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=8}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108837 | 13-9 | {ID=9, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=9}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
Limit Reached
Query terminatedWe can see the first ten nodes that were created by the Cypher query that we ran earlier.
Notice that the operation is created.
What if we take each of those nodes and add a name property by running the following Cypher query in the Neo4j Browser?
MATCH (u:User)
SET u.name = "Name-" + u.id
> Set 101 properties, completed after 57 ms.We can now run the following query to see the different types of events on our stream:
ksql> SELECT meta->operation, count(*) FROM users_blog GROUP BY meta->operation;
created | 101
updated | 101We can view those events by running the following command and waiting until it gets to the last few entries:
ksql> SELECT * FROM users_blog;
...
1558622181521 | 101-95 | {ID=90, TYPE=node, BEFORE={LABELS=[User], properties={id=90}}, AFTER={LABELS=[User], properties={name=Name-90, id=90}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181522 | 102-96 | {ID=75, TYPE=node, BEFORE={LABELS=[User], properties={id=75}}, AFTER={LABELS=[User], properties={name=Name-75, id=75}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181522 | 103-97 | {ID=60, TYPE=node, BEFORE={LABELS=[User], properties={id=60}}, AFTER={LABELS=[User], properties={name=Name-60, id=60}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181523 | 104-98 | {ID=45, TYPE=node, BEFORE={LABELS=[User], properties={id=45}}, AFTER={LABELS=[User], properties={name=Name-45, id=45}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181523 | 105-99 | {ID=30, TYPE=node, BEFORE={LABELS=[User], properties={id=30}}, AFTER={LABELS=[User], properties={name=Name-30, id=30}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181523 | 106-100 | {ID=15, TYPE=node, BEFORE={LABELS=[User], properties={id=15}}, AFTER={LABELS=[User], properties={name=Name-15, id=15}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}Note that the properties now include both the id from when we created the nodes, as well as the name that we just added.
We can now create separate streams to process the created and updated records:
users_blog_created
CREATE STREAM users_blog_created AS
SELECT *
FROM users_blog
WHERE meta->operation = 'created';
----------------------------
Stream created and running
----------------------------users_blog_updated
CREATE STREAM users_blog_updated AS
SELECT *
FROM users_blog
WHERE meta->operation = 'updated';
----------------------------
Stream created and running
----------------------------And now we can query these streams individually.
users_blog_created
ksql> SELECT * FROM users_blog_created LIMIT 5;
1558621108556 | 4-0 | {ID=0, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=0}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108841 | 16-12 | {ID=12, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=12}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108835 | 11-7 | {ID=7, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=7}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108844 | 17-13 | {ID=13, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=13}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
1558621108835 | 12-8 | {ID=8, TYPE=node, BEFORE=null, AFTER={LABELS=[User], properties={id=8}}} | {TIMESTAMP=1558621108484, OPERATION=created, USERNAME=neo4j}
Limit Reached
Query terminatedusers_blog_updated
ksql> SELECT * FROM users_blog_updated LIMIT 5;
1558622181456 | 7-1 | {ID=17, TYPE=node, BEFORE={LABELS=[User], properties={id=17}}, AFTER={LABELS=[User], properties={name=Name-17, id=17}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181460 | 12-6 | {ID=8, TYPE=node, BEFORE={LABELS=[User], properties={id=8}}, AFTER={LABELS=[User], properties={name=Name-8, id=8}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181454 | 6-0 | {ID=0, TYPE=node, BEFORE={LABELS=[User], properties={id=0}}, AFTER={LABELS=[User], properties={name=Name-0, id=0}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181457 | 8-2 | {ID=34, TYPE=node, BEFORE={LABELS=[User], properties={id=34}}, AFTER={LABELS=[User], properties={name=Name-34, id=34}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
1558622181459 | 11-5 | {ID=85, TYPE=node, BEFORE={LABELS=[User], properties={id=85}}, AFTER={LABELS=[User], properties={name=Name-85, id=85}}} | {TIMESTAMP=1558622181434, OPERATION=updated, USERNAME=neo4j}
Limit Reached
Query terminatedWe could then create consumers that subscribe to these streams and process the events published, but that’s for another blog post!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.