
Neo4j: Using aliases to handle messy data
One of the common problems when building data heavy applications is that names of things in the domain are often named differently depending on which system you get the data from.
This means that we’ll typically end up running the data from different sources through a normalisation process to ensure that we have consistent naming in the database:
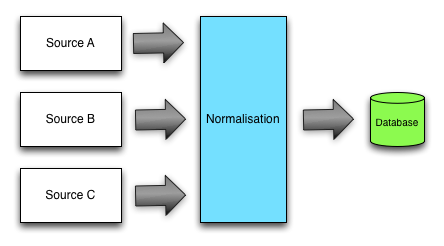
I’ve recently started linking the football stadium a match was played in to the match in my football graph but unfortunately different match compilers use different spellings or even names for the same stadium.
My first instinct was to write a normalisation layer but instead I decided to store the stadium names as they were but separately create an 'alias' relationship back in to the correct spelling.
The model looks like this:
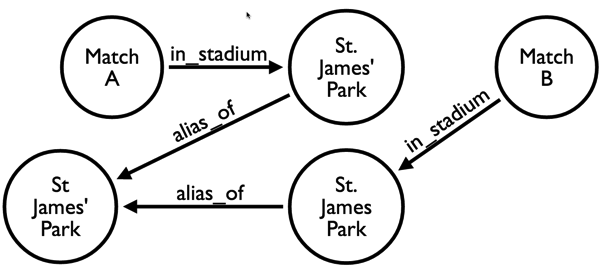
I add a 'Stadium' label to all the stadiums which means that if we do a query to find the number of games at each stadium we’ll get back games at the misspelled versions too:
MATCH (stadium:Stadium)<-[:in_stadium]-(game)
RETURN stadium.name, count(game) AS games
ORDER BY games DESC==> +-------------------------------+
==> | stadium.name | games |
==> +-------------------------------+
==> | "Craven Cottage" | 57 |
==> | "Villa Park" | 57 |
==> | "Anfield" | 57 |
==> | "Stamford Bridge" | 57 |
==> | "Britannia Stadium" | 57 |
==> | "Emirates Stadium" | 57 |
==> | "Etihad Stadium" | 57 |
==> | "Stadium of Light" | 57 |
==> | "Old Trafford" | 57 |
==> | "The Hawthorns" | 57 |
==> | "White Hart Lane" | 57 |
==> | "Goodison Park" | 57 |
==> | "DW Stadium" | 39 |
==> | "Molineux Stadium" | 38 |
==> | "Liberty Stadium" | 38 |
==> | "Ewood Park" | 38 |
==> | "Carrow Road" | 38 |
==> | "Reebok Stadium" | 38 |
==> | "Loftus Road Stadium" | 37 |
==> | "St James' Park" | 34 |
==> | "Upton Park" | 33 |
==> | "Bloomfield Road" | 19 |
==> | "Madejski Stadium" | 19 |
==> | "St. James' Park" | 19 |
==> | "St Andrews Stadium" | 19 |
==> | "St. Mary's Stadium" | 19 |
==> | "The DW Stadium" | 18 |
==> | "Boleyn Ground" | 5 |
==> | "St. James Park" | 4 |
==> | "Loftus Road" | 1 |
==> +-------------------------------+
==> 30 rowsWe only want to show the proper spellings of stadiums which we can do with the following query:
MATCH (stadium:Stadium)<-[:alias_of*0..1]-()<-[:in_stadium]-(game)
WHERE NOT(stadium-[:alias_of]->())
return stadium.name, count(game) AS games
ORDER BY games DESCHere we get all the stadiums, then get any incoming aliases and find the games played in those stadiums. We then filter out any stadium which has an outgoing 'alias_of' relationship because that indicates that the node isn’t the original node for the stadium.
If we run the query we’ll get the expected result:
==> +-------------------------------+
==> | stadium.name | games |
==> +-------------------------------+
==> | "St James' Park" | 57 |
==> | "Craven Cottage" | 57 |
==> | "Villa Park" | 57 |
==> | "Anfield" | 57 |
==> | "Stamford Bridge" | 57 |
==> | "Britannia Stadium" | 57 |
==> | "Emirates Stadium" | 57 |
==> | "Etihad Stadium" | 57 |
==> | "Stadium of Light" | 57 |
==> | "Old Trafford" | 57 |
==> | "The Hawthorns" | 57 |
==> | "White Hart Lane" | 57 |
==> | "The DW Stadium" | 57 |
==> | "Goodison Park" | 57 |
==> | "Loftus Road Stadium" | 38 |
==> | "Molineux Stadium" | 38 |
==> | "Upton Park" | 38 |
==> | "Liberty Stadium" | 38 |
==> | "Ewood Park" | 38 |
==> | "Carrow Road" | 38 |
==> | "Reebok Stadium" | 38 |
==> | "Bloomfield Road" | 19 |
==> | "Madejski Stadium" | 19 |
==> | "St Andrews Stadium" | 19 |
==> | "St. Mary's Stadium" | 19 |
==> +-------------------------------+
==> 25 rowsThe nice thing about this approach is that I only need to collect aliases in one place and I can just import the data as is from the source.
On the other hand it does add some complexity to queries as you need to take aliases into account each time.
I’d love to hear your thoughts on what you think of this approach.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.