
Neo4j: Pruning transaction logs more aggressively
One thing that new users of Neo4j when playing around with it locally is how much space the transaction logs can take up, especially when we’re creating and deleting lots of data while we get started. We can see this by running the following query a few times:
UNWIND range(0, 1000) AS id
CREATE (:Foo {id: id});
MATCH (f:Foo)
DELETE fThis query creates a bunch of data before immediately deleting it. We can now run the following command to see the state of the database:
:sysinfoWe’ll see this table:
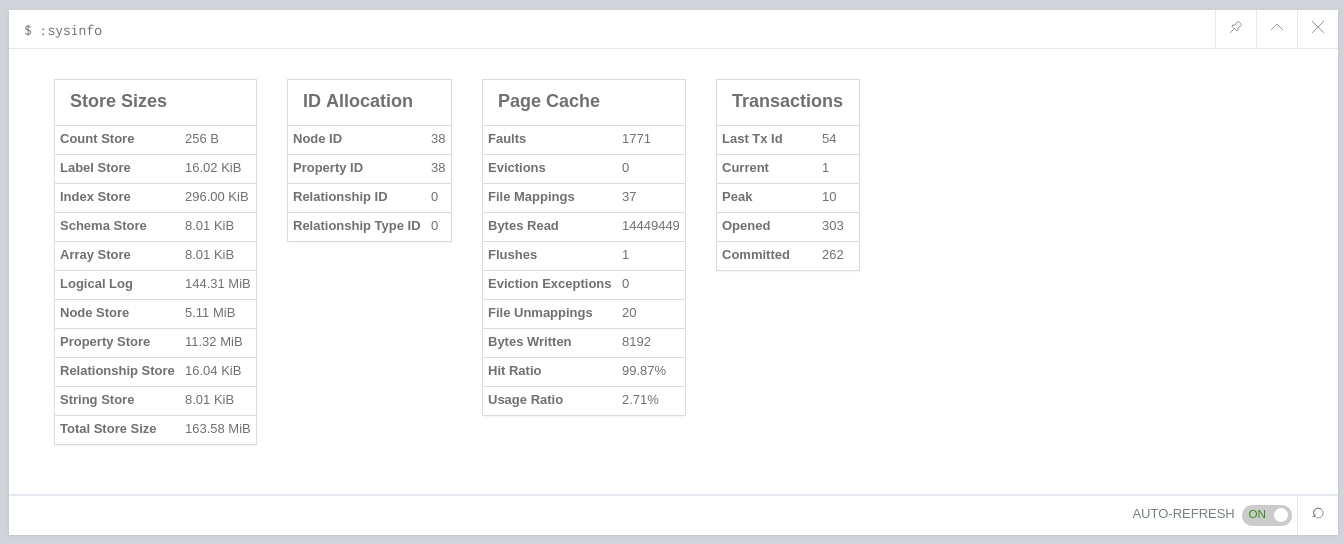
Most of the space is taken up by Logical Log, which is the aggregate size of Neo4j’s transaction logs.
These are the files in our data/databases/graph.db field that have the neostore.transaction.db prefix:
$ ls -alh data/databases/graph.db/neostore.transaction.db*
-rw-rw-r-- 1 markhneedham markhneedham 1.3M Dec 22 19:17 data/databases/graph.db/neostore.transaction.db.30
-rw-rw-r-- 1 markhneedham markhneedham 1.3M Dec 22 19:17 data/databases/graph.db/neostore.transaction.db.31
-rw-rw-r-- 1 markhneedham markhneedham 145M Dec 24 21:31 data/databases/graph.db/neostore.transaction.db.32Our latest log file is more than 100MB, and we might wonder why we need to keep around all those logs! We can run the following procedures to see the default config for checkpointing and transaction log pruning, which work together to control how many logs are kept around:
CALL dbms.listConfig("dbms.checkpoint.interval")
YIELD name, description, value
RETURN name, description, value
UNION
CALL dbms.listConfig("dbms.tx_log")
YIELD name, description, value
RETURN name, description, valueIf we run that procedure we’ll see this output:
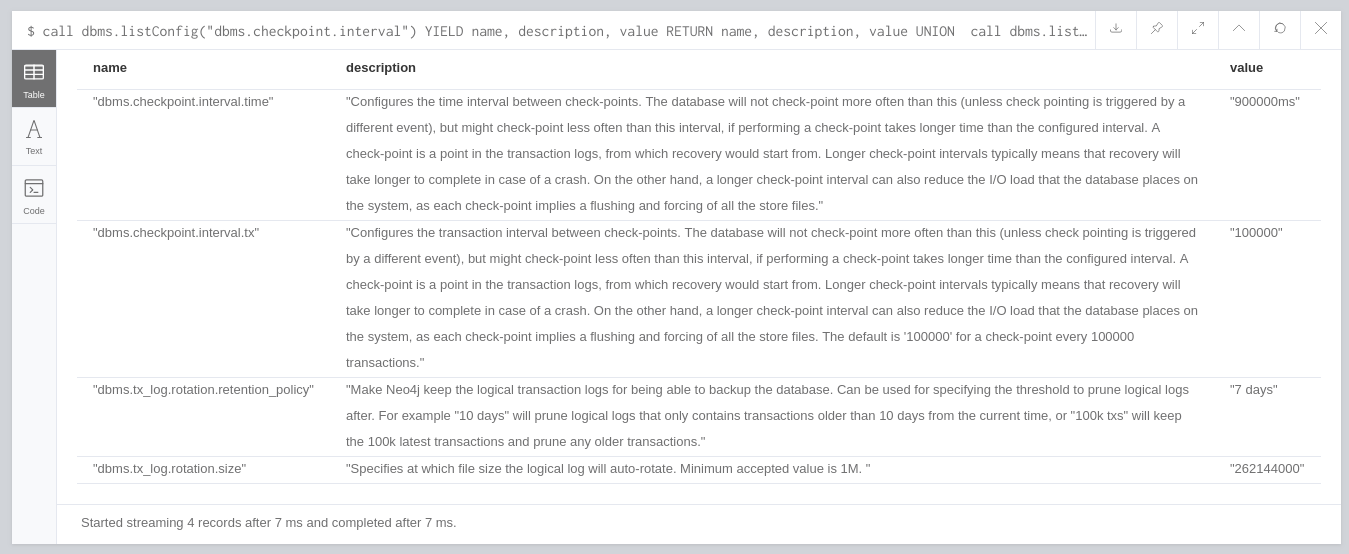
In summary:
-
Checkpointing is done every 900 seconds (15 minutes)
-
Checkpointing is done every 100,000 transactions
-
Transaction logs are kept for 7 days
-
Transaction log files are rotated when they reach 262,144,000 bytes (250MB)
These defaults are not a bad place to start for a production system, but we probably don’t need to keep around so many logs when we’re playing around with Neo4j locally. Chris Gioran has written an excellent article explaining these config options in more detail.
From the article I came up with the following config, which I think makes more sense when working locally:
dbms.checkpoint.interval.time=30s
dbms.checkpoint.interval.tx=1
dbms.tx_log.rotation.retention_policy=false
dbms.tx_log.rotation.size=1MSo now:
-
Checkpointing is done every 30 seconds
-
Checkpointing is done every 1 transactions
-
Minimal transaction logs are kept around
-
Transaction log files are rotated when they reach 1MB
If we run our first query again a few times while tailing logs/debug.log we’ll see the following output:
2018-12-24 21:43:20.132+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 56 checkpoint started...
2018-12-24 21:43:20.589+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 56 checkpoint completed in 457ms
2018-12-24 21:43:20.592+0000 INFO [o.n.k.i.t.l.p.LogPruningImpl] Pruned log versions 30-31, last checkpoint was made in version 33
2018-12-24 21:43:30.593+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 57 checkpoint started...
2018-12-24 21:43:30.716+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 57 checkpoint completed in 122ms
2018-12-24 21:43:30.736+0000 INFO [o.n.k.i.t.l.p.LogPruningImpl] Pruned log versions 32-32, last checkpoint was made in version 34
2018-12-24 21:43:40.737+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 65 checkpoint started...
2018-12-24 21:43:40.982+0000 INFO [o.n.k.i.t.l.c.CheckPointerImpl] Checkpoint triggered by scheduler for tx count threshold @ txId: 65 checkpoint completed in 245ms
2018-12-24 21:43:40.995+0000 INFO [o.n.k.i.t.l.p.LogPruningImpl] Pruned log versions 33-40, last checkpoint was made in version 42We can see that logs are now being pruned much more aggressively, and if we run :sysinfo again we’ll see that the size of logical logs is now much less:
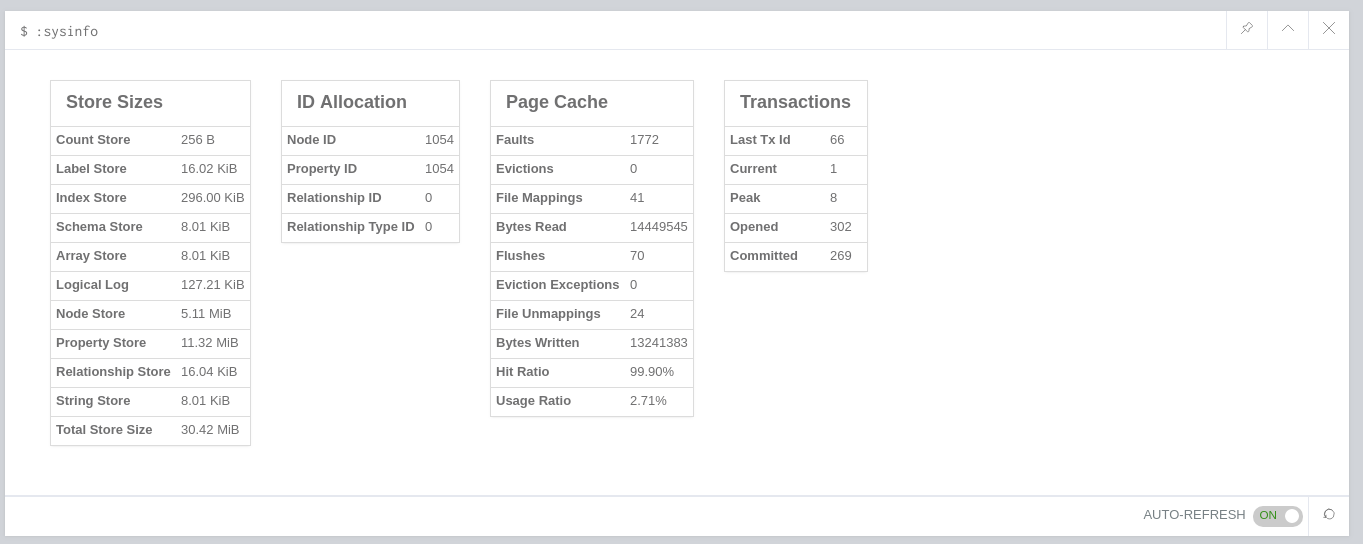
That’s much better!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.