
Neo4j: From JSON to CSV to LOAD CSV via jq
In my last blog post I showed how to import a Chicago crime categories & sub categories JSON document using Neo4j’s cypher query language via the py2neo driver. While this is a good approach for people with a developer background, many of the users I encounter aren’t developers and favour using Cypher via the Neo4j browser.
If we’re going to do this we’ll need to transform our JSON document into a CSV file so that we can use the LOAD CSV command on it. Michael pointed me to the jq tool which comes in very handy.
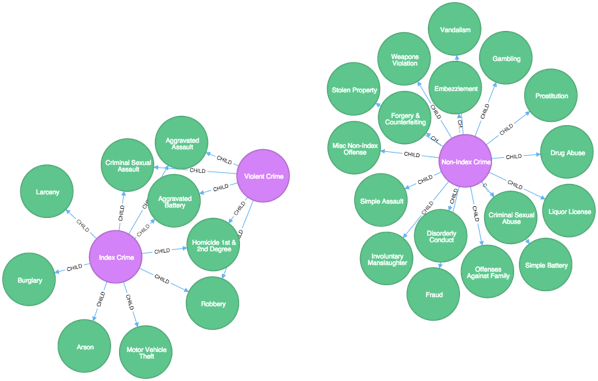
To recap, this is a part of the JSON file:
{
"categories": [
{
"name": "Index Crime",
"sub_categories": [
{
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
},
]
},
{
"name": "Non-Index Crime",
"sub_categories": [
{
"code": "01B",
"description": "Involuntary Manslaughter"
},
]
},
{
"name": "Violent Crime",
"sub_categories": [
{
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
},
]
}
]
}We want to get one row for each sub category which contains three columns - category name, sub category code, sub category description.
First we need to pull out the categories:
$ jq ".categories[]" categories.json
{
"name": "Index Crime",
"sub_categories": [
{
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
},
]
}
{
"name": "Non-Index Crime",
"sub_categories": [
{
"code": "01B",
"description": "Involuntary Manslaughter"
},
]
}
{
"name": "Violent Crime",
"sub_categories": [
{
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
},
]
}Next we want to create a row for each sub category with the category alongside it. We can use the pipe function to combine the two selectors:
$ jq ".categories[] | {name: .name, sub_category: .sub_categories[]}" categories.json
{
"name": "Index Crime",
"sub_category": {
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
}
}
...
{
"name": "Non-Index Crime",
"sub_category": {
"code": "01B",
"description": "Involuntary Manslaughter"
}
}
...
{
"name": "Violent Crime",
"sub_category": {
"code": "01A",
"description": "Homicide 1st & 2nd Degree"
}
}Now we want to un-nest the sub category:
$ jq ".categories[] | {name: .name, sub_category: .sub_categories[]} | [.name, .sub_category.code, .sub_category.description]" categories.json
[
"Index Crime",
"01A",
"Homicide 1st & 2nd Degree"
]
[
"Non-Index Crime",
"01B",
"Involuntary Manslaughter"
]
[
"Violent Crime",
"01A",
"Homicide 1st & 2nd Degree"
]And finally let’s use the @csv filter to generate CSV lines:
$ jq ".categories[] | {name: .name, sub_category: .sub_categories[]} | [.name, .sub_category.code, .sub_category.description] | @csv" categories.json
"\"Index Crime\",\"01A\",\"Homicide 1st & 2nd Degree\""
"\"Index Crime\",\"02\",\"Criminal Sexual Assault\""
"\"Index Crime\",\"03\",\"Robbery\""
"\"Index Crime\",\"04A\",\"Aggravated Assault\""
"\"Index Crime\",\"04B\",\"Aggravated Battery\""
"\"Index Crime\",\"05\",\"Burglary\""
"\"Index Crime\",\"06\",\"Larceny\""
"\"Index Crime\",\"07\",\"Motor Vehicle Theft\""
"\"Index Crime\",\"09\",\"Arson\""
"\"Non-Index Crime\",\"01B\",\"Involuntary Manslaughter\""
"\"Non-Index Crime\",\"08A\",\"Simple Assault\""
"\"Non-Index Crime\",\"08B\",\"Simple Battery\""
"\"Non-Index Crime\",\"10\",\"Forgery & Counterfeiting\""
"\"Non-Index Crime\",\"11\",\"Fraud\""
"\"Non-Index Crime\",\"12\",\"Embezzlement\""
"\"Non-Index Crime\",\"13\",\"Stolen Property\""
"\"Non-Index Crime\",\"14\",\"Vandalism\""
"\"Non-Index Crime\",\"15\",\"Weapons Violation\""
"\"Non-Index Crime\",\"16\",\"Prostitution\""
"\"Non-Index Crime\",\"17\",\"Criminal Sexual Abuse\""
"\"Non-Index Crime\",\"18\",\"Drug Abuse\""
"\"Non-Index Crime\",\"19\",\"Gambling\""
"\"Non-Index Crime\",\"20\",\"Offenses Against Family\""
"\"Non-Index Crime\",\"22\",\"Liquor License\""
"\"Non-Index Crime\",\"24\",\"Disorderly Conduct\""
"\"Non-Index Crime\",\"26\",\"Misc Non-Index Offense\""
"\"Violent Crime\",\"01A\",\"Homicide 1st & 2nd Degree\""
"\"Violent Crime\",\"02\",\"Criminal Sexual Assault\""
"\"Violent Crime\",\"03\",\"Robbery\""
"\"Violent Crime\",\"04A\",\"Aggravated Assault\""
"\"Violent Crime\",\"04B\",\"Aggravated Battery\""The only annoying thing about this output is that all the double quotes are escaped. We can sort that out by passing the '-r' flag when we call jq:
$ jq -r ".categories[] | {name: .name, sub_category: .sub_categories[]} | [.name, .sub_category.code, .sub_category.description] | @csv" categories.json
"Index Crime","01A","Homicide 1st & 2nd Degree"
"Index Crime","02","Criminal Sexual Assault"
"Index Crime","03","Robbery"
"Index Crime","04A","Aggravated Assault"
"Index Crime","04B","Aggravated Battery"
"Index Crime","05","Burglary"
"Index Crime","06","Larceny"
"Index Crime","07","Motor Vehicle Theft"
"Index Crime","09","Arson"
"Non-Index Crime","01B","Involuntary Manslaughter"
"Non-Index Crime","08A","Simple Assault"
"Non-Index Crime","08B","Simple Battery"
"Non-Index Crime","10","Forgery & Counterfeiting"
"Non-Index Crime","11","Fraud"
"Non-Index Crime","12","Embezzlement"
"Non-Index Crime","13","Stolen Property"
"Non-Index Crime","14","Vandalism"
"Non-Index Crime","15","Weapons Violation"
"Non-Index Crime","16","Prostitution"
"Non-Index Crime","17","Criminal Sexual Abuse"
"Non-Index Crime","18","Drug Abuse"
"Non-Index Crime","19","Gambling"
"Non-Index Crime","20","Offenses Against Family"
"Non-Index Crime","22","Liquor License"
"Non-Index Crime","24","Disorderly Conduct"
"Non-Index Crime","26","Misc Non-Index Offense"
"Violent Crime","01A","Homicide 1st & 2nd Degree"
"Violent Crime","02","Criminal Sexual Assault"
"Violent Crime","03","Robbery"
"Violent Crime","04A","Aggravated Assault"
"Violent Crime","04B","Aggravated Battery"Excellent. The only thing left is to write a header and then direct the output into a CSV file and get it into Neo4j:
$ echo "category,sub_category_code,sub_category_description" > categories.csv
$ jq -r ".categories[] |
{name: .name, sub_category: .sub_categories[]} |
[.name, .sub_category.code, .sub_category.description] |
@csv " categories.json >> categories.csv$ head -n10 categories.csv
category,sub_category_code,sub_category_description
"Index Crime","01A","Homicide 1st & 2nd Degree"
"Index Crime","02","Criminal Sexual Assault"
"Index Crime","03","Robbery"
"Index Crime","04A","Aggravated Assault"
"Index Crime","04B","Aggravated Battery"
"Index Crime","05","Burglary"
"Index Crime","06","Larceny"
"Index Crime","07","Motor Vehicle Theft"
"Index Crime","09","Arson"LOAD CSV WITH HEADERS FROM "file:///Users/markneedham/projects/neo4j-spark-chicago/categories.csv" AS row
MERGE (c:CrimeCategory {name: row.category})
MERGE (sc:SubCategory {code: row.sub_category_code})
ON CREATE SET sc.description = row.sub_category_description
MERGE (c)-[:CHILD]->(sc)And that’s it!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.