
Neo4j: From Graph Model to Neo4j Import
In this post we’re going to learn how to import the DBLP citation network into Neo4j using the Neo4j Import Tool.
In case you haven’t come across this dataset before, Tomaz Bratanic has a great blog post explaining it.
The tl;dr is that we have articles, authors, and venues. Authors can write articles, articles can reference other articles, and articles are presented at a venue. Below is the graph model for this dataset:

Tomaz then goes on to show how to load the data into Neo4j using Cypher and the APOC library. Unfortunately this process is quite slow as there’s a lot of data so, since I’m not as patient as Tomaz, I wanted to try and find a faster way to get the data into the graph.
At a high level, the diagram below shows what happens when we import data using Cypher:
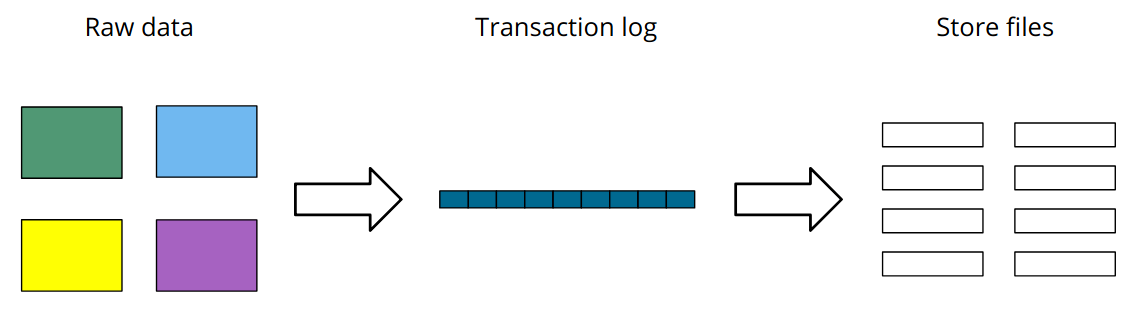
When we use the Neo4j import tool we’re able to skip that middle bit:
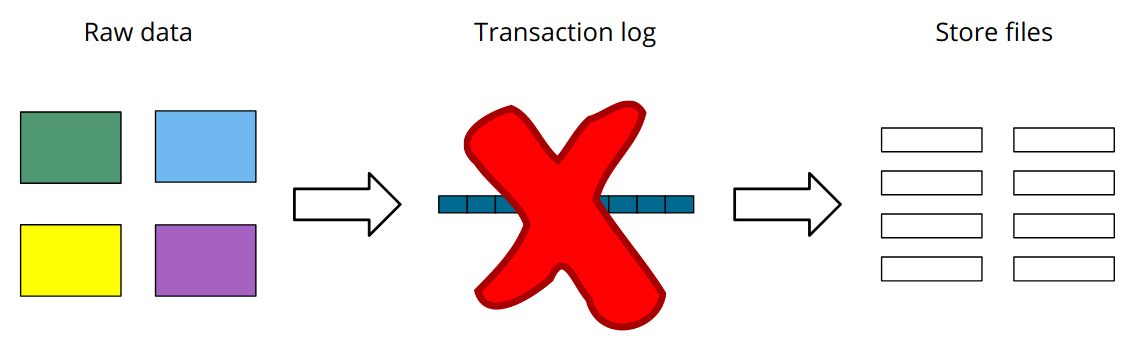
We skip the whole transactional machinery, so it’s much faster. We do pay a price for that extra speed:
-
We can only use this tool to create a brand new database
-
If there’s an error while it runs we need to start again from the beginning
-
We need to get our data into the format that the tool expects
If we’re happy with that trade off then Neo4j Import is the way to go.
The raw data is in JSON files, so our process will be as follows:

We don’t have to use a Python script to transform the raw data, but that’s the scripting language I’m most familiar with so I tend to use that.
Before we look at the script, let’s explore the JSON files that we need to transform. Below is a sample of one of these files:
| { | |
| "abstract":"The purpose of this study is to develop a learning tool for high school students studying the scientific aspects of information and communication net- works. More specifically, we focus on the basic principles of network proto- cols as the aim to develop our learning tool. Our tool gives students hands-on experience to help understand the basic principles of network protocols.", | |
| "authors":[ | |
| "Makoto Satoh", | |
| "Ryo Muramatsu", | |
| "Mizue Kayama", | |
| "Kazunori Itoh", | |
| "Masami Hashimoto", | |
| "Makoto Otani", | |
| "Michio Shimizu", | |
| "Masahiko Sugimoto" | |
| ], | |
| "n_citation":0, | |
| "references":[ | |
| "51c7e02e-f5ed-431a-8cf5-f761f266d4be", | |
| "69b625b9-ebc5-4b60-b385-8a07945f5de9" | |
| ], | |
| "title":"Preliminary Design of a Network Protocol Learning Tool Based on the Comprehension of High School Students: Design by an Empirical Study Using a Simple Mind Map", | |
| "venue":"international conference on human-computer interaction", | |
| "year":2013, | |
| "id":"00127ee2-cb05-48ce-bc49-9de556b93346" | |
| } |
Each row contains one JSON document and, as we can see, these documents contain the following keys:
-
abstract- the abstract of the article -
authors- the authors who wrote the article -
n_citation- we won’t use this key -
references- the other articles that an article cites -
title- the title of the article -
venue- the venue where the article was published -
year- the year the article was published -
id- the id of the article
For each of these JSON documents we’re going to create the following graph structure:
(:Article)-[:VENUE]->(:Venue)
(:Article)-[:AUTHOR]->(:Author)
(:Article)-[:CITED]->(:Article)-
where
()indicates a node i.e.(:Article)means that we have a node with the labelArticle -
and
[]indicates a relationship i.e.[:VENUE]means that we have a relationship with the typeVENUE
The properties from our JSON document will be assigned as follows:
-
id,title,abstract,year-Articlenode -
authors- oneAuthornode per value in the array, with the value assigned to thenameproperty -
references- oneArticlenode per value in the array, with the value assigned to theidproperty -
venue- oneVenuenode per value in the array, with the value assigned to thenameproperty
So we know what data we’re going to extract from our JSON file, but what should the CSV files that we create look like?
The Neo4j Import Tool expects separate CSV files containing the nodes and relationships that we want to create. For each of those files we can either include a header line at the top of the file, or we can store those header lines in a separate line. We’re going to take the latter approach in this blog post.
The fields in those headers have a very specific format, it’s almost a mini DSL.
Let’s take the example of the Author and Venue nodes and the corresponding relationship.
We’ll have three CSV files.
The node headers will look like this:
articles_header.csv
id:ID(Article),title:string,abstract:string,year:intvenues_header.csv
name:ID(Venue),name:stringFor node files one of the fields needs to act as an identifier.
We define this by including :ID in that field.
In our example we’re also specifying an optional node group in parentheses e.g. :ID(Article).
The node group is used to indicate that the identifier only needs to be unique within that group, rather than across all nodes.
And the relationships header will look like this:
article_VENUE_venue_header.csv
:START_ID(Article),:END_ID(Venue)Again our header fields need to contain some custom values:
-
:START_IDindicates that this field contains the identifier for the source node -
:END_IDindicates that this field contains the identifier for the target node
As with the nodes, we can specify a node group in parentheses e.g. :START_ID(Article).
So now we know what files we need to create, let’s have a look at the script that generates these files:
| import glob | |
| import json | |
| import csv | |
| articles = {} | |
| authors = set() | |
| venues = set() | |
| def write_header(file, fields): | |
| csv.writer(file, delimiter=",").writerow(fields) | |
| with open("data/article_REFERENCES_article.csv", "w") as article_references_article_file, \ | |
| open("data/article_REFERENCES_article_header.csv", "w") as article_references_article_header_file, \ | |
| open("data/article_AUTHOR_author.csv", "w") as article_author_author_file, \ | |
| open("data/article_AUTHOR_author_header.csv", "w") as article_author_author_header_file, \ | |
| open("data/article_VENUE_venue.csv", "w") as article_venue_venue_file, \ | |
| open("data/article_VENUE_venue_header.csv","w") as article_venue_venue_header_file: | |
| write_header(article_references_article_header_file, [":START_ID(Article)", ":END_ID(Article)"]) | |
| write_header(article_author_author_header_file, [":START_ID(Article)", ":END_ID(Author)"]) | |
| write_header(article_venue_venue_header_file, [":START_ID(Article)", ":END_ID(Venue)"]) | |
| articles_references_article_writer = csv.writer(article_references_article_file, delimiter=",") | |
| article_author_author_file_writer = csv.writer(article_author_author_file, delimiter=",") | |
| article_venue_venue_file_writer = csv.writer(article_venue_venue_file, delimiter=",") | |
| for file_path in glob.glob("dblp-ref/*.json"): | |
| with open(file_path, "r") as file: | |
| line = file.readline() | |
| while line: | |
| item = json.loads(line) | |
| articles[item["id"]] = {"abstract": item.get("abstract", ""), | |
| "title": item["title"], "year": item["year"]} | |
| venue = item["venue"] | |
| if venue: | |
| venues.add(venue) | |
| article_venue_venue_file_writer.writerow([item["id"], venue]) | |
| for reference in item.get("references", []): | |
| articles_references_article_writer.writerow([item["id"], reference]) | |
| for author in item.get("authors", []): | |
| authors.add(author) | |
| article_author_author_file_writer.writerow([item["id"], author]) | |
| line = file.readline() | |
| with open("data/articles.csv", "w") as articles_file, \ | |
| open("data/articles_header.csv", "w") as articles_header_file, \ | |
| open("data/authors.csv", "w") as authors_file, \ | |
| open("data/authors_header.csv", "w") as authors_header_file, \ | |
| open("data/venues.csv", "w") as venues_file, \ | |
| open("data/venues_header.csv","w") as venues_header_file: | |
| write_header(articles_header_file, ["index:ID(Article)", "title:string", "abstract:string", "year:int"]) | |
| write_header(authors_header_file, ["name:ID(Author)",]) | |
| write_header(venues_header_file, ["name:ID(Venue)"]) | |
| articles_writer = csv.writer(articles_file, delimiter=",") | |
| for article_id in articles: | |
| article = articles[article_id] | |
| articles_writer.writerow([article_id, article["title"], article["abstract"], article.get("year")]) | |
| authors_writer = csv.writer(authors_file, delimiter=",") | |
| for author in authors: | |
| authors_writer.writerow([author]) | |
| venues_writer = csv.writer(venues_file, delimiter=",") | |
| for venue in venues: | |
| venues_writer.writerow([venue]) |
There’s nothing too clever going here - we’re iterating over the JSON files and writing into CSV files. For the relationships we write those directly to the CSV files as soon as we see them. For the nodes we’re collecting those in in-memory data structures to remove duplicates, and then we write those to the CSV files at the end.
Let’s have a look at a subset of the data in those CSV files:
| index:ID(Article) | title:string | abstract:string | year:int |
|---|
| 00127ee2-cb05-48ce-bc49-9de556b93346 | Preliminary Design of a Network Protocol Learning Tool Based on the Comprehension of High School Students: Design by an Empirical Study Using a Simple Mind Map | The purpose of this study is to develop a learning tool for high school students studying the scientific aspects of information and communication net- works. More specifically, we focus on the basic principles of network proto- cols as the aim to develop our learning tool. Our tool gives students hands-on experience to help understand the basic principles of network protocols. | 2013 | |
|---|---|---|---|---|
| 001c58d3-26ad-46b3-ab3a-c1e557d16821 | A methodology for the physically accurate visualisation of roman polychrome statuary | This paper describes the design and implementation of a methodology for the visualisation and hypothetical virtual reconstruction of Roman polychrome statuary for research purposes. The methodology is intended as an attempt to move beyond visualisations which are simply believable towards a more physically accurate approach. Accurate representations of polychrome statuary have great potential utility both as a means of illustrating existing interpretations and as a means of testing and revising developing hypotheses. The goal of this methodology is to propose a pipeline which incorporates a high degree of physical accuracy whilst also being practically applicable in a conventional archaeological research setting. The methodology is designed to allow the accurate visualisation of surviving objects and colourants as well as providing reliable methods for the hypothetical reconstruction of elements which no longer survive. The process proposed here is intended to limit the need for specialist recording equipment, utilising existing data and those data which can be collected using widely available technology. It is at present being implemented as part of the 'Statues in Context' project at Herculaneum and will be demonstrated here using the case study of a small area of the head of a painted female statue discovered at Herculaneum in 2006. | 2011 | |
| 001c8744-73c4-4b04-9364-22d31a10dbf1 | Comparison of GARCH, Neural Network and Support Vector Machine in Financial Time Series Prediction | This article applied GARCH model instead AR or ARMA model to compare with the standard BP and SVM in forecasting of the four international including two Asian stock markets indices.These models were evaluated on five performance metrics or criteria. Our experimental results showed the superiority of SVM and GARCH models, compared to the standard BP in forecasting of the four international stock markets indices. | 2009 | |
| 00338203-9eb3-40c5-9f31-cbac73a519ec | Development of Remote Monitoring and Control Device for 50KW PV System Based on the Wireless Network | 2011 | ||
| 0040b022-1472-4f70-a753-74832df65266 | Reasonig about Set-Oriented Methods in Object Databases. | 1998 | ||
| 005ce28f-ed77-4e97-afdc-a296137186a1 | COMPARING GNG3D AND QUADRIC ERROR METRICS METHODS TO SIMPLIFY 3D MESHES | 2009 | ||
| 00638a94-23bf-4fa6-b5ce-40d799c65da7 | Vectorial fast correlation attacks. | 2004 | ||
| 00701b05-684f-45f9-b281-425abfec482c | Improved Secret Image Sharing Method By Encoding Shared Values With Authentication Bits | 2011 | ||
| 00745041-3636-4d18-bbec-783c4278c40d | A Self-Stabilizing Algorithm for Finding the Cutting Center of a Tree. | 2003 | ||
| 00964544-cbe2-4da9-bb5a-03333160eb34 | Fur Visualisation for Computer Game Engines and Real-Time Rendering | 2014 |
This script takes a few minutes to run on my machine. There are certainly some ways we could improve the script, but this is good enough as a first pass.
Now it’s time to import the data into Neo4j. If we’re using the Neo4j Desktop we can access the Neo4j Import Tool via the 'Terminal' tab within a database.
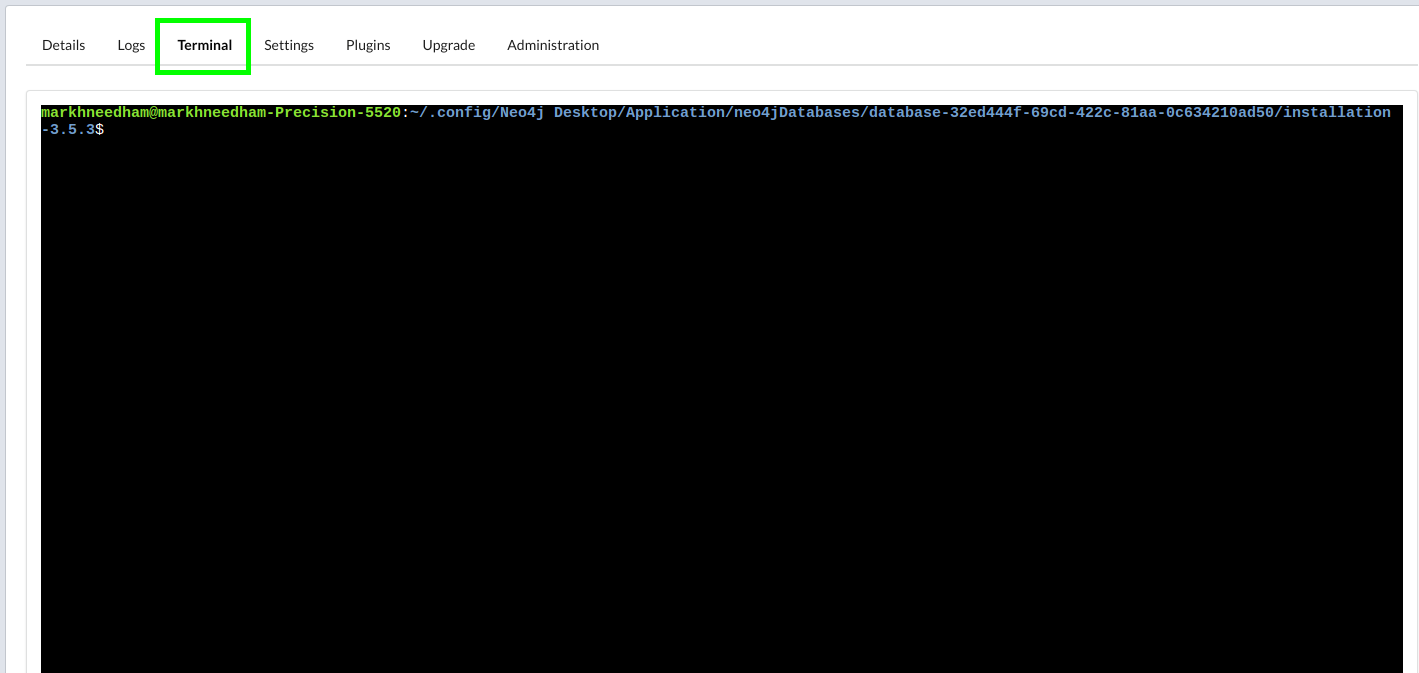
We can then paste in the script below:
| export DATA_DIR=/home/markhneedham/projects/dblp/data | |
| ./bin/neo4j-admin import \ | |
| --database=foo.db \ | |
| --nodes:Author=${DATA_DIR}/authors_header.csv,${DATA_DIR}/authors.csv \ | |
| --nodes:Article=${DATA_DIR}/articles_header.csv,${DATA_DIR}/articles.csv \ | |
| --nodes:Venue=${DATA_DIR}/venues_header.csv,${DATA_DIR}/venues.csv \ | |
| --relationships:REFERENCES=${DATA_DIR}/article_REFERENCES_article_header.csv,${DATA_DIR}/article_REFERENCES_article.csv \ | |
| --relationships:AUTHOR=${DATA_DIR}/article_AUTHOR_author_header.csv,${DATA_DIR}/article_AUTHOR_author.csv \ | |
| --relationships:VENUE=${DATA_DIR}/article_VENUE_venue_header.csv,${DATA_DIR}/article_VENUE_venue.csv | |
| --multiline-fields=true |
Let’s go through the arguments we’re passing to the Neo4j Import Tool. The line below imports our author nodes:
--nodes:Author=${DATA_DIR}/authors_header.csv,${DATA_DIR}/authors.csvThe syntax of this part of the command is --nodes:[:Label]=<"file1,file2,…">.
It treats the files that we provide as if they’re one big file, and the first line of the first file needs to contain the header line.
So in this line we’re saying that we want to create one node for each entry in the authors.csv file, and each of those nodes should have the label Author.
The line below creates relationships between our Author and Venue nodes:
--relationships:VENUE=${DATA_DIR}/article_VENUE_venue_header.csv,${DATA_DIR}/article_VENUE_venue.csvThe syntax of this part of the command is --relationships[:RELATIONSHIP_TYPE]=<"file1,file2,…">
Again, it treats the files we provide as if they’re one big file, so the first line of the first file must contain the header line.
In this line we’re saying that we want to create a relationship with the type VENUE for each entry in the article_VENUE_venue.csv file.
Now if we run the script, we’ll see the following output:
Neo4j version: 3.5.3
Importing the contents of these files into /home/markhneedham/.config/Neo4j Desktop/Application/neo4jDatabases/database-32ed444f-69cd-422c-81aa-0c634210ad50/installation-3.5.3/data/databases/graph.db:
Nodes:
:Author
/home/markhneedham/projects/dblp/data/authors_header.csv
/home/markhneedham/projects/dblp/data/authors.csv
:Article
/home/markhneedham/projects/dblp/data/articles_header.csv
/home/markhneedham/projects/dblp/data/articles.csv
:Venue
/home/markhneedham/projects/dblp/data/venues_header.csv
/home/markhneedham/projects/dblp/data/venues.csv
Relationships:
:REFERENCES
/home/markhneedham/projects/dblp/data/article_REFERENCES_article_header.csv
/home/markhneedham/projects/dblp/data/article_REFERENCES_article.csv
:AUTHOR
/home/markhneedham/projects/dblp/data/article_AUTHOR_author_header.csv
/home/markhneedham/projects/dblp/data/article_AUTHOR_author.csv
:VENUE
/home/markhneedham/projects/dblp/data/article_VENUE_venue_header.csv
/home/markhneedham/projects/dblp/data/article_VENUE_venue.csv
Available resources:
Total machine memory: 31.27 GB
Free machine memory: 1.93 GB
Max heap memory : 910.50 MB
Processors: 8
Configured max memory: 27.34 GB
High-IO: false
WARNING: heap size 910.50 MB may be too small to complete this import. Suggested heap size is 1.00 GBImport starting 2019-03-27 09:43:54.934+0000
Estimated number of nodes: 7.84 M
Estimated number of node properties: 24.08 M
Estimated number of relationships: 36.99 M
Estimated number of relationship properties: 0.00
Estimated disk space usage: 4.78 GB
Estimated required memory usage: 1.09 GB
IMPORT DONE in 2m 52s 306ms.
Imported:
4850632 nodes
37215467 relationships
15328803 properties
Peak memory usage: 1.08 GBAnd now let’s start the database and have a look at the graph we’ve imported:

About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.