
The read-only database
The last couple of applications I’ve worked on have had almost completely read only databases where we had to populate the database in an offline process and then provide various ways for users to access the data.
This creates an interesting situation with respect to how we should setup our development environment.
Our normal setup would probably have an individual version of that database on every development machine and we would populate and then truncate the database during various test scenarios.
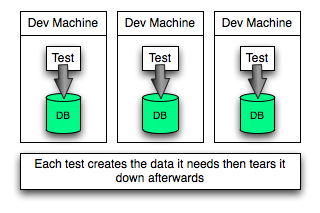
This actually means that our tests are interacting with the database in a different way than we would see during the running of the application.
It also means that we have more infrastructure to take care of and more software updates to do although using tools like Chef or Puppet can reduce the pain this causes once the initial setup of those scripts has been done.
On the project I worked on last year we started off with the individual database approach but eventually moved to having a shared database used by all the developers.
We only made the move once we had the real production data and the script which would populate that data into our database ready.
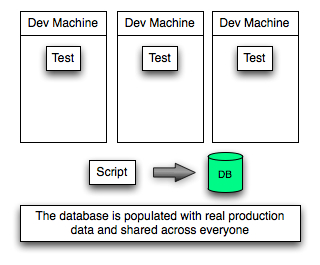
The disadvantage of having this shared database is that our tests become more indirect.
We wrote our tests against data which we knew would be in our production data set which meant if anything failed you had a bit more investigation to do since the data setup was done elsewhere.
On the other hand noone had to worry about getting it setup on their machines which had proved to be tricky to totally automate.
We have a similar situation on the application I’m currently working on and have noticed that we run into problems that don’t usually exist as a result of adding data to the database on each test.
For example in one test the database takes a bit of time to sort out its indexes which means that some tests intermittently fail.
We found a bit of a hacky way around this by forcing the database to reindex in the test and waiting until it has done so but we’ve now solved a problem which doesn’t actually exist in production.
This approach wouldn’t work as well if we had a read/write database since we’d end up with tests failing since another developer machine had mutated the data it relied on.
With a read only database it seems to be ok though.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.