
Neo4j Graph Algorithms: Calculating the cosine similarity of Game of Thrones episodes
A couple of years ago I wrote a blog post showing how to calculate cosine similarity on Game of Thrones episodes using scikit-learn, and with the release of Similarity Algorithms in the Neo4j Graph Algorithms library I thought it was a good time to revisit that post.
The dataset contains characters and episodes, and we want to calculate episode similarity based on the characters that appear in each episode. Before we run any algorithms we need to get the data into Neo4j.
Import the data
There are three CSV files that contain everything we need. First we’ll create one node per character:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/mneedham/neo4j-got/master/data/import/characters.csv"
AS row
MERGE (c:Character {id: row.link})
ON CREATE SET c.name = row.characterNext let’s create one node per episode:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/mneedham/neo4j-got/master/data/import/overview.csv"
AS row
MERGE (episode:Episode {id: toInteger(row.episodeId)})
ON CREATE SET
episode.season = toInteger(row.season),
episode.number = toInteger(row.episode),
episode.title = row.titleAnd finally let’s create a relationship for each episode in which a character appeared:
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/mneedham/neo4j-got/master/data/import/characters_episodes.csv"
AS row
MATCH (episode:Episode {id: TOINT(row.episodeId)})
MATCH (character:Character {id: row.character})
MERGE (character)-[:APPEARED_IN]->(episode)Calculating Cosine Similarity
Now that the data’s loaded we’re ready to calculate Cosine Similarity.
To do this we first need to create a vector indicating whether a character appeared in an episode or not. e.g. imagine that we have 3 characters - A, B, and C - and 2 episodes. A and B appear in the first episode and B and C appear in the second episode. We would represent that with the following vectors:
Episode 1 = [1, 1, 0]
Episode 2 = [0, 1, 1]We could then calculate the Cosine Similarity between those two episodes like this:
WITH [ {item: 1, weights: [1,1,0]}, {item: 2, weights: [0,1,1]}] AS data
CALL algo.similarity.cosine.stream(data)
YIELD item1, item2, similarity
RETURN item1, item2, similarityIf we run that query we’ll get this output:
+----------------------------+
| item1 | item2 | similarity |
+----------------------------+
| 1 | 2 | 0.5 |
+----------------------------+The output tells us that these episodes are 50% similar to each other. In this example we’ve used the Cosine Similarity procedure, but we could also use the function since we’re only calculating the similarity of a small number of items:
RETURN algo.similarity.cosine([1,1,0], [0,1,1]) AS similarityNow that we’ve covered the fundamentals of Cosine Similarity in Neo4j, let’s see how to run it on our dataset.
Creating One Hot Encodings for Episodes
We need to generate one vector per episode which we did in Python in the previous post. We also added the One Hot Encoding function makes it easy for us to now do this directly from Cypher.
If you want to read up on One Hot Encodings Rakshith Vasudev has a great blog post explaining it in more detail, but let’s quickly see how it works in Neo4j.
Imagine that we have 3 characters: Mark, Praveena, and Arya. We only want Praveena to be selected. We can do this by running the following function:
RETURN algo.ml.oneHotEncoding(["Mark", "Praveena", "Arya"], ["Praveena"]) AS embeddingThe first parameter contains a list of all the possible values. The second parameter contains a list of the ones that should be selected.
If we run the query we’ll see the following output:
+-----------+
| embedding |
+-----------+
| [0, 1, 0] |
+-----------+Remember that a 1 indicates that the character appears and a 0 indicates that they don’t. So in this case Mark and Arya didn’t appear, but Praveena did. Great!
Onto Game of Thrones! We can create a One Hot Encoding for our episodes by collecting lists of all characters and lists of characters by episode. The code to do that is as follows:
MATCH (c:Character)
WITH collect(c) AS characters
MATCH (e:Episode)
RETURN e, algo.ml.oneHotEncoding(characters, [(e)<-[:APPEARED_IN]-(c) | c]) AS embedding
LIMIT 1If we run that query we’ll see the following output:
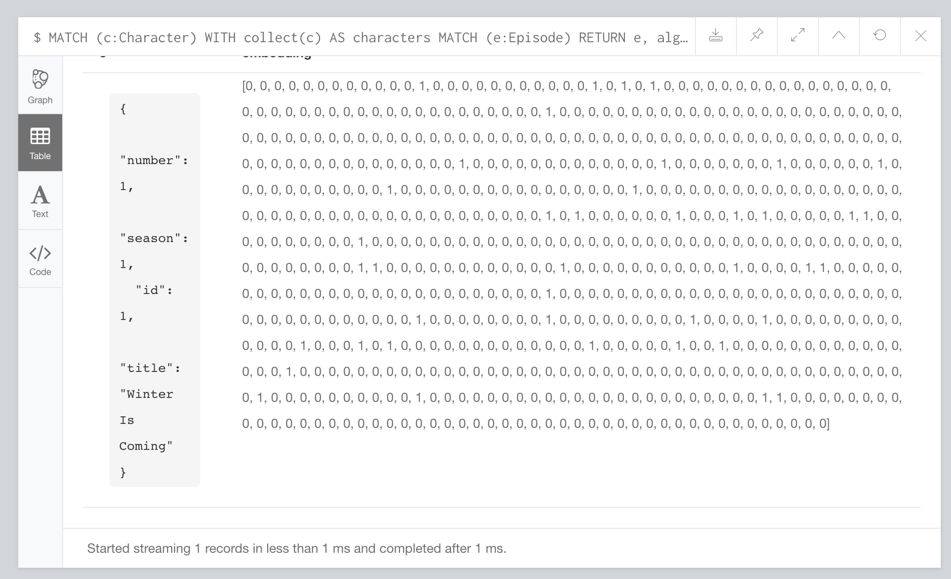
Calculating Cosine Similarity on Game of Thrones
Now we’re ready to run the Cosine Similarity algorithm. We extend the code above to do this:
MATCH (c:Character)
WITH collect(c) AS characters
MATCH (e:Episode)
WITH e, algo.ml.oneHotEncoding(characters, [(e)<-[:APPEARED_IN]-(c) | c]) AS embedding
WITH {item:id(e), weights: embedding} as userData
WITH collect(userData) as data
CALL algo.similarity.cosine.stream(data)
YIELD item1, item2, count1, count2, similarity
WITH algo.getNodeById(item1) AS episode1, algo.getNodeById(item2) AS episode2, similarity
RETURN "S" + episode1.season + "E" + episode1.number AS ep1,
"S" + episode2.season + "E" + episode2.number AS ep2,
similarity
ORDER BY similarity DESC
LIMIT 10The above code shows us the 10 most similar episodes. If we run that we’ll see this output:
+---------------------------------------+
| ep1 | ep2 | similarity |
+---------------------------------------+
| "S1E1" | "S1E2" | 0.6963730592072542 |
| "S1E3" | "S1E4" | 0.6914173051223087 |
| "S1E8" | "S1E9" | 0.6869464497590778 |
| "S2E8" | "S2E10" | 0.6869037302955033 |
| "S3E6" | "S3E7" | 0.6819943394704735 |
| "S2E6" | "S2E7" | 0.6813598225089799 |
| "S1E9" | "S1E10" | 0.6796436827080402 |
| "S1E4" | "S1E5" | 0.6698105143372366 |
| "S1E8" | "S1E10" | 0.6624062584864754 |
| "S4E4" | "S4E5" | 0.6518358737330703 |
+---------------------------------------+This query streamed the results back, but we can also run a non streaming version which by default will just return statistics about the similarity scores. We can run the non streaming version like this:
MATCH (c:Character)
WITH collect(c) AS characters
MATCH (e:Episode)
WITH e, algo.ml.oneHotEncoding(characters, [(e)<-[:APPEARED_IN]-(c) | c]) AS embedding
WITH {item:id(e), weights: embedding} as userData
WITH collect(userData) as data
CALL algo.similarity.cosine(data)
YIELD nodes, p50, p75, p90, p99, p999, p100
RETURN nodes, p50, p75, p90, p99, p999, p100And we’ll see these results:
+-------------------------------------------------------------------------------------------------------------------------------------+
| nodes | p50 | p75 | p90 | p99 | p999 | p100 |
+-------------------------------------------------------------------------------------------------------------------------------------+
| 60 | 0.2863004207611084 | 0.3595731258392334 | 0.4467923641204834 | 0.6070897579193115 | 0.6869466304779053 | 0.6963765621185303 |
+-------------------------------------------------------------------------------------------------------------------------------------+The fields starting with p represent percentiles.
So 50% of the similarity scores are 0.2863 or higher, and 99% of them are 0.607 or higher.
We probably aren’t that interested in the lower similarity scores so we can filter those out by passing in the similarityCutoff parameter.
We can also choose to create relationships between similar episodes by passing in the write: true parameter.
The write parameter must be used in combination with a similarityCutoff value greater than 0 as we don’t want to create relationships between nodes that are not similar at all.
We can also pass in the topK parameter to limit the number of similar relationships we create per node.
Let’s say that we want to find the 3 most similar episodes.
The following query does this:
MATCH (c:Character)
WITH collect(c) AS characters
MATCH (e:Episode)
WITH e, algo.ml.oneHotEncoding(characters, [(e)<-[:APPEARED_IN]-(c) | c]) AS embedding
WITH {item:id(e), weights: embedding} as userData
WITH collect(userData) as data
CALL algo.similarity.cosine(data, {similarityCutoff: 0.2863, write: true, topK: 3})
YIELD nodes, p50, p75, p90, p99, p999, p100
RETURN nodes, p50, p75, p90, p99, p999, p100We can now write a query to find the most similar episodes:
MATCH (e:Episode {season: 1, number: 1})-[similar:SIMILAR]->(other)
RETURN "S" + other.season + "E" + other.number AS episode, similar.score AS scoreThat will return the following output:
+-------------------------------+
| episode | score |
+-------------------------------+
| "S1E2" | 0.6963730592072542 |
| "S1E4" | 0.5467175210508692 |
| "S1E3" | 0.48196269271187986 |
+-------------------------------+Hopefully that gives you some ideas of what you can do with the similarity algorithms. If you have any suggestions for other things you’d like to see let me know in the comments and I’ll see what I can do.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.