
Neo4j vs Relational: Refactoring - Extracting node/table
In my previous blog post I showed how to add a new property/field to a node with a label/record in a table for a football transfers dataset that I’ve been playing with.
After introducing this 'nationality' property I realised that I now had some duplication in the model:
</p>
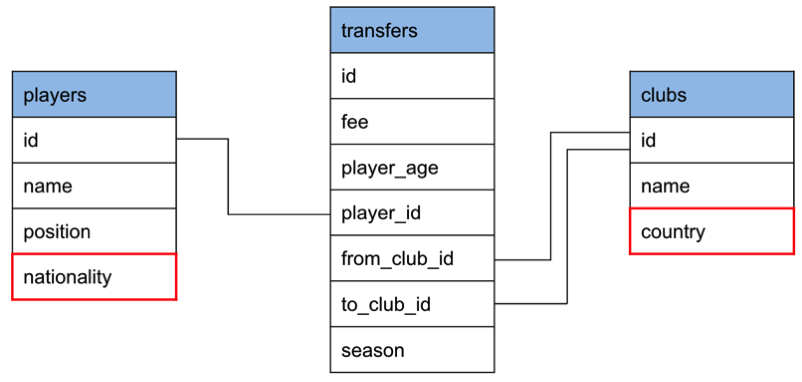
players.nationality and clubs.country are referring to the same countries but they’ve both got them stored as strings so we can’t ensure the integrity of our countries and ensure that we’re referring to the same country.
We have the same issue in the graph model as well:

This time Player.nationality and Club.country refer to the same countries.
We can solve our problem by introducing a countries table in the relational model and a set of nodes with a 'Country' label in the graph model. Let’s start with relational.
This is the model we’re driving towards:
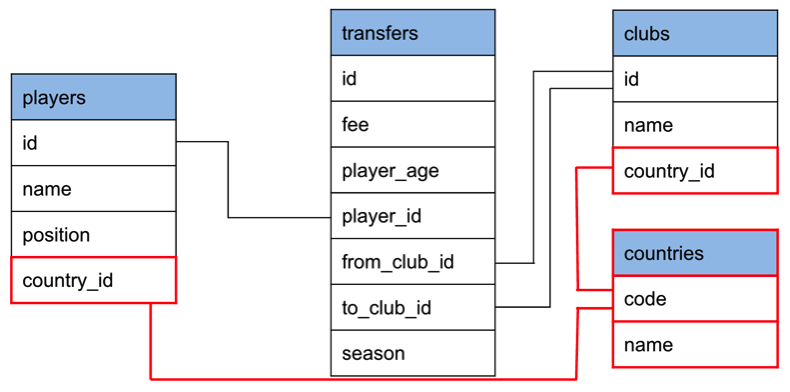
The first thing we need to do is create a countries table and populate it:
CREATE TABLE countries (
"code" character varying(3) NOT NULL PRIMARY KEY,
"name" character varying(50) NOT NULL
);INSERT INTO countries VALUES('MNE', 'Montenegro');
INSERT INTO countries VALUES('SWZ', 'Swaziland');
...Next let’s update the clubs table to reference the countries table:
ALTER TABLE clubs
ADD COLUMN country_id character varying(3)
REFERENCES countries(code);And let’s run a query to populate that column:
UPDATE clubs AS cl
SET country_id = c.code
FROM clubs
INNER JOIN countries AS c
ON c.name = clubs.country
WHERE cl.id = clubs.id;This query iterates over all the clubs, queries the country table to find the country id for that row and then stores it in the 'country_id' field. Finally we can remove the 'country' field:
ALTER TABLE clubs
DROP COLUMN country;Now we do the same drill for the players table:
ALTER TABLE players
ADD COLUMN country_id character varying(3)
REFERENCES countries(code);UPDATE players AS p
SET country_id = c.code
FROM players
INNER JOIN countries AS c
ON c.name = players.nationality
WHERE p.id = players.id;ALTER TABLE players
DROP COLUMN nationality;Now it’s time for the graph. This is the model we want to get to:
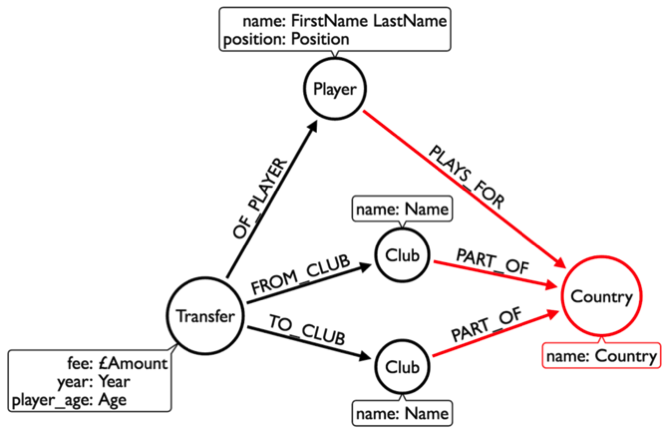
First we’ll create the countries:
CREATE CONSTRAINT ON (c:Country)
ASSERT c.id IS UNIQUELOAD CSV WITH HEADERS FROM "file:///countries.csv"
AS row
MERGE (country:Country {id: row.countryCode})
ON CREATE SET country.name = row.countryAnd now let’s get clubs and players to point at those countries nodes and get rid of their respective nationality/country properties:
MATCH (club:Club)
MATCH (country:Country {name: club.country})
MERGE (club)-[:PART_OF]->(country)
REMOVE club.countryMATCH (player:Player)
MATCH (country:Country {name: player.nationality})
MERGE (player)-[:PLAYS_FOR]->(country)
REMOVE player.nationalityAnd that’s it, we can now write queries against our new model.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.