
Neo4j: MERGE'ing on super nodes
In my continued playing with the Chicago crime data set I wanted to connect the crimes committed to their position in the FBI crime type hierarchy.
These are the sub graphs that I want to connect:
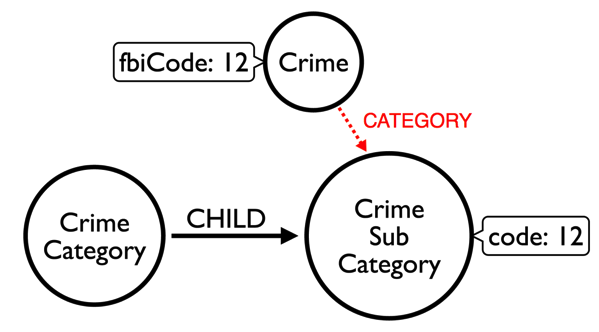
We have a 'fbiCode' on each 'Crime' node which indicates which 'Crime Sub Category' the crime belongs to.
I started with the following query to connect the nodes together:
MATCH (crime:Crime)
WITH crime SKIP {skip} LIMIT 10000
MATCH (subCat:SubCategory {code: crime.fbiCode})
MERGE (crime)-[:CATEGORY]->(subCat)
RETURN COUNT(*) AS crimesProcessedI had this running inside a Python script which incremented 'skip' by 10,000 on each iteration as long as 'crimesProcessed' came back with a value > 0.
To start with the 'CATEGORY' relationships were being created very quickly but it slowed down quite noticeably about 1 million nodes in.
I profiled the queries but the query plans didn’t show anything obviously wrong. My suspicion was that I had a super node problem where the cypher run time was iterating through all of the sub category’s relationships to check whether one of them pointed to the crime on the other side of the 'MERGE' statement.
I cancelled the import job and wrote a query to check how many relationships each sub category had. It varied from 1,000 to 93,000 somewhat confirming my suspicion.
Michael suggested tweaking the query to use the shortestpath function to check for the existence of the relationship and then use the 'CREATE' clause to create it if it didn’t exist.
The neat thing about the shortestpath function is that it will start from the side with the lowest cardinality and as soon as it finds a relationship it will stop searching. Let’s have a look at that version of the query:
MATCH (crime:Crime)
WITH crime SKIP {skip} LIMIT 10000
MATCH (subCat:SubCategory {code: crime.fbiCode})
WITH crime, subCat, shortestPath((crime)-[:CATEGORY]->(subCat)) AS path
FOREACH(ignoreMe IN CASE WHEN path is NULL THEN [1] ELSE [] END |
CREATE (crime)-[:CATEGORY]->(subCat))
RETURN COUNT(*)This worked much better - 10,000 nodes processed in ~ 2.5 seconds - and the time remained constant as more relationships were added. This allowed me to create all the category nodes but we can actually do even better if we use CREATE UNIQUE instead of MERGE
MATCH (crime:Crime)
WITH crime SKIP {skip} LIMIT 10000
MATCH (subCat:SubCategory {code: crime.fbiCode})
CREATE UNIQUE (crime)-[:CATEGORY]->(subCat)
RETURN COUNT(*) AS crimesProcessedUsing this query 10,000 nodes took ~ 250ms -900ms second to process which means we can process all the nodes in 5-6 minutes - good times!
I’m not super familiar with the 'CREATE UNIQUE' code so I’m not sure that it’s always a good substitute for 'MERGE' but on this occasion it does the job.
The lesson for me here is that if a query is taking longer than you think it should try and use other constructs / a combination of other constructs and see whether things improve - they just might!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.