
Neo4j: Cypher - Detecting duplicates using relationships
I’ve been building a graph of computer science papers on and off for a couple of months and now that I’ve got a few thousand loaded in I realised that there are quite a few duplicates.
They’re not duplicates in the sense that there are multiple entries with the same identifier but rather have different identifiers but seem to be the same paper!
e.g. there are a couple of papers titled 'Authentication in the Taos operating system':
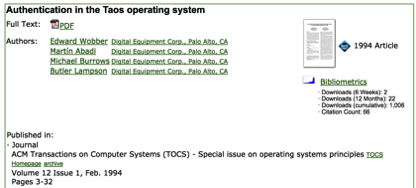

This is the same paper published in two different journals as far as I can tell.
Now in this case it’s quite easy to just do a string similarity comparison of the titles of these papers and realise that they’re identical. I’ve previously use the excellent dedupe library to do this and there’s also an excellent talk from Berlin Buzzwords 2014 where the author uses locality-sensitive hashing to achieve a similar outcome.
However, I was curious whether I could use any of the relationships these papers have to detect duplicates rather than just relying on string matching.
This is what the graph looks like:

We’ll start by writing a query to see how many common references the different Taos papers have:
MATCH (r:Resource {id: "168640"})-[:REFERENCES]->(other)
WITH r, COLLECT(other) as myReferences
UNWIND myReferences AS reference
OPTIONAL MATCH path = (other)-[:REFERENCES]->(reference)
WITH other, COUNT(path) AS otherReferences, SIZE(myReferences) AS myReferences
WITH other, 1.0 * otherReferences / myReferences AS similarity WHERE similarity > 0.5
RETURN other.id, other.title, similarity
ORDER BY similarity DESC
LIMIT 10╒════════╤═══════════════════════════════════════════╤══════════╕
│other.id│other.title │similarity│
╞════════╪═══════════════════════════════════════════╪══════════╡
│168640 │Authentication in the Taos operating system│1 │
├────────┼───────────────────────────────────────────┼──────────┤
│174614 │Authentication in the Taos operating system│1 │
└────────┴───────────────────────────────────────────┴──────────┘This query:
-
picks one of the Taos papers and finds its references
-
finds other papers which reference those same papers
-
calculates a similarity score based on how many common references they have
-
returns papers that have more than 50% of the same references with the most similar ones at the top
I tried it with other papers to see how it fared:
╒════════╤════════════════════════════════════════════════════════════════╤══════════════════╕
│other.id│other.title │similarity │
╞════════╪════════════════════════════════════════════════════════════════╪══════════════════╡
│74859 │Performance of Firefly RPC │1 │
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│77653 │Performance of the Firefly RPC │0.8333333333333334│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│110815 │The X-Kernel: An Architecture for Implementing Network Protocols│0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│96281 │Experiences with the Amoeba distributed operating system │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│74861 │Lightweight remote procedure call │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│106985 │The interaction of architecture and operating system design │0.6666666666666666│
├────────┼────────────────────────────────────────────────────────────────┼──────────────────┤
│77650 │Lightweight remote procedure call │0.6666666666666666│
└────────┴────────────────────────────────────────────────────────────────┴──────────────────┘╒════════╤══════════════════════════════════════════════════════════╤══════════════════╕
│other.id│other.title │similarity │
╞════════╪══════════════════════════════════════════════════════════╪══════════════════╡
│121160 │Authentication in distributed systems: theory and practice│1 │
├────────┼──────────────────────────────────────────────────────────┼──────────────────┤
│138874 │Authentication in distributed systems: theory and practice│0.9090909090909091│
└────────┴──────────────────────────────────────────────────────────┴──────────────────┘Sadly it’s not as simple as finding 100% matches on references! I expect the later revisions of a paper added more content and therefore additional references.
What if we look for author similarity as well?
MATCH (r:Resource {id: "121160"})-[:REFERENCES]->(other)
WITH r, COLLECT(other) as myReferences
UNWIND myReferences AS reference
OPTIONAL MATCH path = (other)-[:REFERENCES]->(reference)
WITH r, other, authorSimilarity, COUNT(path) AS otherReferences, SIZE(myReferences) AS myReferences
WITH r, other, authorSimilarity, 1.0 * otherReferences / myReferences AS referenceSimilarity
WHERE referenceSimilarity > 0.5
MATCH (r)<-[:AUTHORED]-(author)
WITH r, myReferences, COLLECT(author) AS myAuthors
UNWIND myAuthors AS author
OPTIONAL MATCH path = (other)<-[:AUTHORED]-(author)
WITH other, myReferences, COUNT(path) AS otherAuthors, SIZE(myAuthors) AS myAuthors
WITH other, myReferences, 1.0 * otherAuthors / myAuthors AS authorSimilarity
WHERE authorSimilarity > 0.5
RETURN other.id, other.title, referenceSimilarity, authorSimilarity
ORDER BY (referenceSimilarity + authorSimilarity) DESC
LIMIT 10╒════════╤══════════════════════════════════════════════════════════╤═══════════════════╤════════════════╕
│other.id│other.title │referenceSimilarity│authorSimilarity│
╞════════╪══════════════════════════════════════════════════════════╪═══════════════════╪════════════════╡
│121160 │Authentication in distributed systems: theory and practice│1 │1 │
├────────┼──────────────────────────────────────────────────────────┼───────────────────┼────────────────┤
│138874 │Authentication in distributed systems: theory and practice│0.9090909090909091 │1 │
└────────┴──────────────────────────────────────────────────────────┴───────────────────┴────────────────┘╒════════╤══════════════════════════════╤═══════════════════╤════════════════╕
│other.id│other.title │referenceSimilarity│authorSimilarity│
╞════════╪══════════════════════════════╪═══════════════════╪════════════════╡
│74859 │Performance of Firefly RPC │1 │1 │
├────────┼──────────────────────────────┼───────────────────┼────────────────┤
│77653 │Performance of the Firefly RPC│0.8333333333333334 │1 │
└────────┴──────────────────────────────┴───────────────────┴────────────────┘I’m sure I could find some other papers where neither of these similarities worked well but it’s an interesting start.
I think the next step is to build up a training set of pairs of documents that are and aren’t similar to each other. We could then train a classifier to determine whether two documents are identical.
But that’s for another day!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.