
Working with external identifiers
As part of the ingestion process for our application we import XML documents and corresponding PDFs into a database and onto the file system respectively.
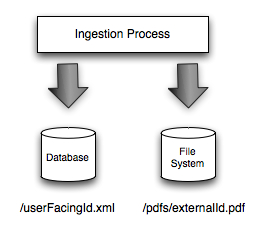
Since the user needs to be able to search for documents by the userFacingId we reference it by that identifier in the database and the web application.
Each document also has an external identifier and we use this to identify the PDFs on the file system.
We can’t use the raw userFacingId to do this because there are some documents which have the same ID when we import them.
Most of the time we only need to care about the userFacingId in the web application but when the user wants to download a PDF we need to map from the userFacingId to the </cite>externalId</cite> so we can locate the file on the file system.
The first implementation of this code involved some mapping code in the web application from which we constructed an externalId from a given userFacingId.
Unfortunately this logic drifted into a few different places and it started to become really difficult to tell whether we were dealing with a userFacingId or an externalId.
We wanted to try and isolate the translation logic into one place on the edge of the system but Pat pointed out that it would actually be simpler if we never had to care about the externalId in our code.
We changed the ingestion process to add the externalId to each document so that we’d be able to get hold of it when we needed to.
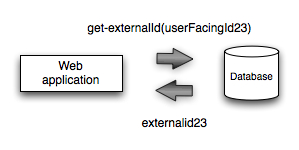
We had to change the design of the code so that whenever the user wants to download a PDF (for example) we make a call to the database by the userFacingId to look up the externalId.
The disadvantage of the approach is that we’re making an extra (internal) network call to look up the ID but it’s the type of code that should be easily cacheable if it becomes a performance problem so it should be fine.
I think this approach is much better than having potentially flawed translation logic in the application.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.