
R: Scraping Neo4j release dates with rvest
As part of my log analysis I wanted to get the Neo4j release dates which are accessible from the release notes and decided to try out Hadley Wickham’s rvest scraping library which he released at the end of 2014.
rvest is based on Python’s beautifulsoup which has become my scraping library of choice so I didn’t find it too difficult to pick up.
To start with we need to download the release notes locally so we don’t have to go over the network when we’re doing our scraping:
download.file("http://neo4j.com/release-notes/page/1", "release-notes.html")
download.file("http://neo4j.com/release-notes/page/2", "release-notes2.html")We want to parse those pages back and return the rows which contain version numbers and release dates. The HTML looks like this:
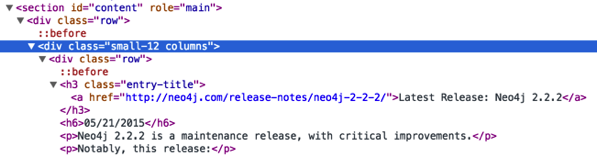
We can get the rows with the following code:
library(rvest)
library(dplyr)
page1 <- html("release-notes.html")
page2 <- html("release-notes2.html")
rows = c(page1 %>% html_nodes("div.small-12 div.row"),
page2 %>% html_nodes("div.small-12 div.row") )
> rows %>% head(1)
[[1]]
<div class="row"> <h3 class="entry-title"><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Latest Release: Neo4j 2.2.2</a></h3> <h6>05/21/2015</h6> <p>Neo4j 2.2.2 is a maintenance release, with critical improvements.</p>
<p>Notably, this release:</p>
<ul><li>Provides support for running Neo4j on Oracle and OpenJDK Java 8 runtimes</li> <li>Resolves an issue that prevented the Neo4j Browser from loading in the latest Chrome release (43.0.2357.65).</li> <li>Corrects the behavior of the <code>:sysinfo</code> (aka <code>:play sysinfo</code>) browser directive.</li> <li>Improves the <a href="http://neo4j.com/docs/2.2.2/import-tool.html">import tool</a> handling of values containing newlines, and adds support f...</li></ul><a href="http://neo4j.com/release-notes/neo4j-2-2-2/">Read full notes →</a> </div>Now we need to loop through the rows and pull out just the version and release date. I wrote the following function to do this and strip out any extra text that we’re not interested in:
generate_releases = function(rows) {
releases = data.frame()
for(row in rows) {
version = row %>% html_node("h3.entry-title")
date = row %>% html_node("h6")
if(!is.null(version) && !is.null(date)) {
version = version %>% html_text()
version = gsub("Latest Release: ", "", version)
version = gsub("Neo4j ", "", version)
releases = rbind(releases, data.frame(version = version, date = date %>% html_text()))
}
}
return(releases)
}
> generate_releases(rows)
version date
1 2.2.2 05/21/2015
2 2.2.1 04/14/2015
3 2.1.8 04/01/2015
4 2.2.0 03/25/2015
5 2.1.7 02/03/2015
6 2.1.6 11/25/2014
7 1.9.9 10/13/2014
8 2.1.5 09/30/2014
9 2.1.4 09/04/2014
10 2.1.3 07/28/2014
11 2.0.4 07/08/2014
12 1.9.8 06/19/2014
13 2.1.2 06/11/2014
14 2.0.3 04/30/2014
15 2.0.1 02/04/2014
16 2.0.2 04/15/2014
17 1.9.7 04/11/2014
18 1.9.6 02/03/2014
19 2.0 12/11/2013
20 1.9.5 11/11/2013
21 1.9.4 09/19/2013
22 1.9.3 08/30/2013
23 1.9.2 07/16/2013
24 1.9.1 06/24/2013
25 1.9 05/13/2013
26 1.8.3 //Finally I wanted to convert the 'date' column to be in R date format and get rid of the 1.8.3 row since it doesn’t contain a date. lubridate is my goto library for date manipulation in R so we’ll use that here:
library(lubridate)
> generate_releases(rows) %>%
mutate(date = mdy(date)) %>%
filter(!is.na(date))
version date
1 2.2.2 2015-05-21
2 2.2.1 2015-04-14
3 2.1.8 2015-04-01
4 2.2.0 2015-03-25
5 2.1.7 2015-02-03
6 2.1.6 2014-11-25
7 1.9.9 2014-10-13
8 2.1.5 2014-09-30
9 2.1.4 2014-09-04
10 2.1.3 2014-07-28
11 2.0.4 2014-07-08
12 1.9.8 2014-06-19
13 2.1.2 2014-06-11
14 2.0.3 2014-04-30
15 2.0.1 2014-02-04
16 2.0.2 2014-04-15
17 1.9.7 2014-04-11
18 1.9.6 2014-02-03
19 2.0 2013-12-11
20 1.9.5 2013-11-11
21 1.9.4 2013-09-19
22 1.9.3 2013-08-30
23 1.9.2 2013-07-16
24 1.9.1 2013-06-24
25 1.9 2013-05-13We could then easily see how many releases there were by year:
releasesByDate = generate_releases(rows) %>%
mutate(date = mdy(date)) %>%
filter(!is.na(date))
> releasesByDate %>% mutate(year = year(date)) %>% count(year)
Source: local data frame [3 x 2]
year n
1 2013 7
2 2014 13
3 2015 5Or by month:
> releasesByDate %>% mutate(month = month(date)) %>% count(month)
Source: local data frame [11 x 2]
month n
1 2 3
2 3 1
3 4 5
4 5 2
5 6 3
6 7 3
7 8 1
8 9 3
9 10 1
10 11 2
11 12 1Previous to this quick bit of hacking I’d always turned to Ruby or Python whenever I wanted to scrape a dataset but it looks like rvest makes R a decent option for this type of work now. Good times!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.