
Incrementally rolling out machines with a new puppet role
Last week Jason and I with (a lot of) help from Tim have been working on moving several of our applications from Passenger to Unicorn and decided that the easiest way to do this was to create a new set of nodes with this setup.
The architecture we’re working with looks like this at a VM level:
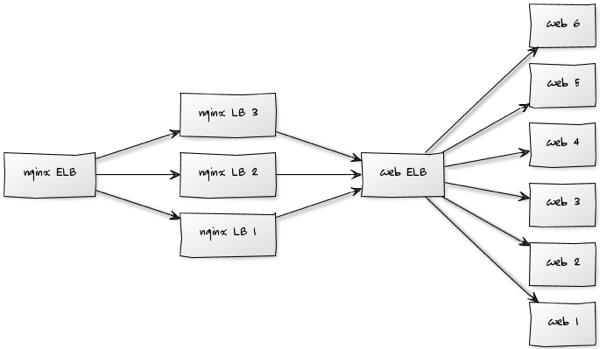
The 'nginx LB' nodes are responsible for routing all the requests to their appropriate application servers and the 'web' nodes serve the different applications initially using Passenger.
We started off by creating a new 'nginx LB' node which we pointed to a new 'web ELB' and just put one 'unicorn web' node behind it so that we could test everything was working.
We then pointed 'www.uswitch.com' at the IP of our new 'nginx LB' node in our /etc/hosts file and checked that the main flows through the various applications were working correctly.
Once we were happy this was working correctly we increased the number of 'unicorn web' nodes to three and then repeated our previous checks while tailing the log files across the three machines to make sure everything was ok.
The next step was to send some of the real traffic to the new nodes and check whether they were able to handle it.
Initially we thought that we could put our 'unicorn web' nodes alongside the 'web' nodes but we realised that we’d made some changes on our new 'nginx LB' nodes which meant that the 'unicorn web' nodes needed to receive requests proxies through there rather than from the old style node.
A combination of Jason and Sid came up with the idea of just plugging our new 'nginx LB' into the 'nginx ELB' and having the processing of the whole request treated separately.
Our intermediate architecture therefore looked like this:
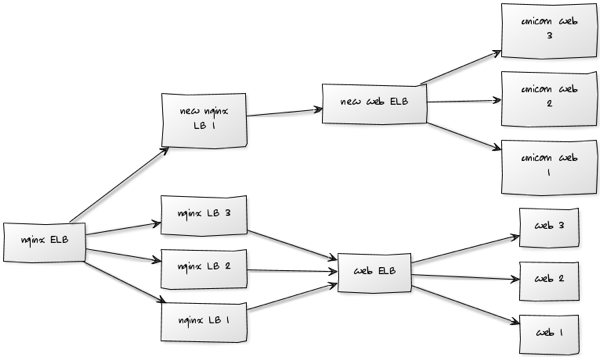
We initially served 1/4 of the requests from the Unicorn and watched the performance of the nodes via New Relic to check that everything was working expected.
One thing we did notice was that the CPU usage on the Unicorn nodes was really high because we’d set up each Unicorn process with 5 workers which meant that we had 25 workers on the VM in total. In comparison our Passenger instances used 5 workers in total.
Once we’d sorted that out we removed one of the 'nginx LB' nodes from the 'nginx ELB' and served 1/3 of the traffic from our new stack.
We didn’t see any problems so we removed all the 'nginx LB' nodes and served all the traffic from our new stack for half an hour.
Again we didn’t notice any problems so our next step before we can decommission the old nodes is to run the new stack for a day and iron out any problems before using it for real.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.