
DDD: Repository pattern
The Repository pattern from Domain Driven Design is one of the cleanest ways I have come across for separating our domain objects from their persistence mechanism.
Until recently every single implementation I had seen of this pattern involved directly using a database as the persistence mechanism with the repository acting as a wrapper around the Object Relational Mapper (Hibernate/NHibernate).
Now I consider there to be two parts to the repository pattern:
-
The abstraction of the persistence mechanism away from our other code by virtue of the creation of repositories which can be interacted with to save, update and load domain objects.
-
The need for these repositories to only be available for aggregate roots in our domain and not for every single domain object. Access to other objects would be via the aggregate root which we could retrieve from one of the repositories.
This pattern can also be useful when we retrieve and store data via services which we have been doing recently. Of course eventually the data is stored in a database but much further up stream.
To start with we were doing that directly from our controllers but it became clear that although we weren’t interacting directly with a database the repository pattern would still probably be applicable.
The way we use it is pretty much the same as you would if it was abstracting an ORM:
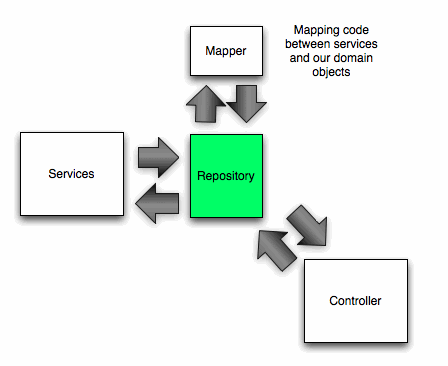
I think with an ORM the mapping would be done before you got the data back so that’s an implementation detail that is slightly different but as far as I can see the concept is the same.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.