
Neo4j 2.0.0-M06: Applying Wes Freeman's Cypher Optimisation tricks
Wes has been teaching me some of his tricks for tuning Neo4j cypher queries over the last few weeks so I thought I should write up a few examples of the master’s advice in action.
I’ve created a mini benchmarking tool using Python’s timeit and numpy to run different queries multiple times and return the mean, min, max and 95th percentile times.
I’ve made my football data set available in case you want to follow along and we’ll start with a query to find the top goal scorers away from home.
A quick refresher of the model (created using Alistair’s arrows tool):
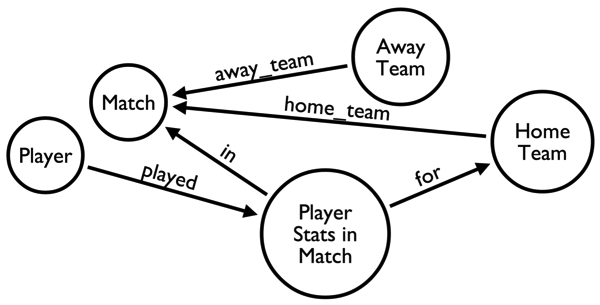
And the query in question:
MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
WHERE game<-[:away_team]-team
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10To run just that query in a 5 iteration loop 3 times we can wire up the benchmarking tool like this:
import query_profiler as qp
attempts = [
{"query": '''MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
WHERE game<-[:away_team]-team
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10'''}
]
qp.profile(attempts, iterations=5, runs=3)If we run that we’ll get the following output:
$ python top-away-scorers.py
MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
WHERE game<-[:away_team]-team
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10
Min 0.682677030563 Mean 0.689069747925 95% 0.697918820381 Max 0.699331998825Our average time per query run is therefore 0.689069747925 / 5 which is 0.137 seconds or 137 milliseconds so it isn’t that slow but there are still some tweaks we can make.
To refresh, Wes' 6 rules for cypher optimisation are:
-
Use parameters whenever you can
-
Avoid cartesian products when they aren’t required to get the data you need.
-
Avoid patterns in the WHERE clause
-
Start your MATCH patterns at the lowest cardinality identifier you can (ideally 1), and expand outward.
-
Separate your MATCH patterns, doing the minimal amount of expansion for each pattern. Add 1 new identifier per pattern.
-
Call for Wes!
The first rule we violate is #3 'Avoid patterns in the WHERE clause' which we can replace with a 'WITH MATCH' combination:
MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
WITH player, stats, team, game
MATCH team-[:away_team]->game
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10If we run that we get a 20% improvement:
$ python top-away-scorers.py
...
Min 0.549772977829 Mean 0.553097963333 95% 0.555728816986 Max 0.555970907211The next thing to look at is rule #4 'Start your MATCH patterns at the lowest cardinality identifier you can'. We can work out the cardinality of an identifier by prefixing the query with 'PROFILE' and analysing the output:
$ PROFILE MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
> WITH player, stats, team, game
> MATCH team-[:away_team]->game
> RETURN player.name, SUM(stats.goals) AS goals
> ORDER BY goals DESC
> LIMIT 10;
ColumnFilter(symKeys=["player.name", " INTERNAL_AGGREGATEab0a95e7-e701-4be3-9266-eb111c17b53c"], returnItemNames=["player.name", "goals"], _rows=10, _db_hits=0)
Top(orderBy=["SortItem(Cached( INTERNAL_AGGREGATEab0a95e7-e701-4be3-9266-eb111c17b53c of type Number),false)"], limit="Literal(10)", _rows=10, _db_hits=0)
EagerAggregation(keys=["Cached(player.name of type Any)"], aggregates=["( INTERNAL_AGGREGATEab0a95e7-e701-4be3-9266-eb111c17b53c,Sum(Product(stats,goals(13),true)))"], _rows=503, _db_hits=5192)
Extract(symKeys=["stats", "player", "team", " UNNAMED112", "game"], exprKeys=["player.name"], _rows=5192, _db_hits=5192)
PatternMatch(g="(team)-[' UNNAMED112']-(game)", _rows=5192, _db_hits=0)
ColumnFilter(symKeys=[" UNNAMED38", "stats", "player", "team", " UNNAMED21", "game", " UNNAMED57"], returnItemNames=["player", "stats", "team", "game"], _rows=10394, _db_hits=0)
PatternMatch(g="(stats)-[' UNNAMED38']-(game),(stats)-[' UNNAMED57']-(team),(player)-[' UNNAMED21']-(stats)", _rows=10394, _db_hits=0)
Filter(pred="hasLabel(player:Player(8))", _rows=523, _db_hits=0)
NodeByLabel(label="Player", identifier="player", _rows=523, _db_hits=0)The main thing to look at is the value of _rows. Here it starts at 523 (the number of nodes labelled with 'Player') and then explodes out to 10394 after evaluating the first MATCH expression. The second MATCH expression takes us back down to 5192 which gets further reduced to 503 after we group by player.
An alternative to starting our query from players is to start from games instead and a COUNT based query shows us that this will result in our query starting out with slightly less rows:
$ MATCH (game:Game) RETURN COUNT(game);
+-------------+
| COUNT(game) |
+-------------+
| 380 |
+-------------+
1 row
15 msThe rewritten query reads like this:
MATCH (game:Game)<-[:away_team]-(team)
WITH game, team
MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10If we benchmark that we get a 50% improvement:
$ python top-away-scorers.py
...
Min 0.276885986328 Mean 0.28545498848 95% 0.293333411217 Max 0.294231891632If we profile that query we see the following:
ColumnFilter(symKeys=["player.name", " INTERNAL_AGGREGATEa7d9d5ca-1f5f-4379-8675-9a01ca1f7ff0"], returnItemNames=["player.name", "goals"], _rows=10, _db_hits=0)
Top(orderBy=["SortItem(Cached( INTERNAL_AGGREGATEa7d9d5ca-1f5f-4379-8675-9a01ca1f7ff0 of type Number),false)"], limit="Literal(10)", _rows=10, _db_hits=0)
EagerAggregation(keys=["Cached(player.name of type Any)"], aggregates=["( INTERNAL_AGGREGATEa7d9d5ca-1f5f-4379-8675-9a01ca1f7ff0,Sum(Product(stats,goals(13),true)))"], _rows=503, _db_hits=5192)
Extract(symKeys=["stats", " UNNAMED93", " UNNAMED76", "player", "team", " UNNAMED112", "game"], exprKeys=["player.name"], _rows=5192, _db_hits=5192)
Filter(pred="hasLabel(player:Player(8))", _rows=5192, _db_hits=0)
PatternMatch(g="(player)-[' UNNAMED76']-(stats),(stats)-[' UNNAMED112']-(team),(stats)-[' UNNAMED93']-(game)", _rows=5192, _db_hits=0)
ColumnFilter(symKeys=["game", "team", " UNNAMED17"], returnItemNames=["game", "team"], _rows=380, _db_hits=0)
PatternMatch(g="(team)-[' UNNAMED17']-(game)", _rows=380, _db_hits=0)
Filter(pred="hasLabel(game:Game(7))", _rows=380, _db_hits=0)
NodeByLabel(label="Game", identifier="game", _rows=380, _db_hits=0)The maximum db_rows value we see here is 5192 so we didn’t have the explosion to 10394 which is probably responsible for the reduced execution time.
Another tweak could be to start with a 'label scan' of teams rather than games which yields a slight improvement:
$ python top-away-scorers.py
...
Min 0.255274057388 Mean 0.268081267675 95% 0.2759329319 Max 0.276294946671We could go even further and get rid of some of the 'stats' nodes which don’t have any goals and therefore don’t need to be used by our 'SUM' function:
MATCH (game)<-[:away_team]-(team:Team)
WITH game, team
MATCH (player:Player)-[:played]->stats-[:in]->game, stats-[:for]->team
WHERE stats.goals > 0
RETURN player.name, SUM(stats.goals) AS goals
ORDER BY goals DESC
LIMIT 10$ python top-away-scorers.py
...
Min 0.231870174408 Mean 0.236128012339 95% 0.240220928192 Max 0.240711927414If we have a look at the profile of that query...
ColumnFilter(symKeys=["player.name", " INTERNAL_AGGREGATE95b48f9b-b262-4383-9afd-6eb5a51004b1"], returnItemNames=["player.name", "goals"], _rows=10, _db_hits=0)
Top(orderBy=["SortItem(Cached( INTERNAL_AGGREGATE95b48f9b-b262-4383-9afd-6eb5a51004b1 of type Number),false)"], limit="Literal(10)", _rows=10, _db_hits=0)
EagerAggregation(keys=["Cached(player.name of type Any)"], aggregates=["( INTERNAL_AGGREGATE95b48f9b-b262-4383-9afd-6eb5a51004b1,Sum(Product(stats,goals(13),true)))"], _rows=180, _db_hits=394)
Extract(symKeys=["stats", " UNNAMED93", " UNNAMED76", "player", "team", " UNNAMED112", "game"], exprKeys=["player.name"], _rows=394, _db_hits=394)
Filter(pred="(Product(stats,goals(13),true) > Literal(0) AND hasLabel(player:Player(8)))", _rows=394, _db_hits=394)
PatternMatch(g="(player)-[' UNNAMED76']-(stats),(stats)-[' UNNAMED112']-(team),(stats)-[' UNNAMED93']-(game)", _rows=394, _db_hits=5192)
ColumnFilter(symKeys=["team", "game", " UNNAMED12"], returnItemNames=["game", "team"], _rows=380, _db_hits=0)
PatternMatch(g="(team)-[' UNNAMED12']-(game)", _rows=380, _db_hits=0)
Filter(pred="hasLabel(team:Team(2))", _rows=37, _db_hits=0)
NodeByLabel(label="Team", identifier="team", _rows=37, _db_hits=0)...we can see that the number of nodes that SUM had to deal with was reduced from 5192 to 394 which explains why using a WHERE to lookup a property is slightly cheaper in this case. If using a WHERE had reduced the number of nodes more marginally it wouldn’t be worthwhile.
Overall we’ve taken the time it takes for 5 runs of the query down from an average of 689 milliseconds to 236 milliseconds so thank you Wes!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.