
neo4j: Multiple starting nodes by index lookup
I spent a bit of time this evening extracting some data from the ThoughtWorks graph for our marketing team who were interested in anything related to our three European offices in London, Manchester and Hamburg.
The most interesting things we can explore relate to the relationship between people and the offices.
The model around people and offices looks like this:
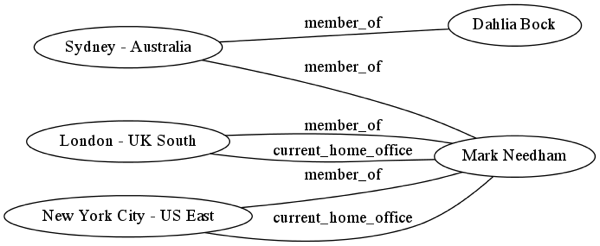
I added a 'current_home_office' relationship to make it easier to quickly get to the nodes of people who are currently working in a specific office.
I previously had to use a bit of a convoluted query to achieve the same thing and while the 'current_home_office' relationship would need to be maintained as people move offices since I’m just playing around with this data it makes my life much easier.
I wanted to find the number of different offices that people in Europe had worked in which I’ve previously calculated by running three separate queries and manually compiling the results:
START office=node:offices(name = "London - UK South")
MATCH person-[:current_home_office]->office, person-[:member_of]->otherOffice
RETURN distinct person.name, count(distinct(otherOffice)) AS offices, ID(person)
ORDER BY offices DESCSTART office=node:offices(name = "Manchester - UK North")
MATCH person-[:current_home_office]->office, person-[:member_of]->otherOffice
RETURN distinct person.name, count(distinct(otherOffice)) AS offices, ID(person)
ORDER BY offices DESCSTART office=node:offices(name = "Hamburg - Germany")
MATCH person-[:current_home_office]->office, person-[:member_of]->otherOffice
RETURN distinct person.name, count(distinct(otherOffice)) AS offices, ID(person)
ORDER BY offices DESCHere we start from a specific office and then match all the people who have this as their current home office. We also match all the offices that person has been a member of and then return a count of the unique offices the person has been to.
That approach works fine but it always felt like I was missing out on a simple way of doing all three of those queries in one since they are identical except for the office name.
What I wanted to do is define 3 starting nodes based on combining those Lucene index lookups into one which captured all 3 offices.
I started just trying to get the offices to return while following the Lucene query parser syntax documentation.
For some reason my initial attempt returned neither an error nor any results:
neo4j-sh (0)$ START office=node:offices("name:'London - UK South' OR name:'Hamburg - Germany'
OR name:'Manchester - UK North'") RETURN office
neo4j-sh (0)$When I switched the quotes around it was much happier:
neo4j-sh (0)$ START office=node:offices('name:"London - UK South" OR name:"Hamburg - Germany"
OR name:"Manchester - UK North"') RETURN office
==> +-------------------------------------------------------------------------+
==> | office |
==> +-------------------------------------------------------------------------+
==> | Node[4171]{type->"office",country->"UK",name->"Manchester - UK North"} |
==> | Node[4168]{type->"office",country->"UK",name->"London - UK South"} |
==> | Node[4177]{type->"office",country->"Germany",name->"Hamburg - Germany"} |
==> +-------------------------------------------------------------------------+
==> 3 rows, 0 ms
==>We can then reduce the queries which find how many offices people from ThoughtWorks Europe have worked in down to the following query:
START office=node:offices('name:"London - UK South" OR name:"Hamburg - Germany" OR name:"Manchester - UK North"')
MATCH person-[:current_home_office]->office, person-[:member_of]->otherOffice
RETURN distinct person.name, count(distinct(otherOffice)) AS offices
ORDER BY offices DESCAbout the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.