
Choosing where to put the complexity
On the current application I’m working on we need to make use of some data which comes from another system so we’ve created an import script which creates a copy of that data so that we can use it in our application.
In general we’ve been trying not to do too much manipulation of the data and keeping it close to the initial structure so that if something goes wrong with the import we can more easily trace the problem back to the original data source.
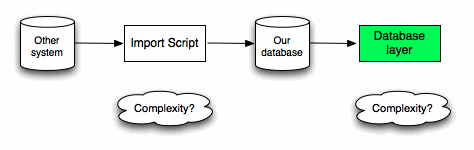
While that approach has generally been fine we recently had a situation where the way the data was stored in the original database was quite de-normalised and recreating that structure made some of the code in the data access layer quite messy.
We therefore decided to change the import script to normalise the data, thereby simplifying our database access code.
For now the complexity trade off seems ok because we haven’t had to change the schema that much so it’ll still be reasonably easy to track the data back to the source.
We currently don’t have any tests specifically around the data import because there’s not very much logic going on but if the complexity increases and we start to see problems with the import process then we’ll need to change that.
While we were having this conversation about where we should place the complexity I found it interesting that you could argue for each approach equally convincingly and neither really seemed definitively better - it was back to the world of trade offs!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.