
Neo4j: Specific relationship vs Generic relationship + property
For optimal traversal speed in Neo4j queries we should make our relationship types as specific as possible.
Let’s take a look at an example from the 'modelling a recommendations engine' talk I presented at Skillsmatter a couple of weeks ago.
I needed to decided how to model the 'RSVP' relationship between a Member and an Event. A person can RSVP 'yes' or 'no' to an event and I’d like to capture both of these responses.
i.e. we can choose between:
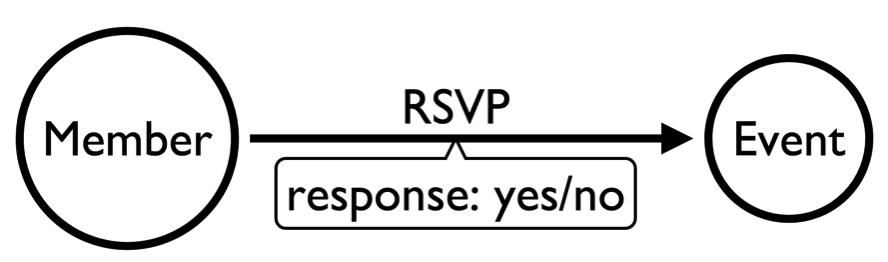
and:

When deciding on a model we mainly need to think about the types of queries that we want to write. We shouldn’t forget about updating the model but in my experience more time is spent querying graphs than updating them.
Let’s take a look at each of those in turn:
What queries do we want to write?
The first query was going to use previous 'yes' RSVPs as an indicator of interest for future events. We’re not interested in 'no' RSVPs for this query.
I started out with the generic RSVP relationship type with a 'response' property to distinguish between 'yes' and 'no':
MATCH (member:Member {name: "Mark Needham"})
MATCH (futureEvent:Event) WHERE futureEvent.time >= timestamp()
MATCH (futureEvent)<-[:HOSTED_EVENT]-(group)
OPTIONAL MATCH (member)-[rsvp:RSVPD {response: "yes"}]->(pastEvent)<-[:HOSTED_EVENT]-(group)
WHERE pastEvent.time < timestamp()
RETURN group.name, futureEvent.name, COUNT(rsvp) AS previousEvents
ORDER BY previousEvents DESCThis ran reasonably quickly but I was curious whether I could get the query to run any quicker by changing to the more specific model. Using the more specific relationship type our query reads:
MATCH (member:Member {name: "Mark Needham"})
MATCH (futureEvent:Event) WHERE futureEvent.time >= timestamp()
MATCH (futureEvent)<-[:HOSTED_EVENT]-(group)
OPTIONAL MATCH (member)-[rsvp:RSVP_YES]->(pastEvent)<-[:HOSTED_EVENT]-(group)
WHERE pastEvent.time < timestamp()
RETURN group.name,
futureEvent.name,
COUNT(rsvp) AS previousEvents
ORDER BY previousEvents DESCWe can now profile our query and compare the db hits of both solutions:
RSVPD {response: "yes"}
Cypher version: CYPHER 2.3, planner: COST. 688635 total db hits in 232 ms.
RSVP_YES
Cypher version: CYPHER 2.3, planner: COST. 559866 total db hits in 207 ms.So we get a slight gain by using the more specific relationship type. The reason the db hits is lower is partly because we’ve removed the need to lookup the 'response' property on every 'RSVP' property and check that it matches 'yes'. We’re also evaluating fewer relationships since we only look at positive RSVPs, negative ones are ignored.
Our next query might be to capture all the RSVPs made by a member and list them alongside the events:
MATCH (member:Member {name: "Mark Needham"})-[rsvp:RSVPD]->(event)
WHERE event.time < timestamp()
RETURN event.name, event.time, rsvp.response
ORDER BY event.time DESCMATCH (member:Member {name: "Mark Needham"})-[rsvp:RSVP_YES|:RSVP_NO]->(event)
WHERE event.time < timestamp()
RETURN event.name, event.time, CASE TYPE(rsvp) WHEN "RSVP_YES" THEN "yes" ELSE "no" END AS response
ORDER BY event.time DESCAgain we see a marginal db hits win for the more specific relationship type:
RSVPD {response: "yes"} / RSVPD {response: "no"}
Cypher version: CYPHER 2.3, planner: COST. 684 total db hits in 37 ms.
RSVP_YES / RSVP_NO
Cypher version: CYPHER 2.3, planner: COST. 541 total db hits in 24 ms.However, the query is quite unwieldy and unless we store the response as a property on the relationship the code to return 'yes' or 'no' is a bit awkward. The more specific approach query would become even more painful to deal with if we introduced the 'waitlist' RSVP which we’ve chosen to exclude.
Will we need to update the relationship?
Yes! Users are able to change their RSVP up until the event happens so we need to be able to handle that.
Let’s have a look at the queries we’d have to write to handle a change in RSVP using both models:
Generic relationship type
MATCH (event:Event {id: {event_id}})
MATCH (member:Member {id: {member_id}})
MERGE (member)-[rsvpRel:RSVPD {id: {rsvp_id}}]->(event)
ON CREATE SET rsvpRel.created = toint({mtime})
ON MATCH SET rsvpRel.lastModified = toint({mtime})
SET rsvpRel.response = {response}Specific relationship type
MATCH (event:Event {id: {event_id}})
MATCH (member:Member {id: {member_id}})
FOREACH(ignoreMe IN CASE WHEN {response} = "yes" THEN [1] ELSE [] END |
MERGE (member)-[rsvpYes:RSVP_YES {id: {rsvp_id}}]->(event)
ON CREATE SET rsvpYes.created = toint({mtime})
ON MATCH SET rsvpYes.lastModified = toint({mtime})
MERGE (member)-[oldRSVP:RSVP_NO]->(event)
DELETE oldRSVP
)
FOREACH(ignoreMe IN CASE WHEN {response} = "no" THEN [1] ELSE [] END |
MERGE (member)-[rsvpNo:RSVP_NO {id: {rsvp_id}}]->(event)
ON CREATE SET rsvpNo.created = toint({mtime})
ON MATCH SET rsvpNo.lastModified = toint({mtime})
MERGE (member)-[oldRSVP:RSVP_YES]->(event)
DELETE oldRSVP
)As you can see, the code to update an RSVP is more complicated when using the specific relationship type due in part to Cypher not yet having first class support for conditionals.
In summary, for our meetup.com model we gain speed improvements by using more specific relationship types but at the expense of some more complicated read queries and a significantly more convoluted update query.
Depending on the cardinality of relationships in your model your mileage may vary but it’s worth doing some profiling to compare all your options.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.